







运用Python对简书首要进行简书首页的文章信息进行爬取。具体包括:文章标题、文章id、用户昵称、用户id、总浏览量、评论数、点赞数、赞赏量。以及文章插图和用户头像的下载。并对以上数据进行excel的存储,首先进行文件是否存在的判断,不存在,则创建。再比较pandas包方法存储和xlwt方法。

网页分析
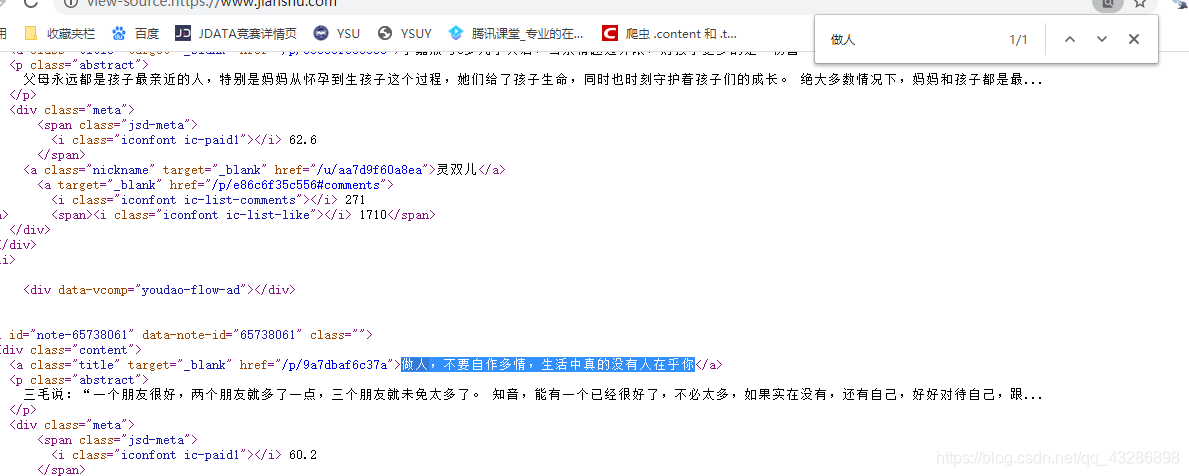
首先对简书首页网页进行分析。在查看网页源代码中按下ctrl+F键搜索“做人,不要自作多情,生活中真的没有人在乎你”,结果发现能从网页源代码中找到。
再对原始网页点击阅读更多,同样在网页源代码中搜索阅读更多中的任意一篇文章,结果在网页源代码中没有找到。且网页url没有变化。可以判断此网页用了异步加载技术(Ajax)。
再在网页右击选择检查——network——xhr。刷新网页可以发现 再点击展开更多文章,可以发现
再点击展开更多文章,可以发现


 打开url可以发现出现的正是我们需要的数据。
打开url可以发现出现的正是我们需要的数据。

于是对url进行了修改,url=https://www.jianshu.com/asimov/trending/now?count=15¬e_ids=9。也出现了数据。最终可以获得url为https://www.jianshu.com/asimov/trending/now?count=15¬e_ids= +一个数字。
爬取数据
由上述分析获得了网页url,返回的为json文件。如下。
 具体爬取代码如下:
具体爬取代码如下:
-
导入工具包,os包用来查看文件夹是否存在。xlwt和pandas用来存储到excel,time用来计时。

-
添加请求头

-
定义网页爬取函数

-
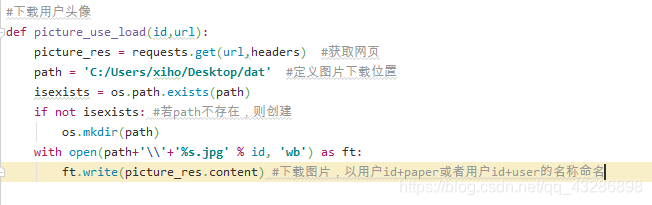
定义图片下载函数
-
主函数+数据保存
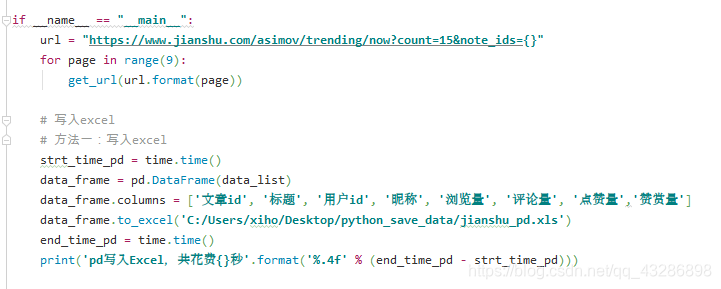

-
结果
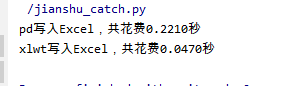 显然xlwt写入excel要快。
显然xlwt写入excel要快。

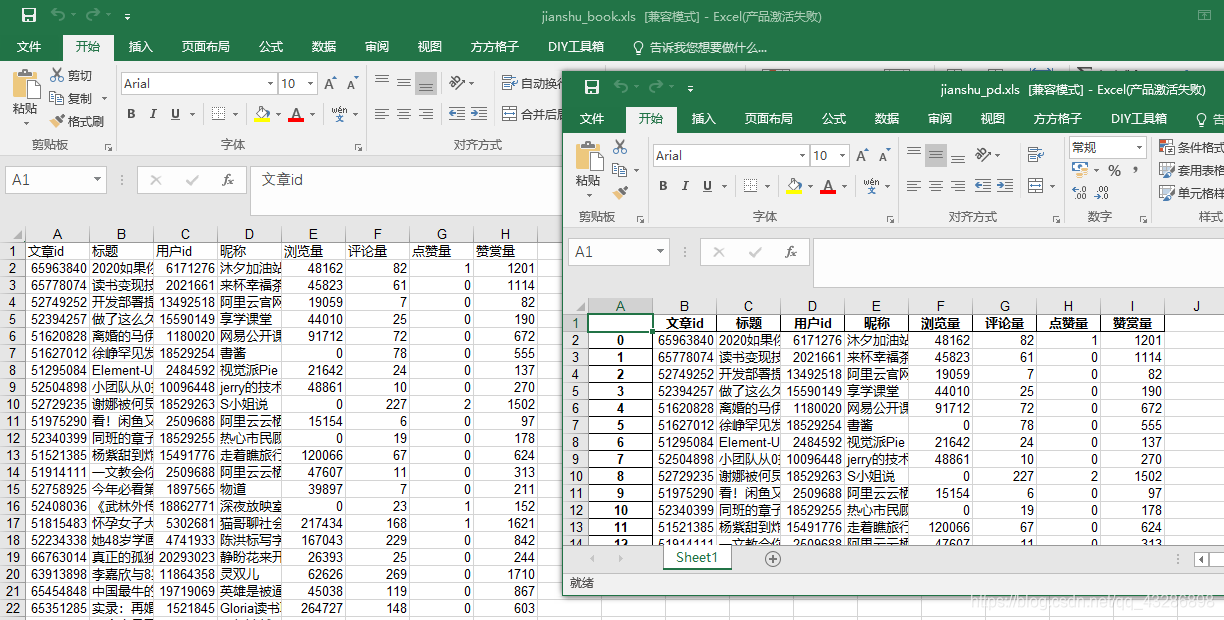 初次分享,还有很多不完整的地方,还望多多指正。
初次分享,还有很多不完整的地方,还望多多指正。















 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











