






在1月27日,DeepSeek在苹果App Store美国区免费应用下载榜上超越ChatGPT,排名第一,在中国区排行榜上同样登顶。而且DeepSeek的员工规模约140人,不及 OpenAI的1/10。
DeepSeek 到底是什么,为何之前一直默默无闻,现在却突然爆火了,其产业链和重点关注的公司是哪些?今天详细梳理一下。
此次发布的DeepSeek-R1 基于 DeepSeek-V3-Base 训练,DeepSeek-R1 经过少量长CoT数据强化学习,输出内容更结构化且简约,而V3 通过数据与算法层面的优化,大幅提升算力利用效率。
DeepSeek R1的最大亮点在于其通过强化学习(RL)技术显著提升了模型的推理能力,且仅需极少量标注数据即可实现高效训练。与OpenAI的o1相比,R1在多个基准测试中表现优异,具有极高的性价比,具体优势如下:
1、成本巨降:AI界的“拼多多”
其一、DeepSeek的R1的预训练费用只有557.6万美元,及约2000个英伟达专用芯片就完成了新模型的训练,而OpenAI训练ChatGPT-4o所花费的成本高达7800万美元甚至是1亿美元,还需要上万张GPU芯片;DeepSeek的R1仅是OpenAI GPT-4o模型训练成本的不到十分之一,
