




 提出Linformer模型,通过引入低秩矩阵近似自我注意机制,实现从O(n²)到O(n)的时间复杂度降低,适用于大规模点云数据处理。
提出Linformer模型,通过引入低秩矩阵近似自我注意机制,实现从O(n²)到O(n)的时间复杂度降低,适用于大规模点云数据处理。
留个笔记自用
Linformer: Self-Attention with Linear Complexity
做什么
点云的概念:点云是在同一空间参考系下表达目标空间分布和目标表面特性的海量点集合,在获取物体表面每个采样点的空间坐标后,得到的是点的集合,称之为“点云”(Point Cloud)。
点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等,不一一列举。
一般的3D点云都是使用深度传感器扫描得到的,可以简单理解为相比2维点,点云是3D的采样

做了什么
这里设计了一款transformer变种,证明了自我注意机制也就是self-attention可以用一个低秩矩阵来近似,于是可以将时间复杂度O(n2)缩减至O(n)的线性transformer
怎么做
回忆一下常见的SA计算方法
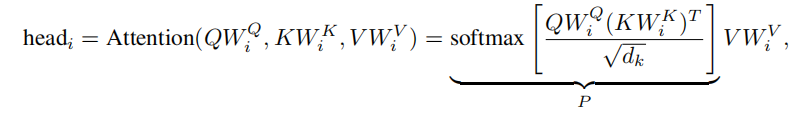
这里的三个W均是学习的矩阵,QKV就是常见transformer中的查询向量、键向量、值向量,对比之前论文里出现的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









