







重构的类型、收益和度量
Hi,我是阿昌,今天学习记录的是关于重构的类型、收益和度量的内容。
到底什么是重构?
经常有产品、测试、项目等同学对他提代码重构的需求,比如后面这些情况。
测试同学说:今天的版本测试又发现了内存泄露,重构一下代码吧。产品同学说:这个界面的用户路径操作太深了,重构一下代码吧。项目同学说:我们的线上 Bug 很多,质量太差了,重构一下代码吧。
乍一听可能会觉得这些同学说的好像也没错,但是仔细一琢磨,就会发现这里面其实包含了性能优化、需求优化、缺陷优化等诸多内容,这些都算代码重构吗?另外,重命名一个方法、提取一个接口、单体架构组件化,这些又算是重构吗?它们之间有什么区别呢?
一、重构的类型和时机
重构的定义,在《重构:改善既有代码的设计(第 2 版)》中写道:
重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
注意,定义中提到“重构是不改变软件的可观察行为”,所以基于这一点,开头提到的需求优化、缺陷修复、性能优化等维度的代码调整都不属于重构。它们应该属于新需求、专项优化和软件缺陷修复等范围。
基于上述重构的定义,再来看看下面三种代码调整。
- 重命名一个变量,使其具有更好的
可读性。 - 对 A 类和 B 类抽取公共接口 C,将对 A 类和 B 类的依赖调整为对接口 C 的依赖,与具体的实现