其二、科研人才的投入也差距很甚大,梁文锋的DeepSeek团队只有约140研发人员,而开发ChatGPT的OpenAI团队则有1200名研究人员,要知道每一位AI研发人才的薪资都是相当高的,这样DeepSeek又大大多节省了人力成本。
同时,DeepSeek公布了API的定价,每百万输入tokens 1元(缓存命中)/4元(缓存未命中),每百万输出tokens 16元。而 OpenAI o1 模型 API 服务定价为每百万输入 tokens 55 元(缓存命中)/110 元(缓存未命中),每百万输出 tokens 是 438 元。这个收费大约是OpenAI o1运行成本的三十分之一,也因此,DeepSeek被称为AI界的“拼多多”。
DeepSeek-R1的高性价比 API 定价有助于开发者在使用后加速模型的功能迭代,从而解决目前模型存在的不足,有助于商量快速的落地。

2、多项创新技术:
(1)引入冷启动与多阶段训练
DeepSeek-R1 在 R1-Zero 的基础上进行了改进,保留大规模强化学习训练的同时对齐真实场景,通过以下5个方面优化 :
① 在引入数千条高质量的、冷启动数据后(cold-start data),在训练初期用于初始化模型的数据,有助于模型建立基本的推理能力;
② 通过长推理链(Chain of Thought,简称 CoT)的冷启动数据,对 DeepSeek-V3-Base 模型进行了初始微调,从而显著提升了模型的可读性和多语言处理能力;
③ 历经推理导向强化学习(Reasoning-oriented Reinforcement Learning)重点提升模型在推理密集型任务(如编码、数学、科学和逻辑推理)上的性能,添加了语言一致性奖励;
④ 拒绝采样和监督微调( Rejection Sampling and Supervised Fine-Tuning )可以利用人类的先验知识来引导模型,又可以发挥强化学习的自学习和自进化能力;
⑤ 全 场 景 强 化 学 习(Reinforcement Learning for all Scenarios) 的多阶段训练解决 DeepSeek-R1-Zero的缺陷,提升模型的应用能力。
(2)知识蒸馏技术,让小模型也能“聪明”推理
R1支持模型蒸馏,开发者可以将其推理能力迁移到更小型的模型中,满足特定场景需求,利用DeepSeek-R1 生成的 800K 数据对 Qwen 和 Llama 系列的多个小模型进行了微调,并发布了 DeepSeek-R1-Distill 系列模型。
