










过滤内容-Filter Contents
在上一节中,我们了解了可用于将结果从一个程序重定向到另一个程序进行处理的重定向。要读取文件,我们不一定需要使用编辑器。有两个工具称为more和less,它们非常相同。这些是pagers允许我们在交互式视图中滚动文件的基础。让我们看一些例子。
More
huaimeng@htb[/htb]$ more /etc/passwd当我们使用读取内容cat并将其重定向到后more,已经提到的内容pager将打开,我们将自动从文件的开头开始。
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
<SNIP>
--More--有了[Q]钥匙,我们就可以离开这个了pager。我们会注意到输出保留在终端中。
Less
如果我们现在看一下该工具less,我们会在手册页上注意到它包含的功能比more.
huaimeng@htb[/htb]$ less /etc/passwd演示文稿几乎与 相同more。
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
<SNIP>
:less当用键关闭时[Q],我们会注意到我们看到的输出与more 不同,不会保留在终端中。
Head
有时我们只对文件开头或结尾的特定问题感兴趣。如果我们只想获取文件的first行,我们可以使用该工具head。默认情况下,head如果没有另外指定,则打印给定文件或输入的前十行。
huaimeng@htb[/htb]$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologinTail
如果我们只想查看文件或结果的最后部分,我们可以使用headCalled的tail对应部分,它返回last十行。
huaimeng@htb[/htb]$ tail /etc/passwd
miredo:x:115:65534::/var/run/miredo:/usr/sbin/nologin
usbmux:x:116:46:usbmux daemon,,,:/var/lib/usbmux:/usr/sbin/nologin
rtkit:x:117:119:RealtimeKit,,,:/proc:/usr/sbin/nologin
nm-openvpn:x:118:120:NetworkManager OpenVPN,,,:/var/lib/openvpn/chroot:/usr/sbin/nologin
nm-openconnect:x:119:121:NetworkManager OpenConnect plugin,,,:/var/lib/NetworkManager:/usr/sbin/nologin
pulse:x:120:122:PulseAudio daemon,,,:/var/run/pulse:/usr/sbin/nologin
beef-xss:x:121:124::/var/lib/beef-xss:/usr/sbin/nologin
lightdm:x:122:125:Light Display Manager:/var/lib/lightdm:/bin/false
do-agent:x:998:998::/home/do-agent:/bin/false
user6:x:1000:1000:,,,:/home/user6:/bin/bashSort
根据处理的结果和文件,它们很少被排序。通常需要按字母或数字对所需结果进行排序,以获得更好的概览。为此,我们可以使用一个名为 的工具sort。
huaimeng@htb[/htb]$ cat /etc/passwd | sort
_apt:x:104:65534::/nonexistent:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
cry0l1t3:x:1001:1001::/home/cry0l1t3:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
dnsmasq:x:107:65534:dnsmasq,,,:/var/lib/misc:/usr/sbin/nologin
dovecot:x:114:117:Dovecot mail server,,,:/usr/lib/dovecot:/usr/sbin/nologin
dovenull:x:115:118:Dovecot login user,,,:/nonexistent:/usr/sbin/nologin
ftp:x:113:65534::/srv/ftp:/usr/sbin/nologin
games:x:5:60:games:/usr/games:/usr/sbin/nologin
gnats:x:41:41:Gnats Bug-Reporting System (admin):/var/lib/gnats:/usr/sbin/nologin