解耦。 - 将大泥球的项目工程调整至
组件化工程。
这些调整是否属于重构?基于前面的定义,它们都属于重构的范畴。
但可能会发现,这三种代码调整所影响的范围,或者说涉及的工作量又是不同的。
其实,基于实际调整代码时所需的工作量和影响范围,可以将重构细分为三种类型:小型重构、中型重构和大型重构。
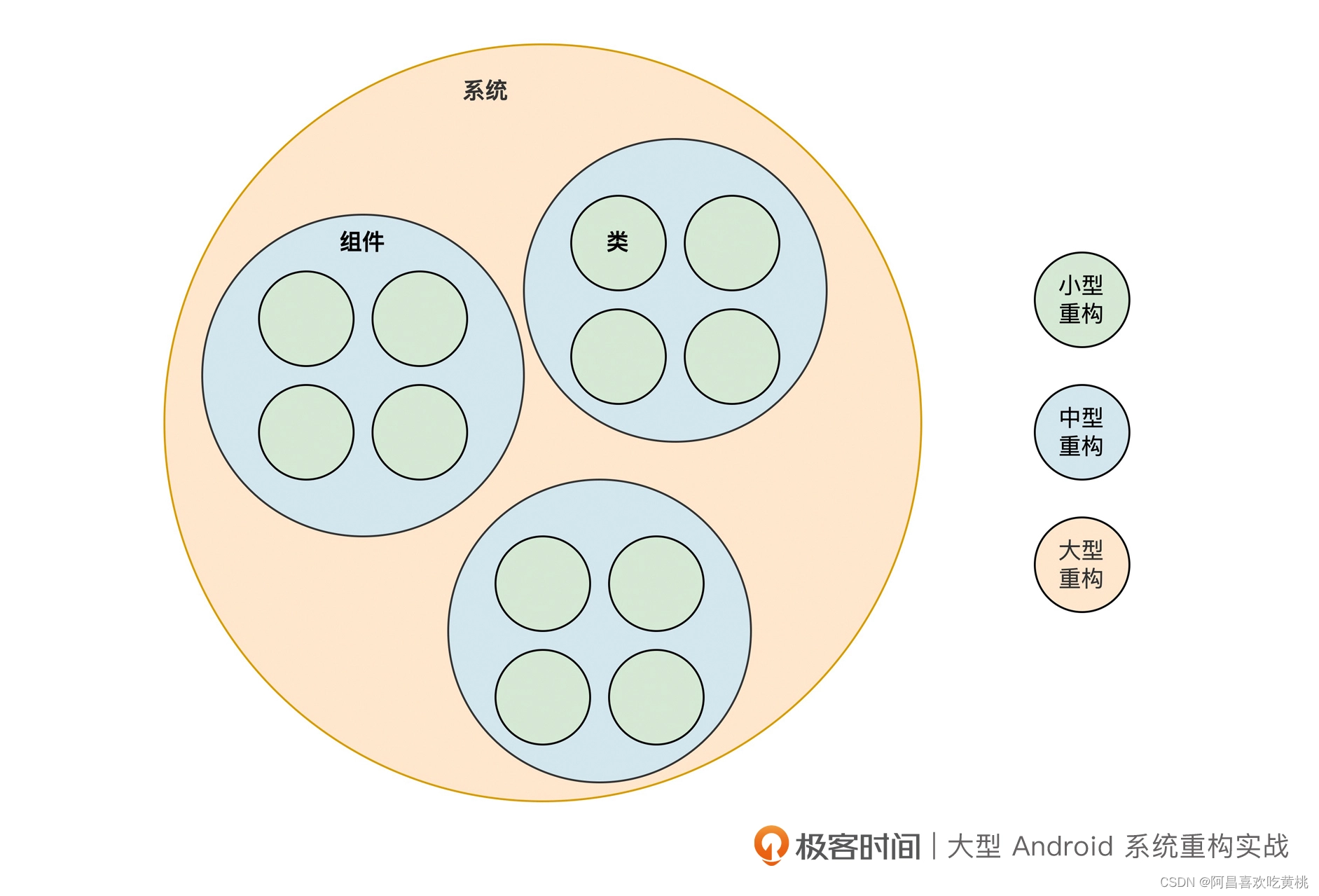
二、小型重构
小型重构是指对单个类内部的重构优化。
通常包括对方法名称、方法参数数量、方法大小等内容的修改,下面给举几个常见的小型重构例子。
- 优化命名,使其更有含义。
//重构前
Category getCategory(long catID)
//重构后
Category getCategory(int categoryId);
通过对命名优化,可以避免缩写带来的混淆,让代码的可理解性更高。
- 引入一些解释性的变量。
//重构前
if ((platform.toUpperCase().indexOf("Android") > -1) &&
(browser.toUpperCase().indexOf("Chrome") > -1))
{
//... ...
}
//重构后
boolean isAndroid = platform.toUpperCase().indexOf("Android") > -1;