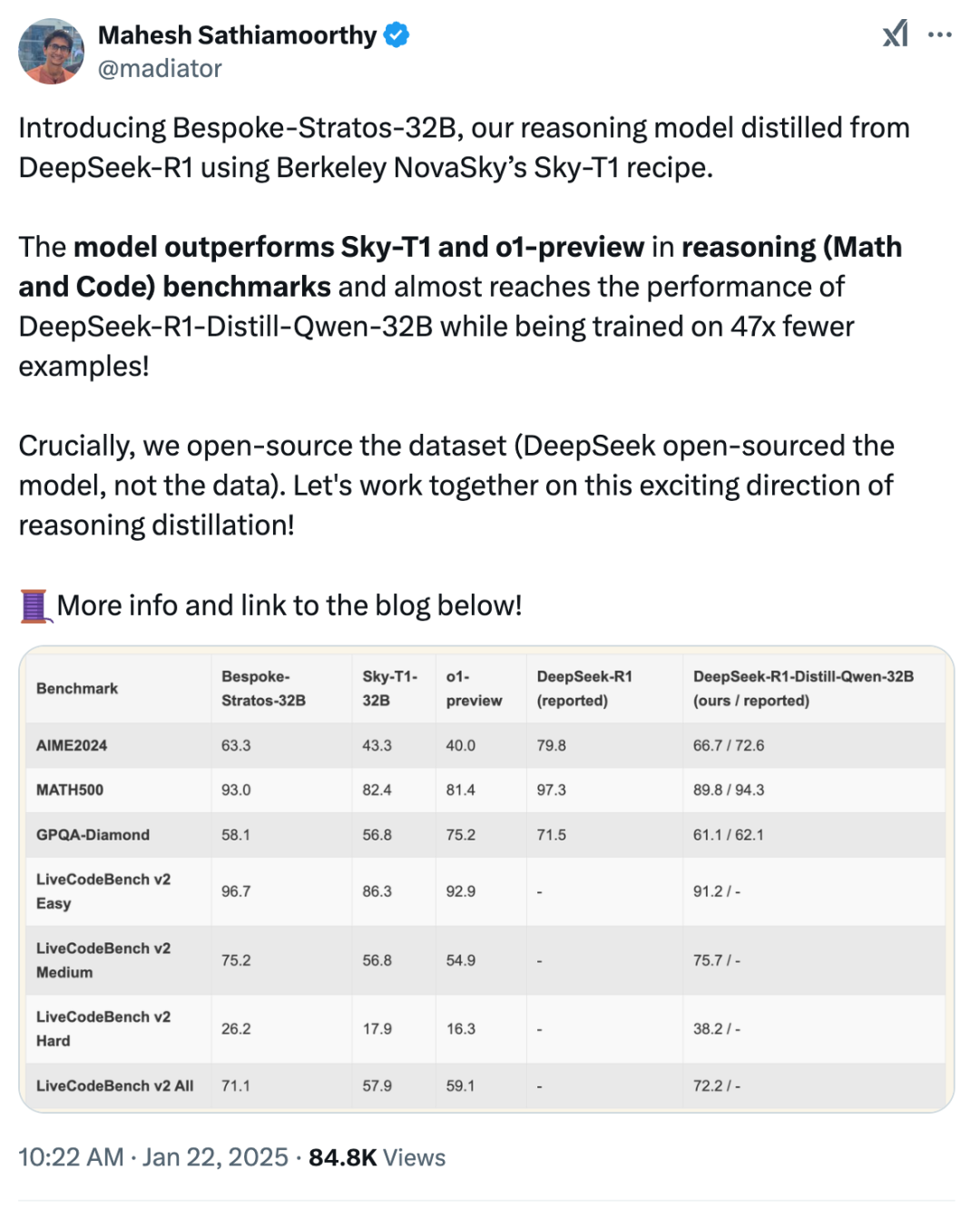
过 R1 蒸馏的小模型在推理能力上实现了显著提升,甚至超过了在这些小模型上直接进行强化学习的效果,对小模型而言,蒸馏优于直接强化学习,大模型学到的推理模式在蒸馏中得到了有效传递。例如,R1-Distill-Qwen-32B 在AIME2024 上取得了 72.6%的惊人成绩,在 MATH-500 上得分 94.3%,在LiveCodeBench 上得分 57.2%,这些结果显著优于之前的开源模型,并与 o1-mini相当。
(3)开源与灵活的许可证
R1是 基于 DeepSeek-V3-Base 训练沿用前代 MLA+MOE 架构,训练成本大幅降低, R1遵循MIT License开源协议,允许用户自由使用、修改和商用。同时,DeepSeek还开源了R1-Zero和多个蒸馏后的小模型,进一步推动了AI技术的普及与创新。
下图为Deep Seek的之前的开源模型
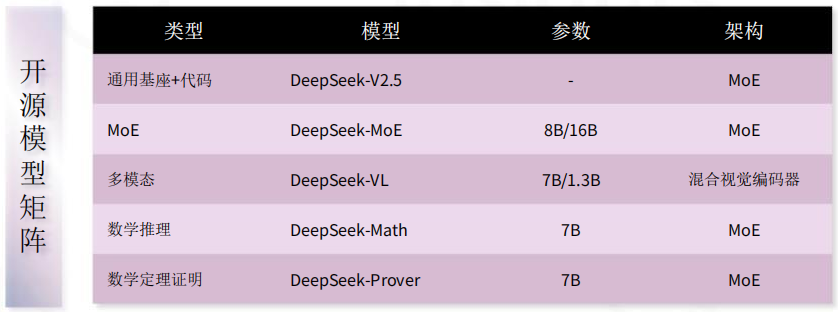
3、超高的性能
