






 ACfun面捕助手是一款适用于直播间虚拟主播的软件,能捕捉面部表情生成生动的虚拟形象。用户可选择预设角色或导入模型,支持Live2D和VRM模型。软件提供多种角色和背景,适合新手使用,与AcFun直播伴侣、快手直播伴侣兼容,通过简单的设置即可实现面部捕捉和同步动作。
ACfun面捕助手是一款适用于直播间虚拟主播的软件,能捕捉面部表情生成生动的虚拟形象。用户可选择预设角色或导入模型,支持Live2D和VRM模型。软件提供多种角色和背景,适合新手使用,与AcFun直播伴侣、快手直播伴侣兼容,通过简单的设置即可实现面部捕捉和同步动作。
对于不想在直播间露脸的博主来说,acfun面捕助手绝对是一款不可多得的多功能的虚拟主播面捕工具,通过它能够捕捉到主播直播时的面部表情,从而让虚拟主播更加的形象生动。软件操作起来十分的简单,只要有摄像头,一键导入图片就可以生成自己的虚拟偶像,支持live2D模型和vrm模型一键导入,还拥有一项原创黑科技,让你的原画直接动起来。同时,软件内拥有多款正版预设角色,既有御姐也有萝莉,更有搞怪的人物形象出现,基本可以满足新上手用户的需求,比如波兔、章鱼娘、大小 姐、妹抖酱、兄 贵护士等等供你选择,可免费使用,支持在工具内选择“添加模型”,选择本地的模型文件,即可成功导入模型角色啦。以及用户还可以选择自创角色,一键导入修改背景图,上传符合规范的psd文件。此外,acfun面捕助手使用范围也是极为广泛的,AcFun直播伴侣、快手直播伴侣均可使用,下载并安装完成后,在伴侣内添加画面来源时选择游戏进程,下拉菜单选择AcFunVirtualView即可同步画面,只要你对着镜头讲话晃动,你的虚拟人物也会随之做出相应的动作,感兴趣的赶紧下载体验。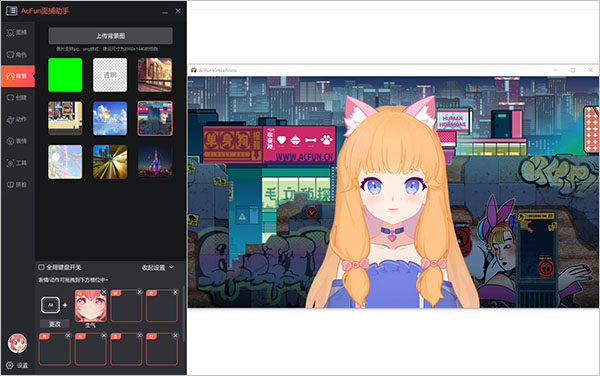
软件特点
1、预设角色
我们拥有多款正版预设角色,可免费使用!
波兔、章鱼娘、大小 姐、妹抖酱、兄 贵护士……
多种选择,更多欢笑!
2、支持导入模型角色
在工具内选择“添加模型”,选择本地的模型文件
即可成功导入模型角色啦~
3、手绘角色制作教程
在工具内选择【自创角色】,上传符合规范的psd文件,
即可让你的原画站起来自己动!
