









贝叶斯算法实现预测(数据挖掘与分析)2.0
问题来源
使用贝叶斯算法实现以下问题:
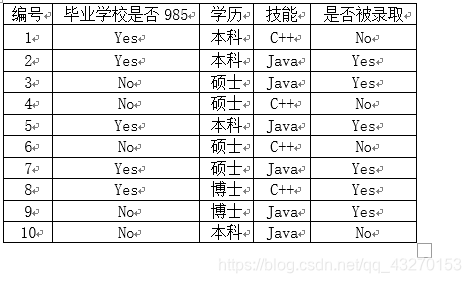
假设有一家小公司招收机器学习工程师,为了在更广泛的范围内筛选人才,他们写一些爬虫,去各个招聘平台、职场社交平台爬取简历,然后又写了一个简单的分类器筛选他们感兴趣的候选人。这个筛选分类器是朴素贝叶斯分类器,训练数据是现在公司里的机器学习工程师和之前来面试过这一职位,有被录取的人员的简历记录。全部数据集如下,请预测一位985硕士技能会C++的应聘者是否能录取?
代码部分
# -*- coding: utf-8 -*-
'''
1.5、算法应用流程
①、分解出先验数据中的各特征
(即分词,比如“985”“学历”“技能”)
②、计算各类别(录取、不录取)中,各特征的条件概率
比如 p(“Yes985”|录取),p(“No985”|录取)、
p(“本科”|录取),p(“硕士”|录取),p(“博士”|录取),
p(“C++”|录取),p(“Java”|录取)
③、分解出待分类样本的各特征
比如分解a: “Yes985” “硕士” “C++”
④、计算类别概率
P(录取) = p(录取|“Yes985”) *p(录取|“No985”)*
p(录取|“本科”)*p(录取|“硕士”)*p(录取|“博士”)*
p(录取|“C++”)*p(录取|“Java”)
P(不录取)=p(不录取|“Yes985”) *p(不录取|“No985”)*
p(不录取|“本科”)*p(不录取|“硕士”)*p(不录取|“博士”)*
p(不录取|“C++”)*p(不录取|“Java”)
⑤、显然P(录取)的结果值与P(不录取)进行比较,哪个大,则a被判别为 哪一个
'''
# 转置
def transpose(matrix):
new_matrix = []
for i in range(len(matrix[0])):
matrix1 = []
for j in range(len(matrix)):
matrix1.append(matrix[j][i])
new_matrix.append(matrix1)
return new_matrix
# 遍历
def bianli_(alist):
for i in range(len(alist)): # 控制行
for j in range(len(alist[i])): # 控制列
print(alist[i][j], end='\t')
print()
# 遍历行
def bianlihang(alist):
for i in range(len(alist)): # 控制行
print(alist[i])
# 计算概率
def rate_(a, b, c):
a.append(b.count(c) / len(b))
# 计算条件概率,加入blist[],p(word_1|word_2)
def conditional_rate(alist_T, blist, word_1, word_2):
for i in range(len(alist_T) - 1):
count_1 = 0
count_2 = 0
for j in range(len(alist_T[i])):
if alist_T[i][j] == word_1 and alist_T[3][j] == word_2:
count_1 += 1
# print('第 {} {} count_1:{}'.format(i, j, count_1))
if alist_T[3][j] == word_2:
count_2 += 1
# print('第 {} {} count_2:{}'.format(i, j, count_2))
x = count_1 / count_2
# print(x)
blist[i].append(x)
# 统计整理数据,分类
alist = [['Yes', '本科', 'C++', 'No'],
['Yes', '本科', 'Java', 'Yes'],
['No', '硕士', 'Java', 'Yes'],
['No', '硕士', 'C++', 'No'],
['Yes', '本科', 'Java', 'Yes'],
['No', '硕士', 'C++', 'No'],
['Yes', '硕士', 'Java', 'Yes'],
['Yes', '博士', 'C++', 'Yes'],
['No', '博士', 'Java', 'Yes'],
['No', '本科', 'Java', 'No']]
'''①特征分类----------------------------------------------------------'''
'''①、分解出先验数据中的各特征