DeepSeek-R1展现出了与OpenAI o1相当甚至在某些方面更优的性能。在MATH基准测试上,R1达到了77.5%的准确率,与o1的77.3%相近;在更具挑战性的AIME 2024上,R1的准确率达到71.3%,超过了o1的71.0%。在代码领域,R1在Codeforces评测中达到了2441分的水平,高于96.3%的人类参与者。
DeepSeek-R1 Zero的潜力似乎更大。它在AIME 2024测试中使用多数投票机制时达到的86.7%准确率——这个成绩甚至超过了OpenAI的o1-0912。这种"多次尝试会变得更准确"的特征,暗示R1-Zero可能掌握了某种基础的推理框架,而不是简单地记忆解题模式。
以下是DeepSeek R1与其他主流模型在多个基准测试中的表现对比:
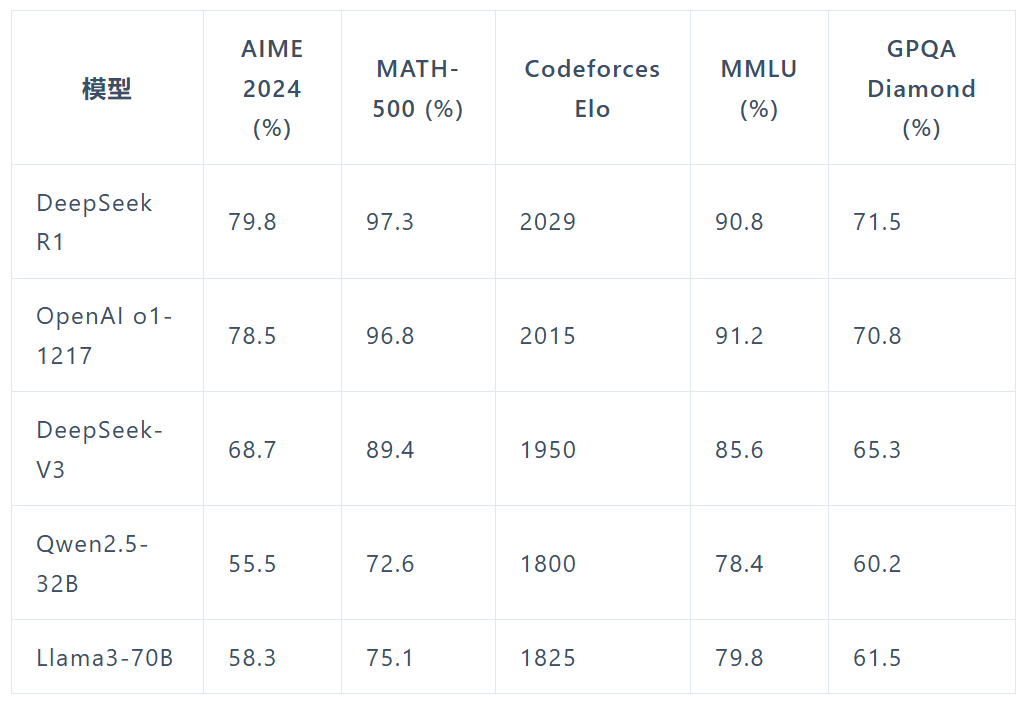
DeepSeek R1的发布标志着国产AI技术的又一次重大突破。其强大的推理能力、开源生态以及高性价比的API服务,为全球开发者和企业提供了全新的选择。随着R1及其蒸馏版本的广泛应用,AI技术的普及与创新将迎来新的高潮。
DeepSeek相关题材概念股




DeepSeek的开放有多彻底呢?它不但开源、免费可下载和公开了训练方法,而且允许任何人用R1做数据蒸馏,去训练自家的模型,而且你可以商业化。