acfun面捕助手使用说明:
1、首先在电脑上打开该软件,如下图所示,设置面部捕捉,比如当前摄像头、摄像头画质、采集频率、视觉跟随等等,由于小编这里没有摄像头,镜头显示这里是黑色的,人脸要在镜头内才可以被识别;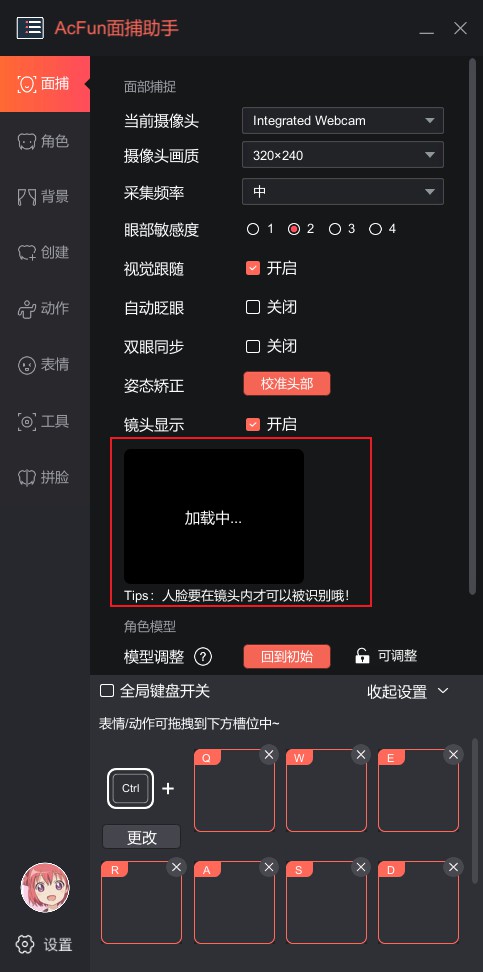
2、点击角色,在这里你可以选择一个你自己喜欢的人物;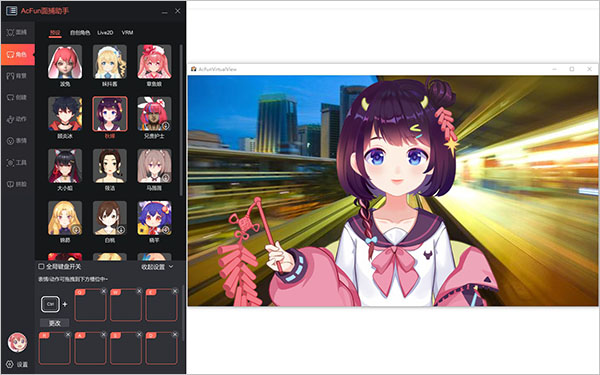
3、支持自创角色,点击+上传合规psd文件,一键生成虚拟形象,如果你不会的话,可以查看psd教程哦!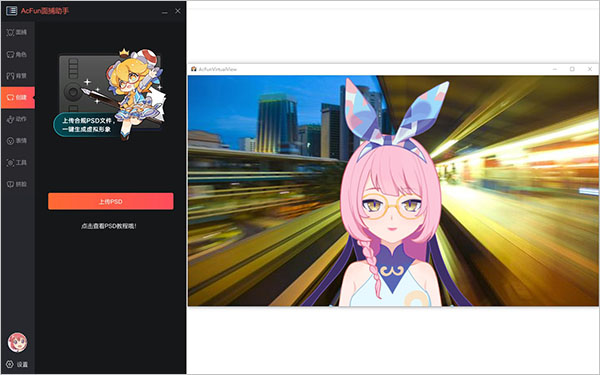
4、以及软件能够上传背景图,更改背景图;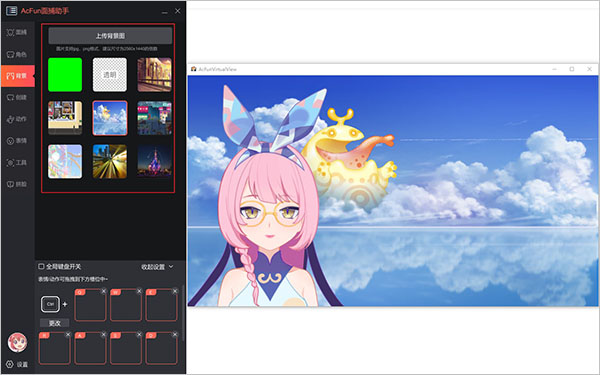
5、点击拼脸,选择模板开始拼脸换装,点击【生成人物】即可生成可面捕人物,拼图过程中人物是无法面捕,点击生成人物后稍等片刻,拼好的人物就会动起来啦。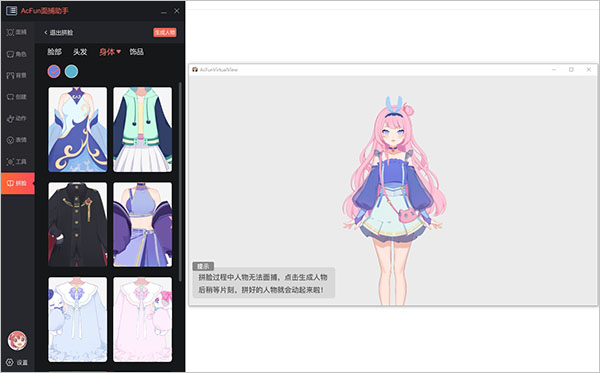
开播指南
1、需搭配直播伴侣使用,例如AcFun直播伴侣、快手直播伴侣......