boolean isChromeBrowser = browser.toUpperCase().indexOf("Chrome") > -1;
if (isAndroid &&isChromeBrowser)
{
//... ...
}
通过提取解释性的变量名称,用变量名来解释表达式的用途,可以让代码的可理解性更高。
- 提取方法。
//重构前
public void onCreate(){
ivAvater = findViewById(R.id.iv_avatar);
ivBg = findViewById(R.id.iv_background);
tvNick = findViewById(R.id.tv_nick);
//... ...
User user = momentsPresenter.getUserInfo();
//... ...
tvNick.setText(user.getNick());
ImageUtils.loadAvatarBitmap(this, user.getAvatar(), ivAvater);
ImageUtils.loadBitmap(this, user.getProFileImage(), ivBg, R.color.circle);
}
//重构后
public void onCreate(){
initView();
initData();
bindView();
}
通过提取方法,将原有过大的方法拆分为更多职责更加单一的小方法,让代码的可理解性更高。
整体来说,小型的重构所需要的时间相对较少。在任何编码阶段,只要识别到代码存在方法命名含义不清、过大的方法、过多的方法参数等问题时,就可以及时重构。
由于其影响范围小,并且可借助 IDE 进行自动化重构,因此比较安全。
三、中型重构
中型重构是对多个类间的重构优化,通常的一些修改包括提取接口、超类、委托等调整。
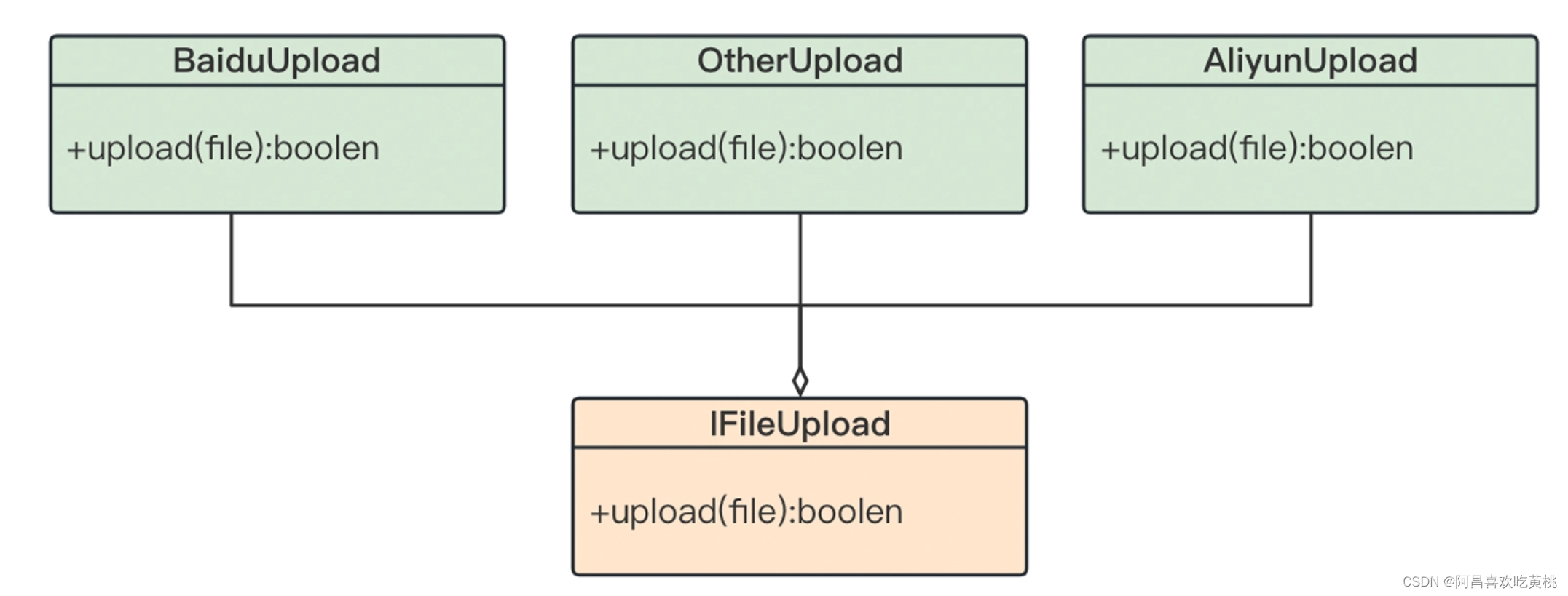
下面这段代码是一个文件的上传功能,需要根据用户的不同配置,将数据保存在不同的平台上。
//重构前
if(isBaiduYun){
//调用百度服务上传文件
}else if(is aliYun){
//调用阿里云服务上传文件
}else{
//使用自己的服务器上传文件
}
//重构后
iFileUpload.upload(file);
如下图所示,可以通过提取抽象的上传接口,来简化判断的逻辑,提高代码的可维护性。
中型的重构所需要的时间比小型重构长,因此,建议在添加新功能或者修复 Bug 时,找一个相对集中的时间段进行设计和修改。
由于中型重构相对复杂,很难借助 IDE 完成所有的重构操作,所以在中型重构时,要充分做好测试。
四、大型重构
大型重构是对整个系统的架构进行重构优化,比如组件化、应用中台架构升级等,通常在做大型重构时也会伴随中小型的代码重构。
