







目录
项目十:行程和用户(难度:困难)
- Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
- Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。

任务:
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。

解析:
题目意思本身很简单,难点在于如何同时计算取消的数量和总数量。 总数量很简单,就是COUNT(*), 同时计算取消数量可以用SUM(CASE END)来实现。对status列计算数量,如果是cancel就记1,complete记为0.
P.S. 如果需要userID 匹配 clientID和driverID两列,需要写两个Lef Join。 但是可以通过CASE ...END 在最终结果只显示一列。
代码:
-- 创建Trips表
CREATE TABLE Trips(
id INT PRIMARY KEY,
Client_id INT,
Driver_id INT,
City_id INT,
Status ENUM('completed','cancelled_by_driver','cancelled_by_client'),
Request_at VARCHAR(50)
);
-- 插入数据
INSERT INTO Trips VALUES ('1', '1', '10', '1', 'completed', '2013-10-01');
INSERT INTO Trips VALUES ('2', '2', '11', '1', 'cancelled_by_driver', '2013-10-01');
INSERT INTO Trips VALUES ('3', '3', '12', '6', 'completed', '2013-10-01');
INSERT INTO Trips VALUES ('4', '4', '13', '6', 'cancelled_by_client', '2013-10-01');
INSERT INTO Trips VALUES ('5', '1', '10', '1', 'completed', '2013-10-02');
INSERT INTO Trips VALUES ('6', '2', '11', '6', 'completed', '2013-10-02');
INSERT INTO Trips VALUES ('7', '3', '12', '6', 'completed', '2013-10-02');
INSERT INTO Trips VALUES ('8', '2', '12', '12', 'completed', '2013-10-03');
INSERT INTO Trips VALUES ('9', '3', '10', '12', 'completed', '2013-10-03');
INSERT INTO Trips VALUES ('10', '4', '13', '12', 'cancelled_by_driver', '2013-10-03');
-- 查看Trips表
SELECT * FROM Trips;
-- 创建Users表
CREATE TABLE Users(
Users_id INT PRIMARY KEY,
Banned varchar(20),
Role ENUM('client','driver','partner')
);
-- 插入数据
INSERT INTO Users VALUES ('1', 'No', 'client');
INSERT INTO Users VALUES ('2', 'Yes', 'client');
INSERT INTO Users VALUES ('3', 'No', 'client');
INSERT INTO Users VALUES ('4', 'No', 'client');
INSERT INTO Users VALUES ('10', 'No', 'driver');
INSERT INTO Users VALUES ('11', 'No', 'driver');
INSERT INTO Users VALUES ('12', 'No', 'driver');
INSERT INTO Users VALUES ('13', 'No', 'driver');
-- 查看Users表
SELECT * FROM users;
-- 解答
SELECT t.Request_at AS Day,
ROUND(sum((CASE WHEN t.Status LIKE 'cancelled%' THEN 1 ELSE 0 END))/count(*),2) AS 'Cancellation Rate'
-- 如果是取消的就为1,否则为0,sum求和后除以当天的总单数,即为取消率。Round函数用来保留两位小数。
FROM Trips t
INNER JOIN Users u ON u.Users_Id =t.Client_Id AND u.Banned = 'No' -- 连接两张表
--或者可以使用这种方法
--WHERE Client_Id NOT IN (SELECT Users_Id FROM Users WHERE Banned = 'YES')
GROUP BY t.Request_at; -- 以订单时间分组
项目十一:各部门前3高工资的员工(难度:中等)
将前一个项目中employee表清空,重新插入以下数据,编写一个 SQL 查询,找出每个部门工资前三高的员工。

解析:
和昨天分数排名的思想类似,用到了辅助表。 emp1是我们的基础表,emp2是辅助表。 将emp1里的每个salary和整张emp2比较。下面来捋下过程。
以IT部门为例,emp1的salary有 6.9万,7万,8.5万,9万四个数
① emp1工资是6.9万的时候,emp2表里的 count是3,说明有三个大于它的(间接说明它是第四大)
② emp1工资是7万的时候,emp2表里的count是2,说明有两个大于它的(间接说明它是第三大)
③emp1工资是8.5万的时候,emp2表里的count是1,说明有1个大于它的(间接说明它是第二大)
④emp1工资是9万的时候,emp2表里的count是0,说明没有大于它的(间接说明它是最大的)
在code里就是emp2.Salary > (emp1.Salary =6.9) 然后我们要求的是前三大,所以是COUNT() < 3。
代码:
TRUNCATE TABLE Employee; -- 清除数据
-- 插入数据
INSERT INTO employee VALUES (1,'Joe',70000,1);
INSERT INTO employee VALUES (2,'Henry',80000,2);
INSERT INTO employee VALUES (3,'Sam',60000,2);
INSERT INTO employee VALUES (4,'Max',90000,1);
INSERT INTO employee VALUES (5,'Janet',69000,1);
INSERT INTO employee VALUES (6,'Randy',85000,1);
SELECT *FROM employee
SET @limit_n = 3; -- 定义变量,筛选各部门前N个工资最高的人
SELECT
d. NAME Department,
e. NAME Employee,
e.Salary
FROM
Employee e
INNER JOIN Department d ON e.DepartmentId = d.ID
WHERE
(
SELECT
COUNT(1)
FROM
Employee e2
WHERE
e2.DepartmentID = d.ID
AND e2.Salary > e.Salary
) < @limit_n
ORDER BY Department DESC; -- 排序
项目十二:分数排名(难度:中等)
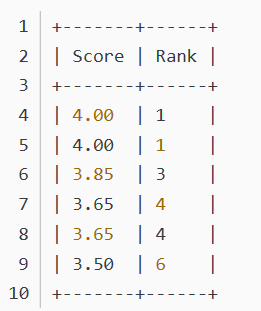
依然是昨天的分数表,实现排名功能,但是排名是非连续的,如下:

解析:
因为需要不连续的,所以count(*)取表中总记录数即可,之后统计多少个人比这个分数高,对结果+1后即为排名。因为比如对于最高分,没有人比他高,所以结果是0,排名需要+1才可以。并且使用format函数可以对结果强制保留几位小数输出。
代码:
SELECT FORMAT(Score,2),
(SELECT count(*) FROM Score AS s2 WHERE s2.Score > s1.Score)+1 AS Rank
FROM Score AS s1
ORDER BY Score DESC;















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