2、下载并安装后,在伴侣内【添加画面来源】时选择【游戏进程】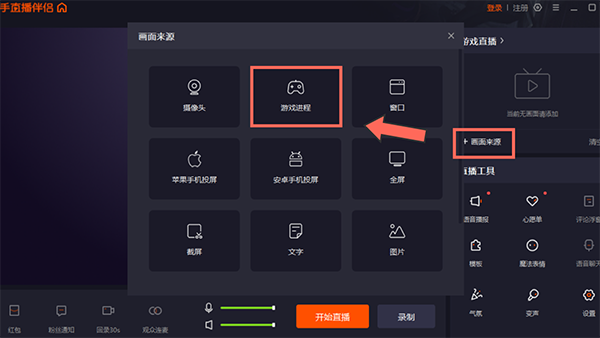
3、下拉菜单选择AcFunVirtualView即可同步画面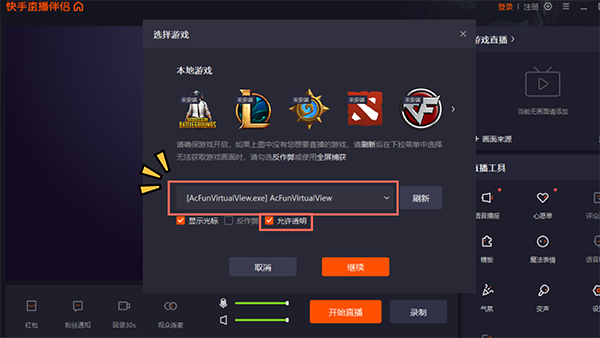
相关新闻
面部动捕上手简易,素材一键导入
作为A站推出的官方工具,能够看到A站也十分清晰目标受众的需求,这款面捕工具最大的特色便是易用性很高。
在虚拟偶像的形象方面,A站面捕助手提供了不少可供选择预设角色,在人物形象上也涵盖了较为全面,既有御姐也有萝莉,更有搞怪的人物形象出现,基本可以满足新上手用户的需求。在面捕技术方面,A站助手已经能够做到嘴型、眼部等方面的自动跟随,并且捕捉较为准确灵敏。
并且在此基础上A站面捕助手还加入不少细节化的工具,比如预设的人物背景,当然软件中也准备了透明、绿幕等预设场景方便用户自行添加自己喜爱的场景。
除此以外,软件中还加入了人物动作、人物表情等工具,用户已经可以使用这些工具实现一套基本的虚拟偶像视频录制,甚至是直播的流程。
硬件设施要求
电脑最低配置建议:
操作系统 Windows 7 / Windows 8 / Windows 10 64位系统
处理器 Intel Core i3或是 AMD Phenom X3 8650
显卡 NVIDIA GeForce GTX 460, ATI Radeon HD 4850, 或是 Intel HDGraphics 4400
内存 4 GB RAM


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









