







一、MYSQL
- 使用group by
select a,b,c
from (
select a,b,c
from A
order by a desc
limit 1000) tem
group by tem.b
必须要使用limit,因为mysql 5.6之后版本对排序的sql解析做了优化,子查询中的排序是会被忽略的,所以上面的order by salary desc会失效,需要用limit来避免这种优化。
- 使用窗口函数
select a,b,c
from(
select
a,b,c
ROW_NUMBER() OVER(partition by aorder by cdesc) as num
from A) tem
where tem.num=1
二. ORACLE
oracle中分组排序函数用法:
- row_number() over()
row_number()over(partition by col1 order by col2)表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。
与rownum的区别在于:使用rownum进行排序的时候是先对结果集加入伪劣rownum然后再进行排序,而此函数在包含排序从句后是先排序再计算行号码。row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开始排序)。
select t.*,row_number() over(partition by accno order by createDate) row_number from Test t
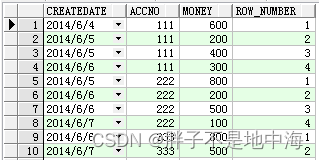
大家可以注意到ACCNO为111的记录有两个相同的CREATEDATE,用row_number函数,他们的组内计数是连续唯一的,
- rank() over()
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
select t.*,rank() over(partition by accno order by createDate) rank from Test t

可以发现相同CREATEDATE的两条记录是两个第2时接下来就是第4.
- dense_rank() over()
dense_rank()也是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的。
select t.*,dense_rank() over(partition by accno order by createDate) dense_rank from Test t
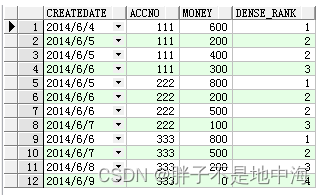
可以发现相同CREATEDATE的两个字段是两个第2时接下来就是第3.
再比如有时会要求分组排序后分别取出各组内前多少的数据记录,sql如下:
select createDate,accno,money,row_number from
(select t.*,row_number() over(partition by accno order by createDate) row_number from Test t) t1
where row_number<4















 919
919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









