






对于多线程资源共享的问题,同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
ThreadLocal 并不能替代同步机制,两者面向的问题领域不同。
1:同步机制是为了同步多个线程对相同资源的并发访问,是为了多个线程之间进行通信的有效方式;
2:而threadLocal是隔离多个线程的数据共享,从根本上就不在多个线程之间共享变量,这样当然不需要对多个线程进行同步了。(每个线程有单独的数据,在线程内共享,在线程外独立)
最常见的ThreadLocal使用场景为用来解决数据库连接、Session管理等
private static ThreadLocal<Connection> connectionHolder =
new ThreadLocal<Connection>() {
protected Connection initialValue() {
return DriverManager.getConnection(DB_URL);
}
};
public static Connection getConnection() {
return connectionHolder.get();
}
JDK中建议ThreadLocal实例通常来说都是private static类型的.
每个ThreadLocal类创建一个Map,然后用线程的ID作为Map的key,实例对象作为Map的value,这样就能达到各个线程的值隔离的效果。JDK最早期的ThreadLocal就是这样设计的。
ThreadLocal底层实现
ThreadLocal类中有一个静态内部类ThreadLocalMap,ThreadLocalMap相当于一个哈希表,用private Entry[] table;存储数据,而Entry是一个实现了弱引用(下一次gc时就会被回收)的内部类,它的key弱引用。

ThreadLocalMap的初始大小为16,负载因子为2/3(即超过了长度的三分之二就要扩容),每次扩容为原来的2倍,可以保证大小始终为2的N次方。ThreadLocalMap解决哈希冲突的方法与hashmap不同(数组+链表),ThreadLocalMap如果i位置已经存储了对象,那么就往后挪一个位置依次类推,直到找到空的位置,再将对象存放。另外,在最后还需要判断一下当前的存储的对象个数是否已经超出了阈值(threshold的值)大小,如果超出了,需要重新扩充并将所有的对象重新计算位置(rehash函数来实现)。rehash函数里面先调用了expungeStaleEntries函数,然后再判断当前存储对象的大小是否超出了阈值的3/4。如果超出了,再扩容。看的有点混乱。为什么不直接扩容并重新摆放对象?为啥要搞成这么复杂?
其实,ThreadLocalMap里面存储的Entry对象本质上是一个WeakReference。也就是说,ThreadLocalMap里面存储的对象本质是一个对ThreadLocal对象的弱引用,该ThreadLocal随时可能会被回收!即导致ThreadLocalMap里面对应的Value的Key是null。我们需要把这样的Entry给清除掉,不要让它们占坑。
expungeStaleEntries函数就是做这样的清理工作,清理完后,实际存储的对象数量自然会减少。这时候再判断,如果存储对象数量还是过多,才会扩容(resize)
ThreadLocalMap中根据key值获得entry对象的方法是,得到table中的位置i(根据len-1,低位掩码),如果没找到,则有可能发生哈希冲突,所以调用getEntryAfterMiss函数从当前位置继续向后找。

threadLocalHashCode方法就是在ThreadLocal中定义了一个static的atomicInteger,每次调用threadLocalHashCode方法都要给它加上一个固定的值(不知道为什么)
ThreadLocal的get方法。
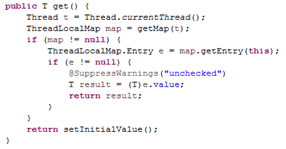
也就是说,每个线程中内部都有一个ThreadLocalMap类型的threadLocals,
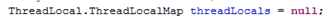
在调用ThreadLocal类的get方法时,先获得当前线程中存储的threadLocals(是一个map),如果该map为空,则调用setInitialValue(给当前线程的map new一个ThreadLocalMap, 传入initialValue方法的初值(没重写的话为null)),并返回该初值。如果有map的话,就map.getEntry(this),注意这里的key是this,也就是该ThreadLocal类。
ThreadLocal的set方法

注意,因为这里set的key是this(ThreadLocal类),所以每一个线程在每一个ThreadLocal中只能对应一个value。若想保存多个value,则需要创建多个ThreadLocal类。
总结:每一个Thread内部都封装了一个ThreadLocalMap,这个map的key是ThreadLocal(map.getEntry(this)),value是具体的变量对象。也就是说,一个thread可以保存多个threadlocal,而正因为threadlocal保存在thread内部,多线程并发时,每次处理的都是自己内部的数据。
流程:新建一个ThreadLocal类(名叫tl),重写它的initialValue方法,当一个线程调用tl的get方法时(此时进入tl类内部),先获得调用get方法线程保存的map,用map.getEntry(this)获得对应的变量对象(因为调用的是tl的get方法,所以this指针为这个tl)
与早期JDK中设计的区别
1这样设计之后每个Map的Entry数量变小了:之前是Thread的数量,现在是ThreadLocal的数量,能提高性能,据说性能的提升不是一点两点(没有亲测)
2当Thread销毁之后对应的ThreadLocalMap也就随之销毁了,能减少内存使用量。
弱引用
threadlocal里面使用了一个存在弱引用的map,当释放掉threadlocal的强引用以后,map里面的value却没有被回收.而这块value永远不会被访问到了. 所以存在着内存泄露. 最好的做法是将调用threadlocal的remove方法.
比如ThreadLocal tl = new ThreadLocal();当tl=null时,即释放了强引用,此时这个ThreadLocal会被gc掉,每个线程中ThreadLocalMap的key(key为threadlocal),如果key为强引用,则这个ThreadLocal不会被gc,就会发生我已经不想要这个ThreadLocal了,但还没被gc。所以为弱引用。value是我threadlocal中initial出来的
当把threadlocal实例置为null以后,没有任何强引用指向threadlocal实例,所以threadlocal将会被gc回收. 但是,我们的value却不能回收,因为存在一条从current thread连接过来的强引用. 只有当前thread结束以后, current thread就不会存在栈中,强引用断开, Current Thread, Map, value将全部被GC回收.
所以得出一个结论就是只要这个线程对象被gc回收,就不会出现内存泄露,但在threadLocal设为null和线程结束这段时间不会被回收的,就发生了我们认为的内存泄露。其实这是一个对概念理解的不一致,也没什么好争论的。最要命的是线程对象不被回收的情况,这就发生了真正意义上的内存泄露。比如使用线程池的时候,线程结束是不会销毁的,会再次使用的。就可能出现内存泄露。
PS.Java为了最小化减少内存泄露的可能性和影响,在ThreadLocal的get,set的时候都会清除线程Map里所有key为null的value。所以最怕的情况就是,threadLocal对象设null了,开始发生“内存泄露”,然后使用线程池,这个线程结束,线程放回线程池中不销毁,这个线程一直不被使用,或者分配使用了又不再调用get,set方法,那么这个期间就会发生真正的内存泄露。














 214
214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