以组件化为例,通过提取公用的基础组件和业务组件,来提高代码的可复用性,同时让业务能独立演进,就是一种大型重构。
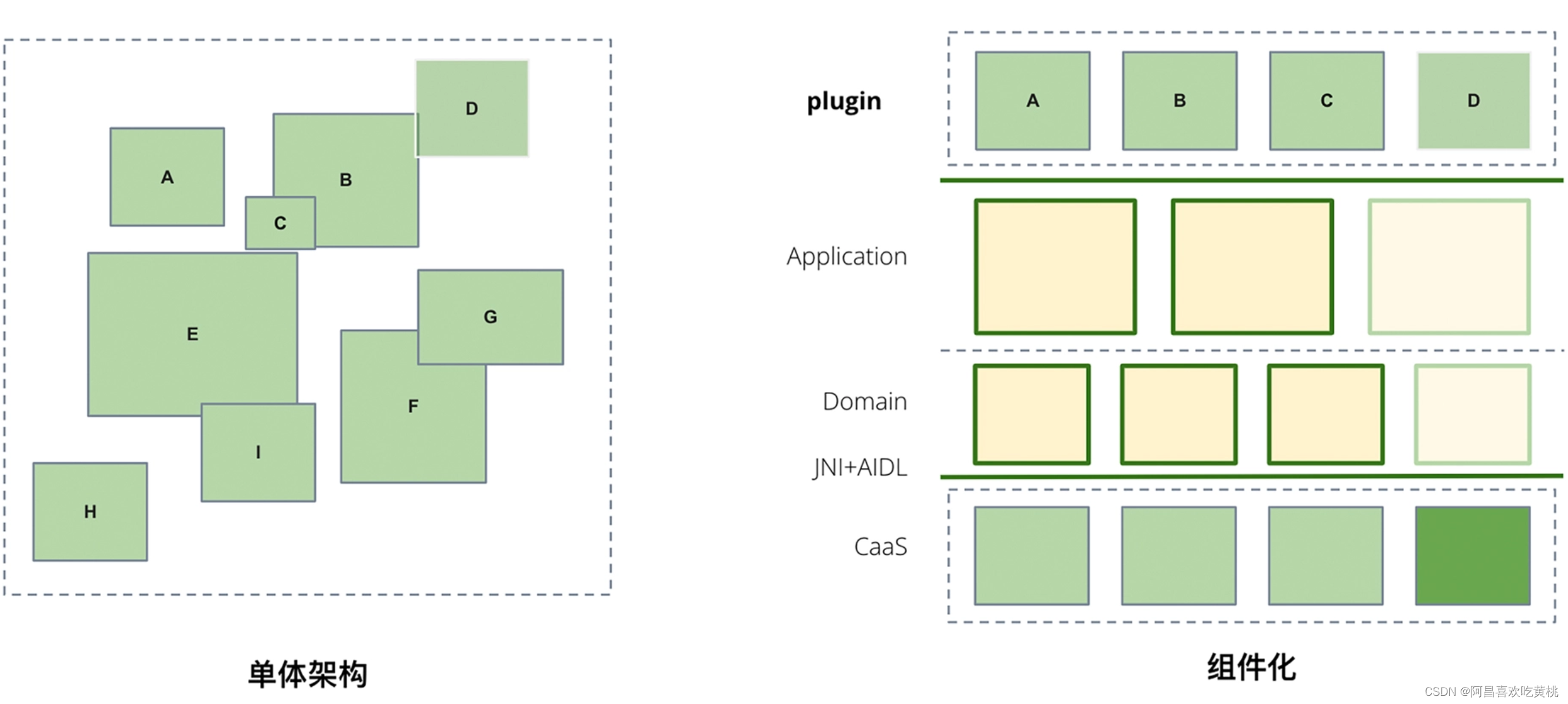
对于大型重构,特别是对大型的遗留系统进行改造,需要的时间往往得按月计算。并且在此过程中,业务还需要不断地演进,所以建议对大型重构立专项执行。另外,结合业务的迭代需求,可以把大型重构做一下拆分,在不同的研发迭代中重构。
例如,重构的目标是将大泥球系统 X 拆分为组件 A、B、C。由于组件 B 和 C 的业务在接下来的迭代中有较大的调整,那么就可以优先拆分出组件 A。实际的遗留系统,其耦合和依赖情况可能更复杂,需要具体分析后再制定对应的迭代策略。
从小型重构到大型重构,虽然产生的价值越来越高,但时间周期和对代码的调整也越来越大。通常认为修改的代码越多,引起风险的可能性就越高,所以不同类型的重构所造成的影响和工作量是不同的,我们要选择合适的重构时机,否则重构可能无法顺利完成。
五、重构的收益
重构的收益。这是一个比较有争议的话题,因为对于一个产品来说,重构不仅不会改变业务特性,还得团队另外投入时间,所以在国内一线交付压力如此巨大的情况下,重构往往都被排在业务迭代之后。而且,在遗留系统的问题上,研发人员和业务人员很容易直接形成“博弈的局面”:前者认为投入重构,提高代码的可维护性才能更好地支持业务;而后者觉得开发业务特性才是第一优先级。其实,业务人员也知道重构的重要性,只是关键问题在于没办法评估重构的收益。