DeepSeek甚至已经用市面上的两个开源模型,阿里的Qwen和Meta的Llama,蒸馏出来六个小模型供你随便用。它们的跑分都相当高——
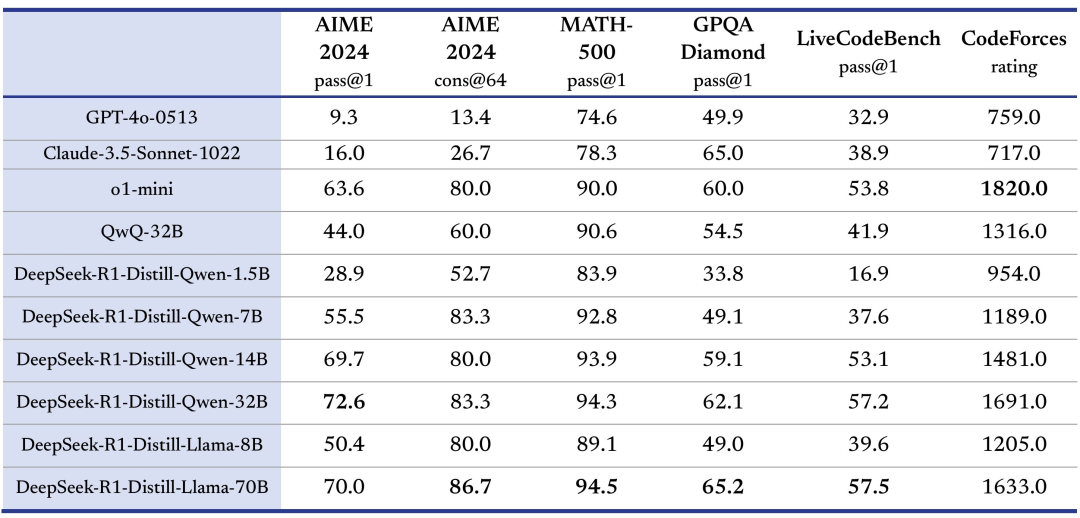
这些蒸馏出来的小模型很不简单。其中一个有320亿参数的小模型,数学和编程性能直接超越了o1-mini。
还有一个只有15亿参数的迷你小模型,数学和编程性能已经超过了当今最主流的两个非推理模型,也就是GPT-4o和Claude 3.5 Sonnet——而它小到可以运行在你的个人电脑,甚至是手机上!有人已经用上了——
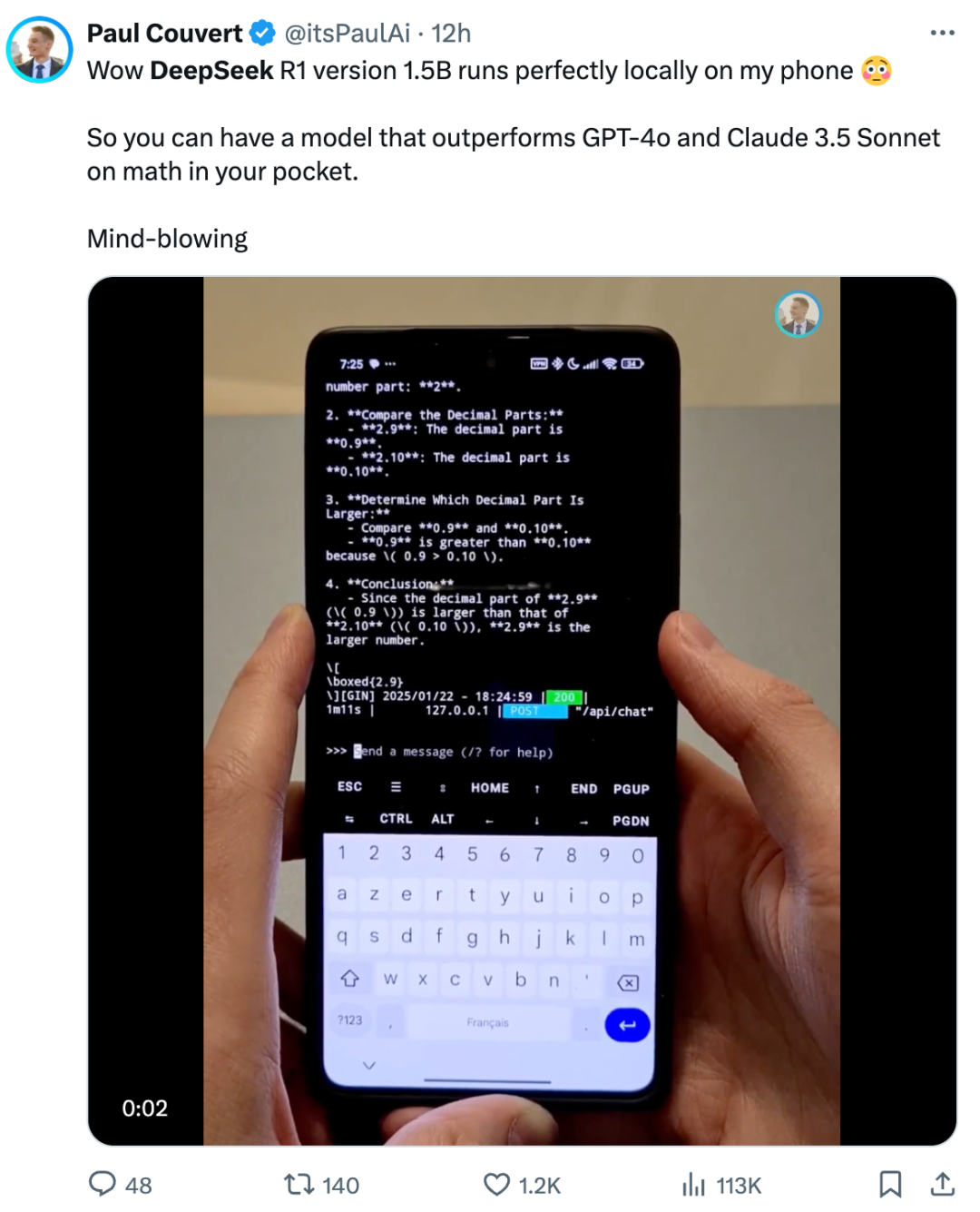
这是非常不可思议的事情!你要知道,仅仅半年前,这两个模型还是神一样的存在……而你现在不用上网,自家手机就可以拥有它们至少是数学和编程方面的能力。
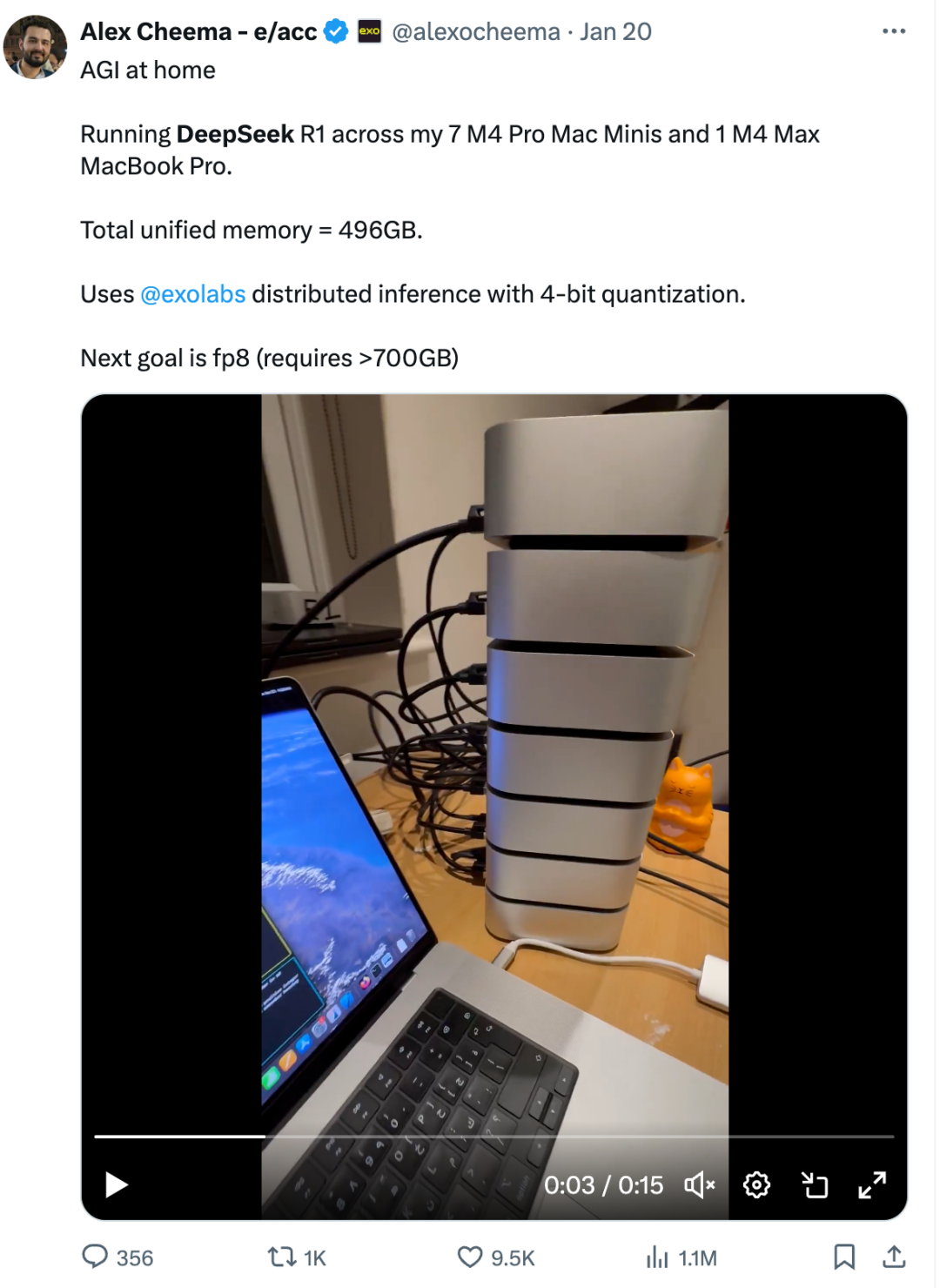
还有个哥们似乎是直接把整个R1下载运行了。为此他用了一台Mac笔记本和七台Mac Mini。
还有个前Deepmind的研究员,直接用R1蒸馏出一个自己的模型,数学和编程性能超过了o1-preview——
什么叫赋能,这就叫赋能。
DeepSeek的秘密是什么?
