







 本文介绍如何使用Apache Spark处理大规模日志数据,具体实现统计各省份广告点击次数的前三名。通过解析日志文件,按省份和广告进行聚合,最终输出每个省份点击次数最多的三个广告及其点击数。
本文介绍如何使用Apache Spark处理大规模日志数据,具体实现统计各省份广告点击次数的前三名。通过解析日志文件,按省份和广告进行聚合,最终输出每个省份点击次数最多的三个广告及其点击数。
1. 数据结构:时间戳,省份,城市,用户,广告,中间字段使用空格分割。
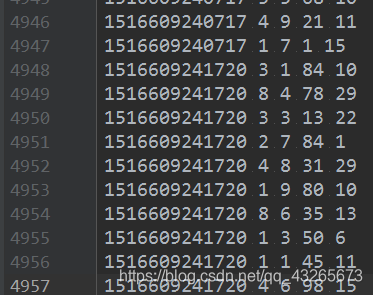
样本如下:
1516609143867 6 7 64 16
1516609143869 9 4 75 18
1516609143869 1 7 87 122. 需求:统计出每一个省份广告被点击次数的TOP3
3. 实现过程:
package practice
import org.apache.spark.{SparkConf, SparkContext}
/** 统计出每一个省份广告被点击次数的TOP3
* 数据结构:时间戳,省份,城市,用户,广告,中间字段使用空格分割。
* 日志样例:
* 1516609143867 6 7 64 16
* 1516609143869 9 4 75 18
* 1516609143869 1 7 87 12
*
* @author cherry
* @create 2019-09-16-18:11
*/
object Practice {
def main(args: Array[String]): Unit = {
//1.初始化spark配置信息并建立与spark的连接
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Practice")
val sc = new SparkContext(sparkConf)
//2.读取数据生成RDD:TS,Province,City,User,AD
val line = sc.textFile("Spark\\sparkWordCount20190915\\src\\main\\scala\\files\\agent.log")
//3.按照最小粒度聚合:((Province,AD),1)
val provinceAdToOne = line.map { x =>
val fields: Array[String] = x.split(" ")
((fields(1), fields(4)), 1)
}
//4.计算每个省中每个广告被点击的总数:((Province,AD),sum)
val provinceAdToSum = provinceAdToOne.reduceByKey(_ + _)
//5.将省份作为key,广告加点击数为value:(Province,(AD,sum))
val provinceToAdSum = provinceAdToSum.map(x => (x._1._1, (x._1._2, x._2)))
//6.将同一个省份的所有广告进行聚合(Province,List((AD1,sum1),(AD2,sum2)...))
val provinceGroup = provinceToAdSum.groupByKey()
//7.对同一个省份所有广告的集合进行排序并取前3条,排序规则为广告点击总数,如果需要按照省份ID排序,代码结尾可以添加".sortByKey()"
val provinceAdTop3 = provinceGroup.mapValues { x =>
x.toList.sortWith((x, y) => x._2 > y._2).take(3)
}
//8.将数据拉取到Driver端并打印
provinceAdTop3.collect().foreach(println)
//9.关闭与spark的连接
sc.stop()
}
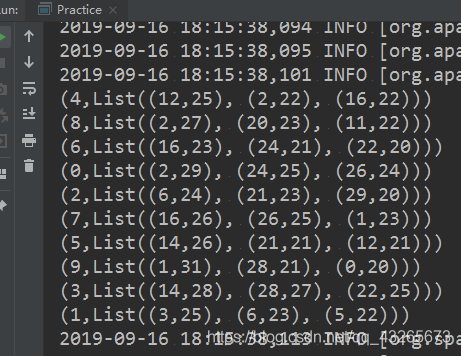
}打印结果:
(4,List((12,25), (2,22), (16,22)))
(8,List((2,27), (20,23), (11,22)))
(6,List((16,23), (24,21), (22,20)))
(0,List((2,29), (24,25), (26,24)))
(2,List((6,24), (21,23), (29,20)))
(7,List((16,26), (26,25), (1,23)))
(5,List((14,26), (21,21), (12,21)))
(9,List((1,31), (28,21), (0,20)))
(3,List((14,28), (28,27), (22,25)))
(1,List((3,25), (6,23), (5,22)))其中value的排序规则为广告点击总数

















 1998
1998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