重构的目的是在不改变软件可观察行为的前提下,重点提高其可理解性,降低其修改成本。
因此计算重构收益的方式很简单,从商业的角度来看,收益 = 软件价值 - (研发 + 维护成本)。
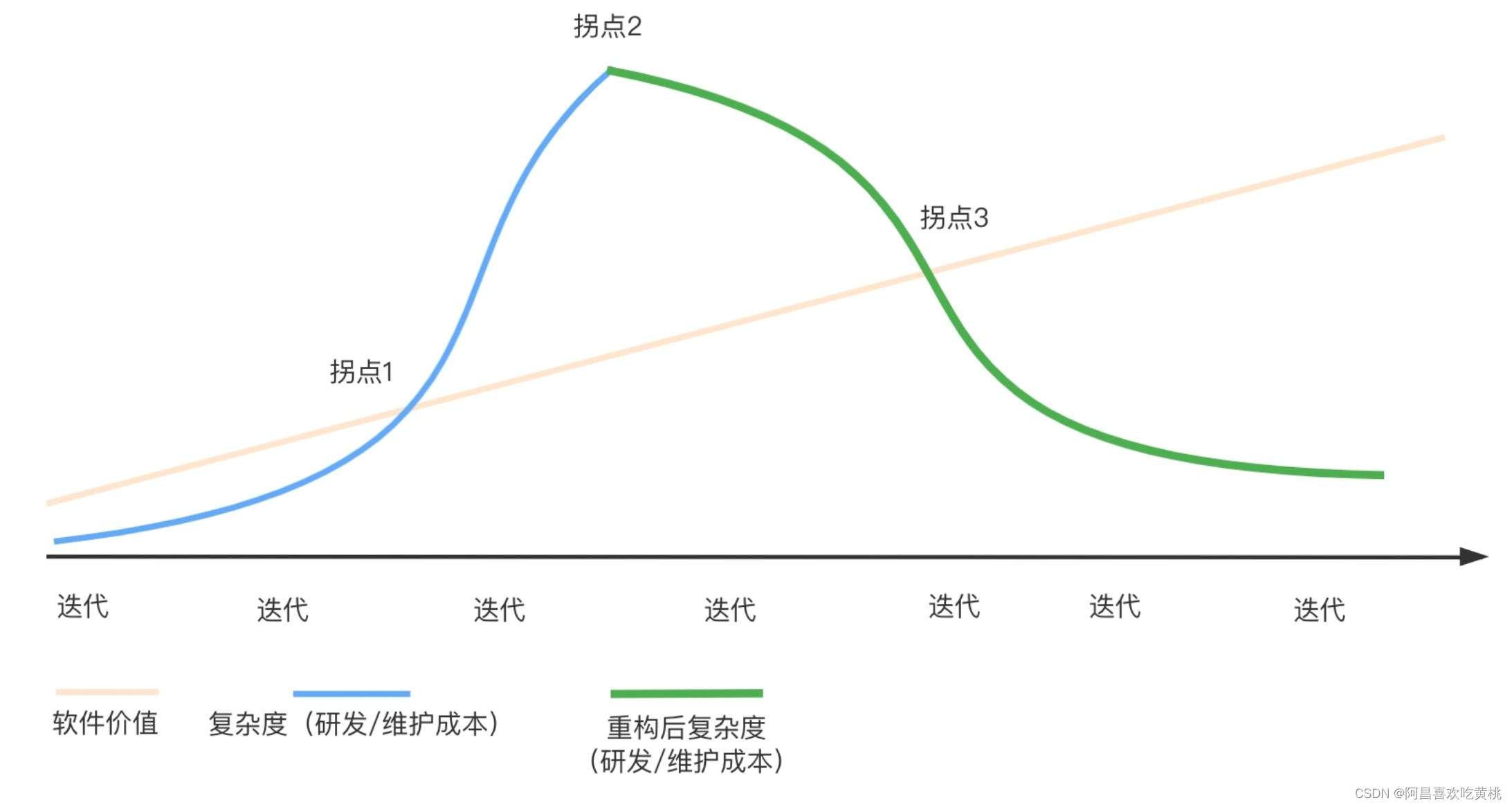
如果只注重业务上的价值而忽略了软件的研发维护成本,那么长此以往就会来到拐点 1。
当研发维护成本超出业务价值,收益就开始负增长了。很多企业往往也是到这个拐点才意识到重构的重要性。
通常来说,重构需要一段时间的投入,来慢慢降低研发维护成本。
可以从效率和质量两个维度来分析。需要说明一下,因为很难有完美的公式来计算重构的收益,而且实际情况不同,重构的收益可能会有差异,所以主要是通过一些具体的场景来看这个问题。
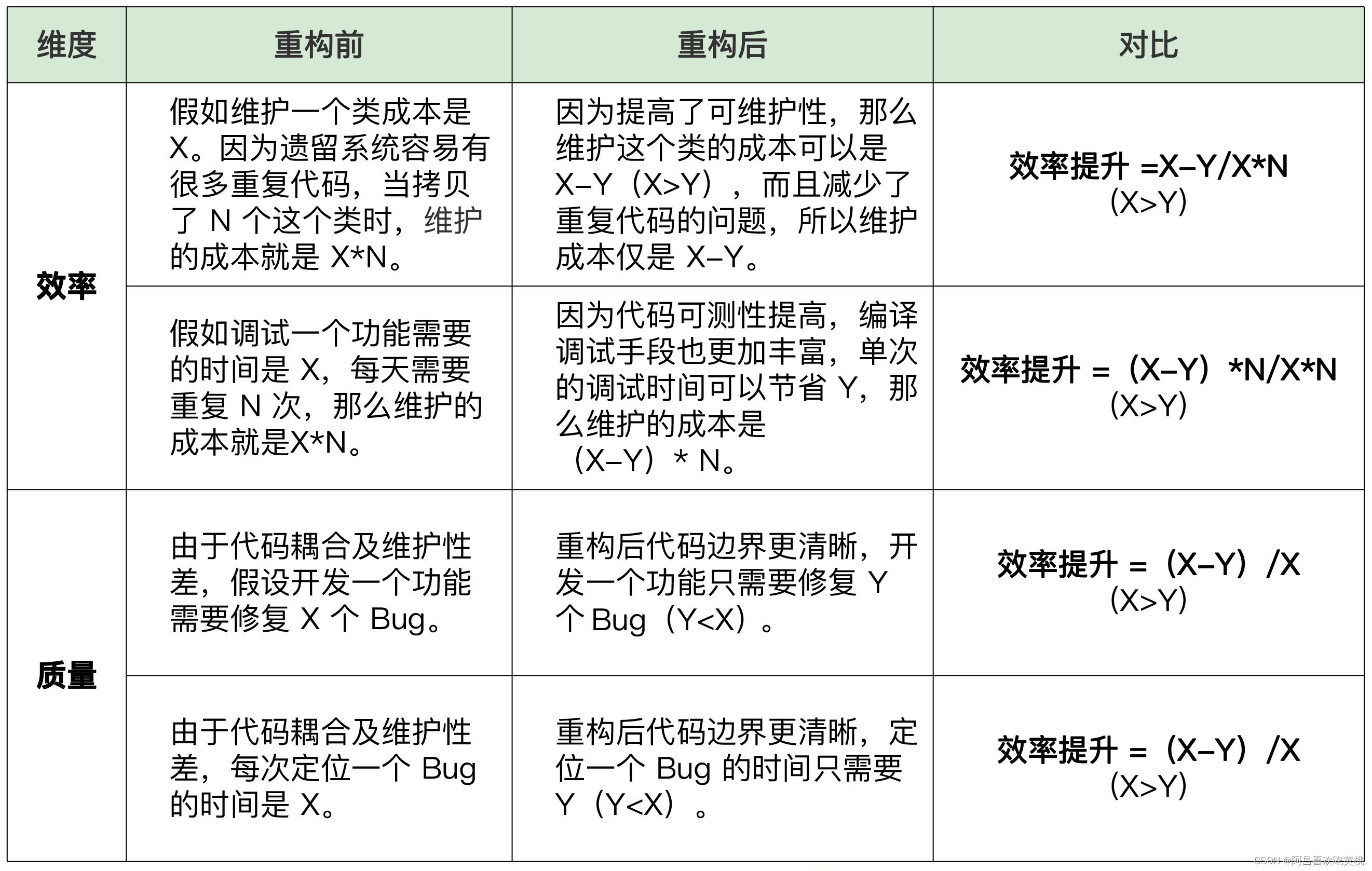
以上只是部分场景,除了效率和质量外,在实际开发中还要考虑人员的变化、新人理解代码所需的时间等等。
总而言之,重构虽然不直接影响业务的价值,但它会直接影响软件的研发维护成本,从而影响整体的收益。
六、重构的度量
那么又有新的问题来了,如何来度量这些收益呢?如果仅谈收益,没有客观的指标来反映结果,怎么证明最终的结果就是好的呢?