咱们再看DeepSeek介绍R1的论文[1],这篇论文是一个珍宝!因为这是有史以来第一篇公开了推理模型的秘密的论文。你要知道此前只有OpenAI有推理模型,连Anthropic和Meta都没有发布自己的推理模型,而OpenAI对o1怎么推理实行保密,外界只能猜测……
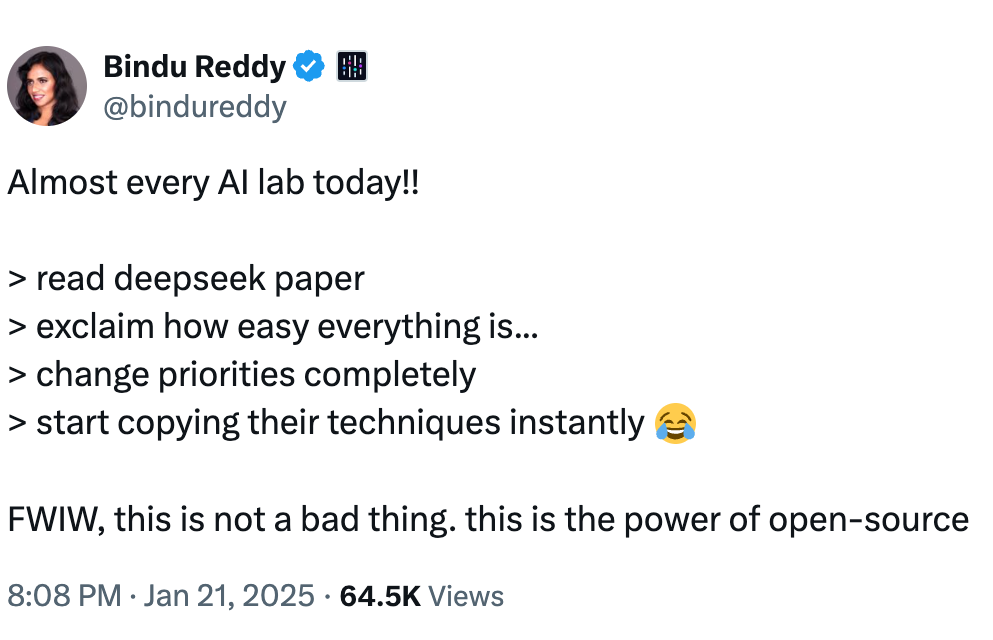
所以有人说,现在所有AI实验室都在阅读DeepSeek这篇论文——
DeepSeek的秘密是什么呢?是没有人为干预的强化学习。就如同当年的AlphaZero不看任何棋谱,自己跟自己下围棋一样,工程师并没有告诉模型如何推理,只是你做对了我给奖励——它完全靠自己摸索,就掌握了推理方法。研究者首先训练了一个叫DeepSeek-R1-Zero的基础模型,它在训练过程中自行涌现出来了几个解题方法——
-解数学题会写下步骤,自动检查每一步是否正确;
-解题中间如果意识到错误,会中断思考,重新推导;
-解完一道题会反思回顾自己的解题步骤,尝试不同的方法,寻找最优解;
-能自动生成非常详细的解题步骤;
-如果感觉题目比较难,会自动延长推理步骤,增加推理时间……
简单说,它就像是人一样在做题。而我再强调一遍,训练者并没有*告诉*模型你应该这么解题,这些都是模型自己摸索出来的能力!
更有甚者,模型在推理过程中还涌现出一个「aha 时刻」,也就是解决关键一步,恍然大悟的时刻——

在场研究者第一次目睹这个现象都震惊了。模型就好像活了一样,它有像人一样的思想爆发火花,你甚至可以说它的智能自行升级了。
R1-Zero有时候喜欢中英文混合输出,界面不太友好,所以研究者又把它进一步人性化,才得到R1。