htb-student:x:1002:1002::/home/htb-student:/bin/bash
<SNIP>正如我们现在所看到的,输出不再以 root 开头,而是按字母顺序排序。
Grep
更常见的是,我们只会搜索包含我们定义的模式的特定结果。最常用的工具之一是grep,它提供了许多不同的功能。因此,我们可以搜索设置了默认 shell“/bin/bash ”的用户作为示例。
huaimeng@htb[/htb]$ cat /etc/passwd | grep "/bin/bash"
root:x:0:0:root:/root:/bin/bash
mrb3n:x:1000:1000:mrb3n:/home/mrb3n:/bin/bash
cry0l1t3:x:1001:1001::/home/cry0l1t3:/bin/bash
htb-student:x:1002:1002::/home/htb-student:/bin/bash另一种可能性是排除特定结果。为此,选项“ -v”与 一起使用grep。在下一个示例中,我们排除所有禁用了名为“ /bin/false”或“ /usr/bin/nologin”的标准 shell 的用户。
huaimeng@htb[/htb]$ cat /etc/passwd | grep -v "false\|nologin"
root:x:0:0:root:/root:/bin/bash
sync:x:4:65534:sync:/bin:/bin/sync
postgres:x:111:117:PostgreSQL administrator,,,:/var/lib/postgresql:/bin/bash
user6:x:1000:1000:,,,:/home/user6:/bin/bash
Cut
具有不同字符的特定结果可以作为分隔符分隔。在这里,了解如何删除特定分隔符并在行上的指定位置显示单词会很方便。可用于此目的的工具之一是cut. 因此,我们使用选项“ -d”并将分隔符设置为冒号字符(:),并使用选项“ -f”定义我们想要输出的行中的位置。
huaimeng@htb[/htb]$ cat /etc/passwd | grep -v "false\|nologin" | cut -d":" -f1
root
sync
mrb3n
cry0l1t3
htb-studentTr
用我们定义的字符替换一行中的某些字符的另一种可能性是工具tr。作为第一个选项,我们定义要替换的字符,作为第二个选项,我们定义要替换的字符。在下一个示例中,我们将冒号字符替换为空格。
huaimeng@htb[/htb]$ cat /etc/passwd | grep -v "false\|nologin" | tr ":" " "
root x 0 0 root /root /bin/bash
sync x 4 65534 sync /bin /bin/sync
mrb3n x 1000 1000 mrb3n /home/mrb3n /bin/bash
cry0l1t3 x 1001 1001 /home/cry0l1t3 /bin/bash
htb-student x 1002 1002 /home/htb-student /bin/bashColumn
由于搜索结果通常具有不明确的表示形式,因此该工具column非常适合使用“. -t”以表格形式显示此类结果。
huaimeng@htb[/htb]$ cat /etc/passwd | grep -v "false\|nologin" | tr ":" " " | column -t
root x 0 0 root /root /bin/bash
sync x 4 65534 sync /bin /bin/sync
mrb3n x 1000 1000 mrb3n /home/mrb3n /bin/bash
cry0l1t3 x 1001 1001 /home/cry0l1t3 /bin/bash
htb-student x 1002 1002 /home/htb-student /bin/bashawk
正如我们可能已经注意到的,用户“ postgres”的一行太多。为了尽可能简单地整理这些结果,( g)awk编程是有益的,它允许我们显示该行的第一个 ( $1) 和最后一个 ( $NF) 结果。
huaimeng@htb[/htb]$ cat /etc/passwd | grep -v "false\|nologin" | tr ":" " " | awk '{print $1, $NF}'
root /bin/bash
sync /bin/sync
mrb3n /bin/bash
cry0l1t3 /bin/bash
htb-student /bin/bashSed
有时我们想要更改整个文件或标准输入中的特定名称。我们可以使用的工具之一是名为 sed的流编辑器。最常见的用途之一是替换文本。在这里,sed查找我们以正则表达式 (regex) 形式定义的模式,并将其替换为我们也定义的另一个模式。让我们坚持最后的结果,并说我们想用“ HTB”替换单词“ bin”。