其实对于中小型重构,可以观察代码健康度相关的指标变化来度量重构的价值,比如代码的圈复杂度、平均函数行数、类行数等。
如果能及时对代码中存在的坏味道和问题重构,那么这些指标应该呈现良好的变化趋势。
具体来讲,可以借助工具来实时地可视化检测这些指标,例如用 Sonar 来查看代码的质量情况。
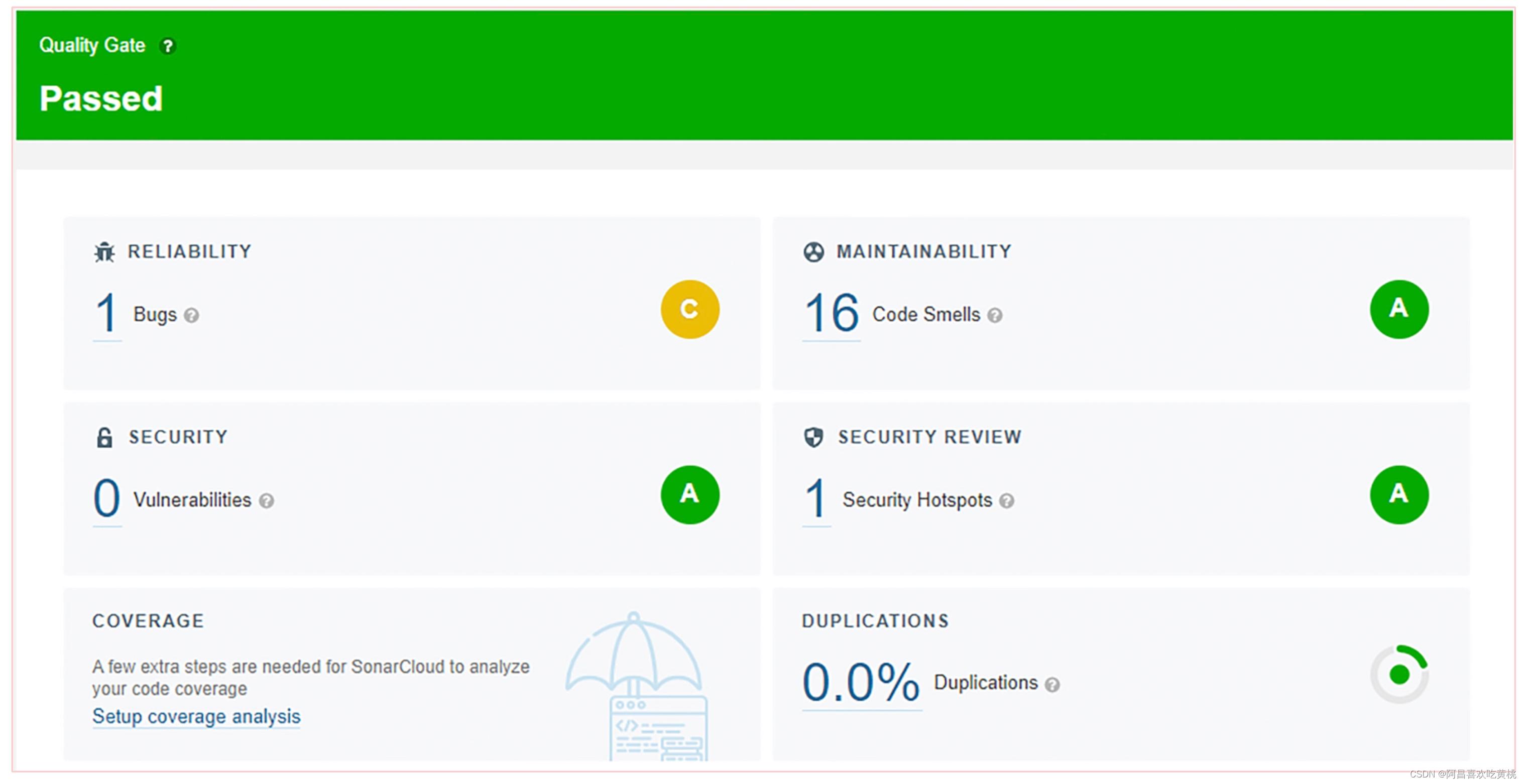
对于大型的重构来说,可以通过工程效率上的指标变化来可视化重构的收益。
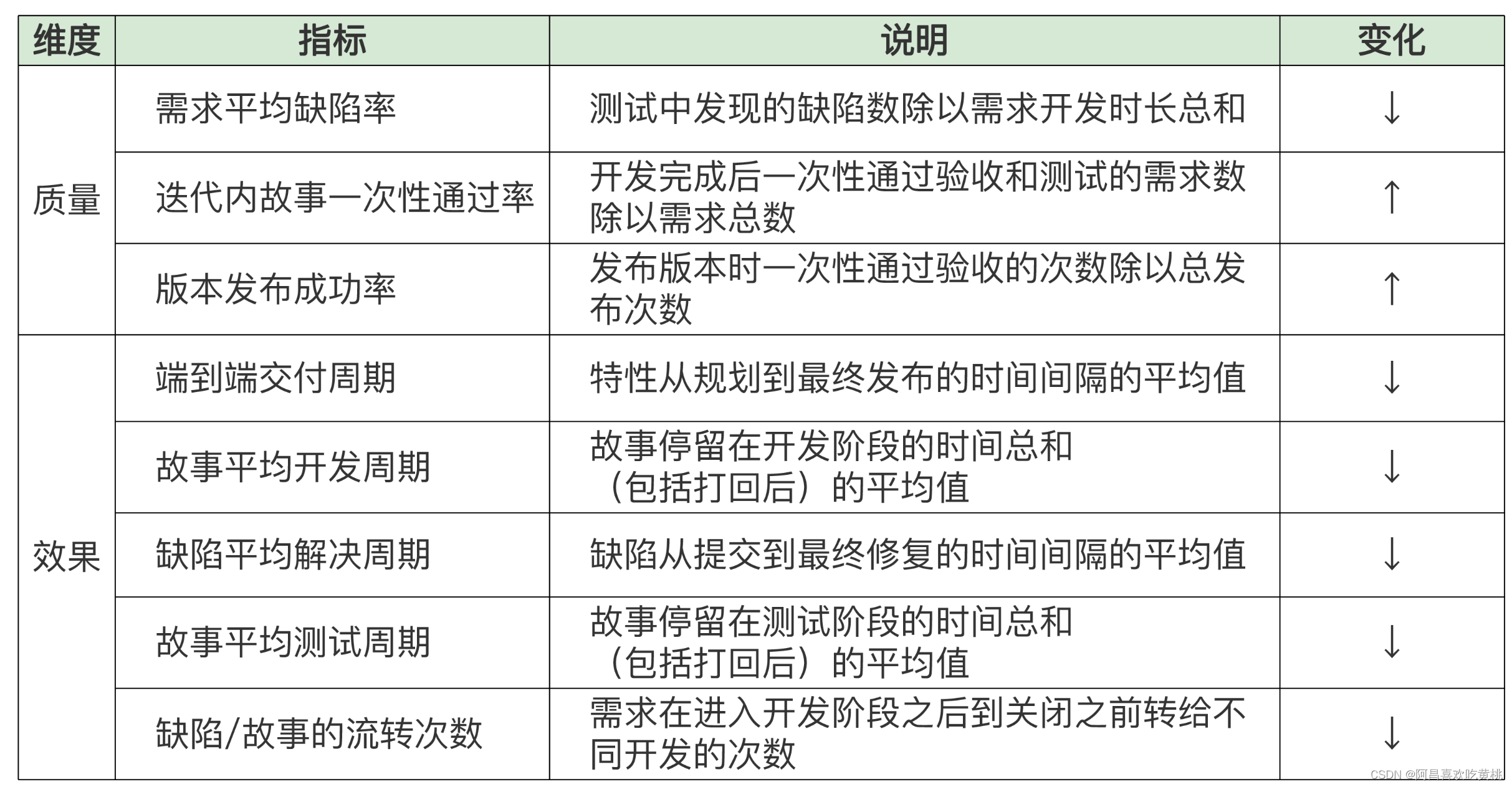
当然,这些指标的影响因素有很多,但重构最终的目的一定是为了更好地提升产品的质量和研发效率。只有以终为始,才能落地好重构。
七、总结
重构是对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。根据重构的影响范围,将重构分为小型重构、中型重构以及大型重构这三种类型。
从小型重构到大型重构,虽然产生的价值越来越高,但时间周期和对代码的调整也越来越大。
-
小型重构应该及时完成,在任何编码阶段都可以进行;
-
中型重构在添加新功能或者修改 Bug 时进行设计和重构;
-
大型重构则应该立专项推进。在实际落地重构工作时,首先需要通过代码质量、工程效率让其价值更加可视化。
另外还需要对重构进行合理拆分和优先级排序,别让重构变成最后的救命稻草,而应该将它持续纳入到日常的研发迭代中。
如果产品的质量、团队的效率跟不上,那么只谈产品和业务无疑是空中楼阁。
对于中小型重构,可以通过代码的健康度相关指标变化来度量重构的收益。
对于大型的重构,可以通过工程效率上的指标变化来度量重构的收益。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











