






One-Hot编码
什么是one-hot编码
又称为独热编码或一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有独立的寄存器位,并且在任意时间,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如下
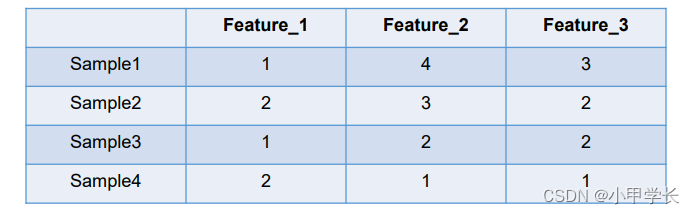
我们拿feature2来说明,这里的feature2有4种取值(状态),我们就用4个状态位来表示这个特征,one-hot编码就是保证每个样本中的单特征只有一位处于状态1,其他的都是0。
即:1->0001,2->0010,3->0100,4->1000
面对2种状态、3种状态甚至更多状态都可以这样表示,所以我们得到这些样本特征的新表示,如下
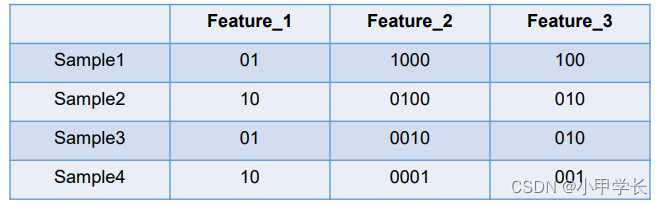
one-hot编码将每个状态位都看为看成一个特征。对于前两个样本我们可以得到它的特征向量分别为
Sample1—>[0,1,1,0,0,0,1,0,0]
Sample2—>[1,0,0,1,0,0,0,1,0]
one-hot在提取文本特征上的应用
one-hot在特征提取上属于词袋模型(bag of words)。关于如何使用one-hot抽取文本特征向量我们通过以下例子来说明。假设我们的语料库中有三段话:
我爱中国
爸爸妈妈爱我
爸爸妈妈爱中国
我们首先对语料库进行分词,并获取其中所有的词,然后对每个词进行编号:
1.我;2.爱;3.爸爸;4.妈妈;5.中国
如果不进行one-hot编码提取三句话的特征变量:
我爱中国----------------------> 1,2,5
妈妈爱我----------------------> 4,2,1
爸爸爱中国--------------------> 3,2,5
这种顺序编码最大的缺陷是强加一个顺序关系,具体来说,每个字之间并没有一个大小先后关系,而用数字顺序编号则强加了一个顺序关系,这是我们不希望看到的。
然后使用one-hot每段话提取特征向量:
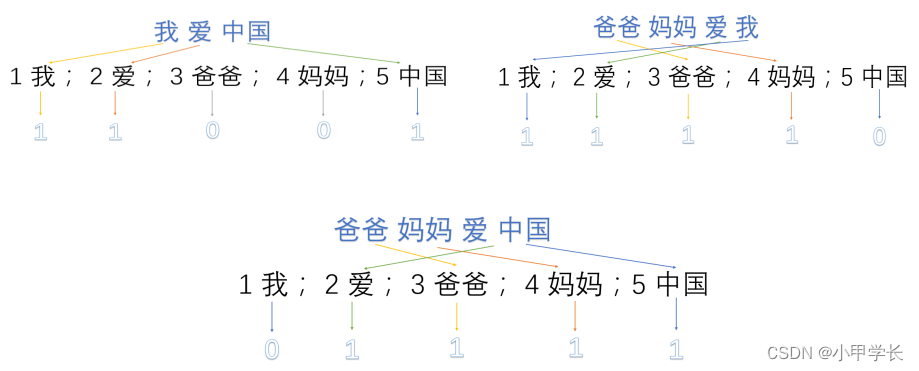
因此我们得到了最终的特征向量为
我爱中国----------------------> 1,1,0,0,1
爸爸妈妈爱我----------------------> 1,1,1,1,0
爸爸妈妈爱中国--------------------> 0,1,1,1,1
优缺点分析
优点:
一是解决了分类器不好处理离散数据的问题
二是在一定程度上也起到了扩充特征的作用(上面样本特征数从3扩展到了9)
缺点:
它是一个词袋模型,不考虑词与词之间的顺序
它假设词与词相互独立(在大多数情况下,词与词是相互影响的)
它得到的特征是离散稀疏的。
参考https://blog.csdn.net/qq_44795788/article/details/126451564















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