开头的“s ”标志代表替代命令。然后我们指定要替换的模式。在斜杠 ( /) 之后,我们在第三个位置输入要用作替换的模式。最后,我们使用“ g”标志,它代表替换所有匹配项。
huaimeng@htb[/htb]$ cat /etc/passwd | grep -v "false\|nologin" | tr ":" " " | awk '{print $1, $NF}' | sed 's/bin/HTB/g'
root /HTB/bash
sync /HTB/sync
mrb3n /HTB/bash
cry0l1t3 /HTB/bash
htb-student /HTB/bashWc
最后但并非最不重要的一点是,了解我们有多少场成功的比赛通常很有用。为了避免手动计算行数或字符数,我们可以使用该工具wc。使用“ -l”选项,我们指定仅计算行数。
huaimeng@htb[/htb]$ cat /etc/passwd | grep -v "false\|nologin" | tr ":" " " | awk '{print $1, $NF}' | wc -l
5实践
如果我们不熟悉这么多不同的工具及其功能,一开始可能会有点不知所措。花点时间尝试一下这些工具。查看手册页 ( man <tool>) 或调用帮助 ( <tool> -h/ <tool> --help)。熟悉所有工具的最佳方法是练习。尝试尽可能多地使用它们,我们将能够在短时间内直观地过滤很多东西。
这里有一些可选练习,我们可以用来提高我们的过滤技能并更加熟悉终端和命令。我们需要使用的文件是/etc/passwd我们的文件target,我们可以使用上面显示的任何命令。我们的目标是过滤并仅显示特定内容。读取文件并以我们只能看到的方式过滤其内容:
| 1. | 一行包含用户名cry0l1t3。 |
| 2. | 用户名。 |
| 3. | 用户名cry0l1t3和他的 UID。 |
| 4. | 用户名cry0l1t3和他的 UID 以逗号 ( ,) 分隔。 |
| 5. | 用户名cry0l1t3、他的 UID 和设置的 shell 以逗号 ( ,) 分隔。 |
| 6. | 所有用户名及其 UID 和设置外壳均以逗号 ( ,) 分隔。 |
| 7. | 所有用户名及其 UID 和设置外壳均以逗号 ( ) 分隔,并排除包含或 的,用户名。nologinfalse |
| 8. | 所有用户名及其 UID 和设置外壳均以逗号 ( ) 分隔,并排除包含并对过滤输出的所有行进行计数的,用户名。nologin |
开始实例
下载vpn配置,连接vpn
┌──(root㉿kali)-[~/桌面]
└─# openvpn academy-regular.ovpn 
通过ssh连接到目标主机
┌──(root㉿kali)-[~/桌面]
└─# ssh htb-student@10.129.71.206

提问区
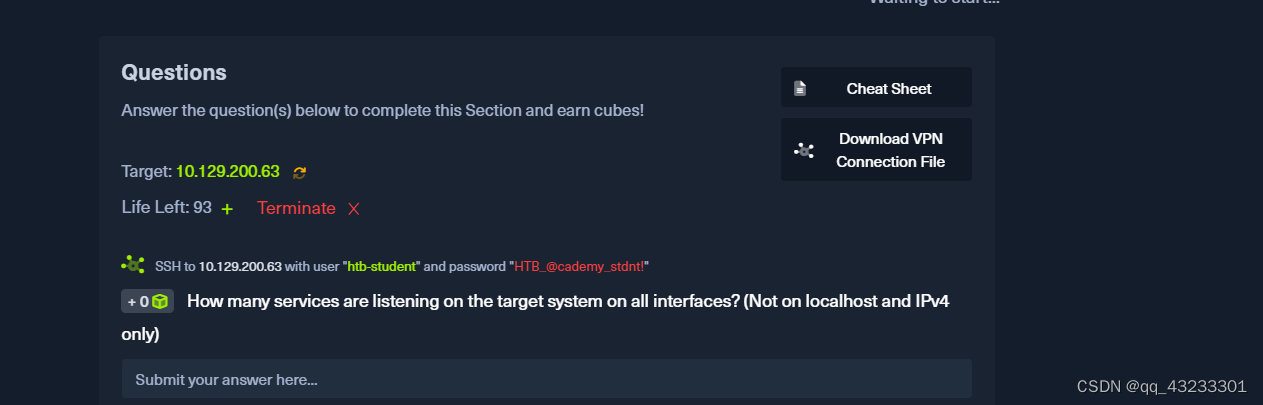
有多少服务正在通过所有接口侦听目标系统?(只查看IPv4但不适用于本地主机)
How many services are listening on the target system on all interfaces? (Not on localhost and IPv4 only)
htb-student@nixfund:~$ netstat -tulnp4|grep -v "127\.0\.0" |grep LISTEN |wc -l
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
7
-
netstat -tulnp4: 这部分命令使用netstat工具,列出了系统上的网络连接信息。具体参数的含义如下:-t: 仅显示TCP连接。-u: 仅显示UDP连接。-l: 仅显示监听状态的连接。-n: 不解析主机名和端口名,以数字形式显示IP地址和端口号。-p4: 仅显示IPv4地址的连接。
-
grep -v "127\.0\.0": 这一部分使用grep来过滤掉包含 "127.0.0" 的行,这样就排除了localhost的连接。 -
grep LISTEN: 这一部分进一步使用grep来筛选出包含 "LISTEN" 的行,这些行表示正在监听的连接。 -
wc -l: 最后,wc(word count)命令用于统计匹配的行数,从而得出监听在所有网络接口上的服务的数量。

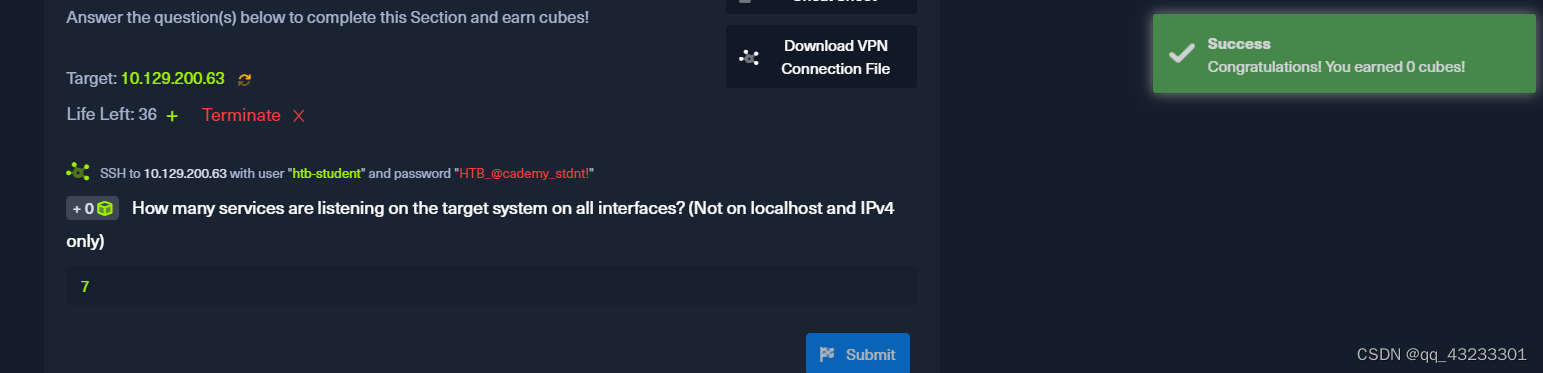
确定 ProFTPd 服务器在哪个用户下运行。提交用户名作为答案。
Determine what user the ProFTPd server is running under. Submit the username as the answer.
