









文章目录
1 动机
作为大型公司的统一数据平台,处理可能拥有的实时数据馈送
- 拥有高吞吐量支持大容量事件流
- 支持离线系统的数据积压
- 处理延迟交付才能处理更传统的消息传递用例
- 进行分区、分布式、实时处理
- 及其出现故障时保证容错性
更类似于数据库日志
2. 高吞吐量的设计思考
a.读写缓存的利用
kafka严重依赖文件系统来存储和缓存消息,而不是额外是额外实现复杂的存储层抽象,比如引入缓存和缓冲。
- 磁盘的快慢取决于使用的方式(线性读取的速度可以达到600M/m,随机写入的性能仅为100K/s)。
- 为了弥补随机写入的性能差异,现代操作系统使用主内存进行磁盘缓存,所有磁盘读写都会经过这个统一的缓存。这样就会导致数据会在操作系统页面缓存中复制,将所有内容存储两次。
- 对象内存开销非常高,通常会使存储的数据大小翻倍,而且垃圾收集变得越来越糟糕。
- 使用文件系统和页面缓存优于维护内存缓存或其他结构,可以使可用缓存翻倍,并且可能通过紧凑的内存来再次翻倍自己饿结构而不是单个对象。
与其在内存中保留尽可能多的内存并在我们用完空间时恐慌地将其全部刷新到系统,不如将其反转。所有数据都会立即写入文件系统上的持久日志中,而不必刷新到磁盘。
b. 顺序数据结构的妙处
kafka采用了追加写也就是顺序写的方式来完成数据持久化,消息投递过程中也是按照顺序读的方式实现的。好处:
- 避免B树等数据结构在数据增大时的性能下降
- 顺序读写,由于只需要一次磁盘定位,事件复杂度为O(1),性能会更加稳定。
c. 避免过多的小I/O操作
Kafka中的I/O操作主要是两个环节:客户端和服务端之间的网络IO,以及服务器内部持久化操作中的磁盘IO。kafka的整体设计里,大的思路就是降IO,增吞吐。
kafka设计上支持消息分批投递,并且在持久化存储上原样保存,最后也是按批交付给消费者,全程不会对此批数据进行分解或者合并,好处:
- 足够大的网络分包
- 足够大的磁盘顺序操作
- 毗邻的内存空间
消息分批异步发布是客户端SDK完成的功能,其可以配置在超过指定事件或操作指定消息量的情况下出发消息投递大broker,虽然牺牲一些投递时机的延迟,但是赢取了分批投递所带来的消息量的提升。
3.低延迟的设计思考
a.避免字节拷贝操作
为了降低延迟,broker最好是越少干预越好。为此kafka设计了统一的二进制消息格式,而且在消息投递的全过程中,都不需要修改消息内容,带来的好处是二进制消息无需经过broker的任何转化处理,原样落盘。而且消息原样落盘,可以方便结合零拷贝技术实现消息在网络的快速传递。特别是对于多消费者的场景消息直接从Page Cache读取,不用担心广播带来线性的访问开销。最后通过网络传输,理论上消息投递的速率可以逼近网络连接传输速率的上限。
b.端到端消息压缩
对消息体进行压缩,可以降低数据传输的体积。kafka使用了端到端的分批消息压缩协议。一般来说在同一个topic里,我们倾向于同类或者相似的消息类型,这些类型的消息会有大量重复的字段名,如果按批压缩,能够获得远比单条消息大的压缩率。由于是端到端解压,kafka broker也就无需考虑本身实际使用的压缩格式,这也符合上面说的二进制消息格式中,broker不参与消息转换的设计思想。
c.发布者的低延迟设计
发布者的低延迟设计主要是降低负载均衡的延迟。kafka采用了producer直连broker的设计,而不依赖其他任何中间的路由层,好处是直接高效,将少了路由环节,同时降低了系统的复杂度,无需考虑额外路由层的高可用问题。但是就是要求所有broker节点都能够火织集群的节点分布及每个分区的leader所在的节点信息,这些信息由Zookeeper管理。