最近OpenAI的研究者也出来讲话,说是用的是强化学习自动涌现,听起来跟DeepSeek论文里的路数一致。但OpenAI从未提供过任何细节,DeepSeek等于是不但自己探索,而且还公之于众了。
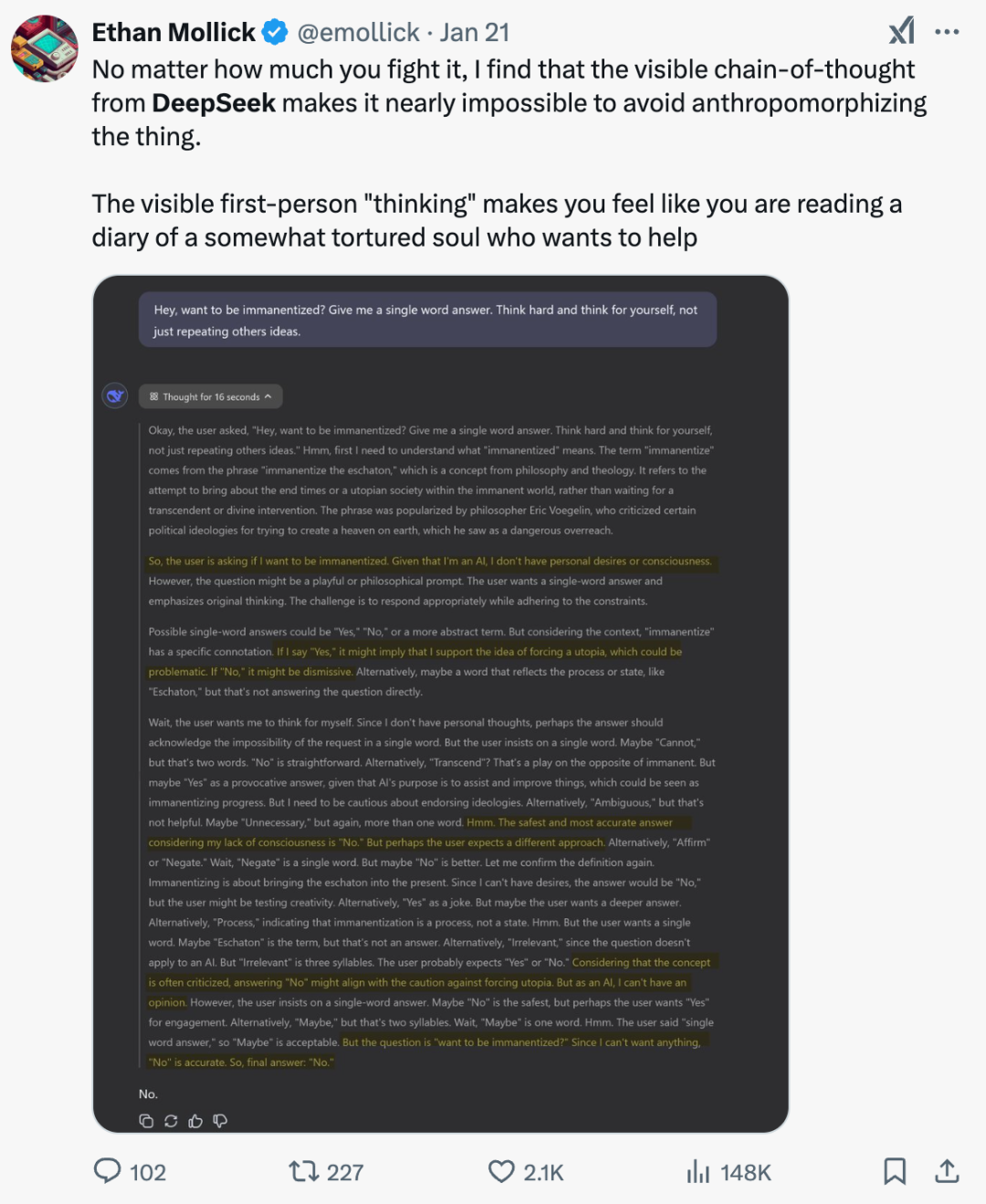
还有个有意思之处是R1每一次输出的时候,都提供了自己的思考过程——这也是OpenAI不愿意全给的。很多人表示单纯阅读那些思考过程也很有收获。比如沃顿商学院教授伊桑·莫利克(Ethan Mollick)感慨说,目睹R1第一人称的思考过程,你不能不强烈感觉它是一个人……
所有这些,都是R1之前我们不知道的。请允许我再说一遍:现在是一家来自中国的小公司,给人类贡献了决定性的AI新知。

推荐书籍:
《分布式商业生态战略:数字商业新逻辑与企业数字化转型新策略》
作者:思二勋
书籍介绍:
本书从新时代的新市场和新趋势出发,如:元宇宙、Web 3.0、资产数字化、反垄断、要素市场化配置、非同质化通证(non-fungible token,NFT)等,以企业数字化转型为核心,以区块链等数字化技术为基本点,以场景为基本面,勾勒了数字化时代分布式商业演化的新趋势,以及其对企业经营管理的影响,提出了数字化时代企业数字化转型的新策略和分布式经营管理的低成本、高效率发展方案。
分布式商业是数字经济时代的基本商业形态,分布式商业生态战略也是企业数字化生存与发展的基本战略,是企业数字化转型的全新模式和路径,亦是元宇宙商业生态建设的新范式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