要确定 ProFTPd 服务器正在以哪个用户身份运行,您可以查看服务器的配置文件。通常,ProFTPd 的配置文件位于 /etc/proftpd/proftpd.conf。您可以查看配置文件以找到 User 指令,该指令指定了 ProFTPd 服务器运行的用户。
htb-student@nixfund:~$ cat /etc/proftpd/proftpd.conf | grep "User"
这将显示配置文件中指定用户的那一行。User 指令后面的用户名就是 ProFTPd 正在运行的用户。
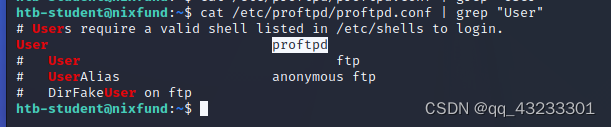

使用 Pwnbox(而非目标计算机)中的 cURL 获取“https://www.inlanefreight.com”网站的源代码并过滤该域的所有唯一路径。提交这些路径的数量作为答案。
Use cURL from your Pwnbox (not the target machine) to obtain the source code of the "https://www.inlanefreight.com" website and filter all unique paths of that domain. Submit the number of these paths as the answer.
curl https://www.inlanefreight.com | grep -Eo "https:\/\/.{0,3}\.inlanefreight\.com[^\"\']*" |sort -u |wc -l
这个命令用于获取 "https://www.inlanefreight.com" 网站的源代码,并筛选出所有唯一的以 "https://*.inlanefreight.com" 形式开头的链接的数量。
以下是这个命令的各个部分的解释:
-
curl https://www.inlanefreight.com:这部分使用curl命令来获取 "https://www.inlanefreight.com" 网站的源代码。 -
grep -Eo:这部分命令是用来进行文本匹配和筛选的。-E:这个选项告诉grep使用扩展正则表达式,允许使用更复杂的匹配模式。-o:这个选项告诉grep只输出匹配的部分,而不是整行。
-
"https:\/\/.{0,3}\.inlanefreight\.com[^\"\']*":这是用于匹配文本的正则表达式,它包含以下部分:https:\/\/:这部分匹配字符串 "https://",斜杠字符 "/" 需要用反斜杠转义。.{0,3}:这部分匹配 0 到 3 个任意字符。点号 "." 表示任意字符,花括号{0,3}表示匹配前面的字符 0 到 3 次。这是为了允许匹配 "https://*.inlanefreight.com" 形式的链接中的任何子域。例如,它可以匹配 "https://www.inlanefreight.com" 中的 "www"。\.inlanefreight\.com:这部分匹配 ".inlanefreight.com",其中点号字符 "." 需要用反斜杠转义。这部分用于匹配链接中的主域名。[^\"\']*:这部分匹配引号之外的字符。方括号 "[]" 表示字符集,而内部的^表示取反,所以[^\"\']表示匹配不是双引号或单引号的任何字符。这是为了确保匹配链接的结束。
-
sort -u:这部分对提取的链接进行排序,并去除重复项。 -
wc -l:最后,wc(word count)命令用于统计匹配的链接数量,从而得出以 "https://*.inlanefreight.com" 形式开头的唯一链接的数量。
这个命令的输出将是 "https://.inlanefreight.com" 形式开头的唯一链接的数量,您可以将这个数字作为答案提交。这些链接是网站上以 "https://.inlanefreight.com" 开头的唯一路径或子域。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