消息投递由客户端也就是producer决定,支持轮训或者随机等简单的均衡算法,也支持按Keyhash的分区算法,在producer上完成。
d .消费者的低延迟设计
- 零拷贝技术的应用
- 批量拉取消息
4.可靠性的设计思考
a.有且仅有一次的消息投递语义
- 发布端:结合broker授予发布者的一个唯一的Id,结合消息本身隐含的顺序的序号可以方便broker识别重复投递的消息
- 消费端:消息拉取起点由消费者控制,所以只需要考虑消费者如何避免重复拉取就好了。官方建议:消费者将已消费的消息偏移量一同记录到消费者处理消息结果的输出中,这样可以保证消费者消费重启后,在开始拉取前确认最后的消费进度。
5. 高可用的设计思考
高可用:复制和容灾选主
- 复制:kafka的每个分区都可以配置0个或多个副本数量。follower使用和消费者一致的批量拉取机制来同步leader节点的日志
- 容灾选主:
- in-sync节点:
- 保持了到zookeeper的心跳
- 节点跟随leader的日志复制,没有明显落后leader节点的日志
- kafka放弃了大多数选举的分布式一致性的方案,而是采用了ISR的方案。传统的大多数选举为了容忍n次leader故障,必须部署2n+1个节点,而kafka需要存储大量数据,成本过大。而采用ISR的方案,只需要n+1个节点,就可以容忍n+1次故障,成本降低了接近一半。
- ISR方案下,所有节点返回确认成功消息才算被成功提交。但是如果所有in-sync节点都故障了,怎么选取新的leader:
- 牺牲可用新:等待in-sync机器恢复
- 牺牲一致性:任选一台可用机器作为leader,这个机器可能是in-sync,也可能不是。
- kafka会尽可能将所有分区的leader均匀分散到不同的broker上。
- in-sync节点:
6.其他设计思考
a.分段存储提升查找效率
kafka的topic会进一步分为多个分区,分区是最小的备份单元,但是分区日志在磁盘上还会进一步分解为多个段,也就是多个独立的文件。
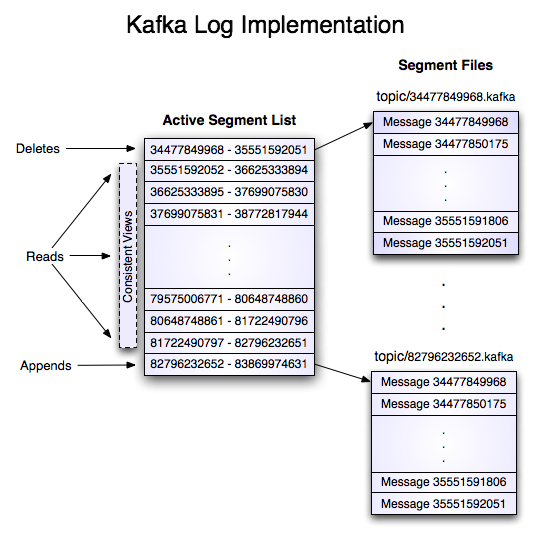
优点是可以结合二分查找算法,快速定位到指定的消息。(消息的日志是顺序存储的)
b.消息的进度标记-consumer offset
作为消息队列,broker需要记录消息被消费的状态。经典的思路是标记每个消息的状态:已投递、已确认,但是会有几个问题:
- 可能重复投递消息:消息未被正确确认,可能会被再次投递
- 额外的存储空间开销:每个消息都需要额外的空间用于标记消息
- 极端场景:大量消息发送后未被确认
kafka的做法:限定每个分区一个消费者。这样一来,由于一个分区只能被一个消费者消费,而且消息顺序投递,这样就可以用一个简单的整数表示一个消费者在一个分区上的消费进度,而不是记录每个消息的消费状态,这是一个O(1)的常量空间开销。
最后由于kafka由于保留了历史消息,配合前面说的分段存储和查找,所以可以方便地支持回退offset的场景,以便重放消息。
c.日志压缩
这里的日志压缩不同于前面提到的消息压缩,这里特指对日志进行合并重写,以只保留同个key的消息的最新版本。经过日志压缩后,保留下来的消息仍旧保持时序性不变,offset也不变,但是整个分区的offset不再连续
对消息队列作了不少的学习记录,后面打算学习记录操作系统的相关知识
















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