(比如“985”“学历”“技能”)'''
alist_T = transpose(alist)
bianlihang(alist_T)
'''②计算各特征的条件概率----------------------------------------------------------'''
'''②、计算各类别(录取、不录取)中,各特征的条件概率
比如 p(“Yes985”|录取),p(“No985”|录取)、
p(“本科”|录取),p(“硕士”|录取),p(“博士”|录取),
p(“C++”|录取),p(“Java”|录取)
'''
base_list = [['Yes', 'No'], ['本科', '硕士', '博士'], ['C++', 'Java'], ['Yes', 'No']]
# 计算各特征的概率
rate = [[], [], [], []]
for i in range(len(rate)):
for j in range(3):
if (i == 0 or i == 2 or i == 3) and j == 2:
continue
else:
rate_(rate[i], alist_T[i], base_list[i][j])
print('计算各特征的概率:', rate)
'''③、分解出待分类样本的各特征
a: “Yes985” “硕士” “C++”
'''
'''计算概率----------------------------------------------------------'''
'''计算各类别(录取、不录取)中,各特征的条件概率
比如 p(“Yes985”|录取),p(“No985”|录取)、
p(“本科”|录取),p(“硕士”|录取),p(“博士”|录取),
p(“C++”|录取),p(“Java”|录取)'''
hanzi_list = [["p(“Yes985”|录取)", "p(“No985”|录取)"],
["p(“本科”|录取)", "p(“硕士”|录取)", "p(“博士”|录取)"],
["p(“C++”|录取)", "p(“Java”|录取)"]]
rate_2 = [[], [], []]
rate_2_ = [[], [], []]
for i in range(len(base_list) - 1):
for j in range(len(base_list[i])):
conditional_rate(alist_T, rate_2, base_list[i][j], 'Yes')# 计算类别录取
conditional_rate(alist_T, rate_2_, base_list[i][j], 'No')# 计算类别不录取
#删除列表中0.0的数据
x = 0.0
for i in range(len(rate_2)): # 控制行
while x in rate_2[i]:
rate_2[i].remove(x)
rate_2_[i].remove(x)
print('计算类别录取:', rate_2)
print('计算类别不录取:', rate_2_)
'''④计算类别概率----------------------------------------------------------'''
'''
④、计算类别概率
P(录取) = p(录取|“Yes985”) *p(录取|“No985”)*
p(录取|“本科”)*p(录取|“硕士”)*p(录取|“博士”)*
p(录取|“C++”)*p(录取|“Java”)
P(不录取)=p(不录取|“Yes985”) *p(不录取|“No985”)*
p(不录取|“本科”)*p(不录取|“硕士”)*p(不录取|“博士”)*
p(不录取|“C++”)*p(不录取|“Java”)
a: “Yes985” “硕士” “C++” '''
p1 = (1 / rate_2[0][0]) * (1 / rate_2[1][1]) * (1 / rate_2[2][0])
p2 = (1 / rate_2_[0][0]) * (1 / rate_2_[1][1]) * (1 / rate_2_[2][0])
'''⑤、显然P(录取)的结果值与P(不录取)进行比较,哪个大,则a被判别为 哪一个'''
if p1 > p2:
print("录取", p1, p2)
elif p1 < p2:
print("不录取", p1, p2)
else:
print("p1==p2", p1, p2)
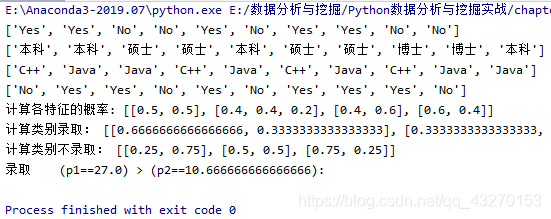
结果截图

放大点














 2142
2142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









