









留个笔记自用
Sparse Sinkhorn Attention
做什么
点云的概念:点云是在同一空间参考系下表达目标空间分布和目标表面特性的海量点集合,在获取物体表面每个采样点的空间坐标后,得到的是点的集合,称之为“点云”(Point Cloud)。
点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等,不一一列举。
一般的3D点云都是使用深度传感器扫描得到的,可以简单理解为相比2维点,点云是3D的采样

做了什么
设计了一种sparse attention的计算方法,引入了一个元排序网络,它学习生成序列的潜在排列。给定排序后的序列,就可以用局部窗口计算准全局注意力,从而提高注意力模块的存储效率。
怎么做
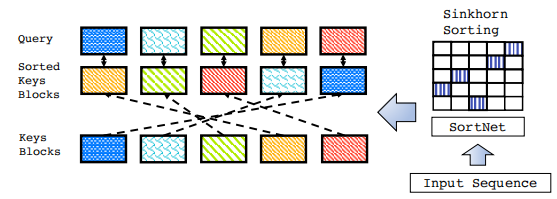
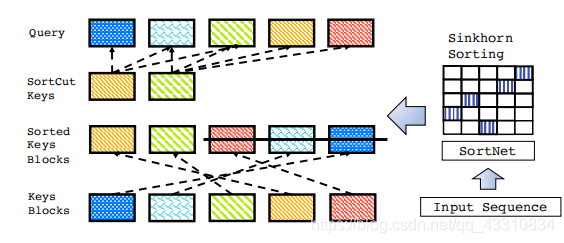
这里的输入是一个长为l的序列X,首先将其分为Nb个小块,每个小块包含了b个token,简单来说就是对一个句子先分块,块内再分段,就像存储方法一样。
然后提到了一点,常见的分块attention的做法里是段内封闭的,也就是当前块内的token只能跟本块里的所有token进行attention,而不能与块外的,显然这样就限制了全局性特征
于是这里为了解决这个问题,提出了一个排序网络sortnet,也就是说首先将input的序列首先输入这个网络,然后用这个网络对序列的块和感受野进行一个排序,这里排序的单位是块,然后根据排序后的一个序列结果(称为逻辑块),每个token再和逻辑块进行attention
具体来说
首先是排序网络sortnet
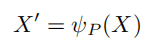
这里的输入X就是前面说的input序列∈Rl×d(l是长度,d是特征数),ψ是一个常见的块pool函数,将X分块成X’∈RNb×d,这里的Nb就是块数,其实有点特征维度映射的感觉
然后是
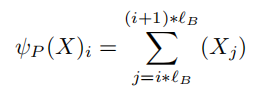
函数的具体做法就是这相当于取属于local窗口的所有token的和,简单就是窗口内token之和作为块代表
然后整体排序方法是

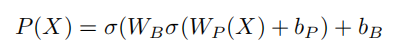
这里的Ri的意思是第i个block,Wp和Wb是线性权重,b是偏置权重,σ是激活函数,简单来说就是一个mlp计算得到它的投影,而输入是Xi’
简单来说就是首先先将输入分块,然后用一个sortnet对每块进行重新分配,用的一个mlp计算每个块到其他块的投影,也就是它移动到的位置
然后对于这里计算得到的R,使用了一个叫 SINKHORN NORMALIZATION的norm操作
首先先介绍了一下R,也就是前面得到的排序方法->排序矩阵R,为了让它成为标准的排序矩阵,需要它是非负的,并且行和列总和都是1也称为双随机矩阵,这里就是要学习如何将矩阵R双随机化
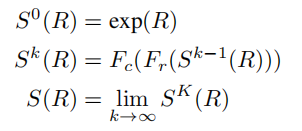
Fr和Fc是行和列标准化函数
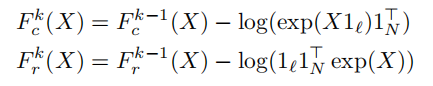
这里的⚪是逐元素矩阵相除,1是单位向量,这里就是对矩阵R的行和列进行变化,具体的做法非常数学,在我这简单理解就是将R矩阵转换成能够满足我们需要的排序矩阵就行
得到了双随机化的排序矩阵R后
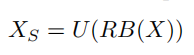
这里的B就是前面的block化函数,U则是token化函数,也就是将input序列块化后跟排序矩阵R相乘进行转换位置,然后使用U函数将块化还原成token
然后就是attention部分,Sparse Sinkhorn Attention
首先先看看普通的attention是怎么计算的,然后进行一个对比

而这里
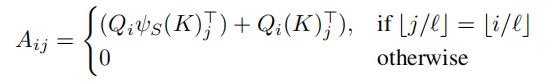
首先第一步也是计算A,原来的A是Q(查询向量)K(键向量)V(值向量)计算得到,而这里多了一个函数ψ,这个函数就是排序函数,简单来说,对于Aij位置就是第i个点和第j个点的attention关系,首先使用i点的查询向量乘上j点的键向量,这里和之前的attention计算一样,但是多了一步就是前面的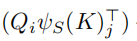
这里是加上了i点的查询向量和排序后的j点的键向量,这里的排序就是用到了前面的sortnet,文中说明的是,这等同于只启用关注而不启用某个局部邻域,其实在我看来就是利用了排序的变动性增强了局部和全局性,老套路了
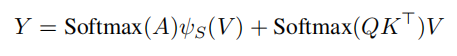
然后就是softmax,值得注意的是这里也融合了两种,前面用的键向量也是转移后的,后面就是最普通的selfatt的计算
总的来说这里就是对原来block式attention的方式做了点改动,使它能更好的找到距离较远也就是非局部的关系
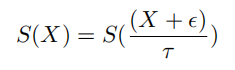
这里是在转移函数的基础上加了点noise,文中说这样做反正是有好处的
然后也是attention的老套路,mul-head,也就是多头计算
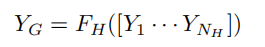
整多个一样的网络一步步算,然后把每步结果concat起来,经典全局-局部式增强
做好了这些基础工作后,这里又提出了一些问题
第一就是排序网络的问题,如果当前块i重排到了位置p并且p<i,这种情况就属于不合理(在nlp里,但在点云里感觉是合理的),等同于未来的信息流露到了现在进行计算,出现这种情况就应该被屏蔽掉
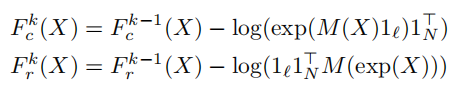
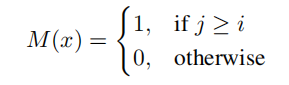
第二就是对前面的ψP进行的优化
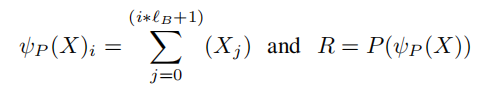
为什么说不合理呢,因为前面的计算方法是
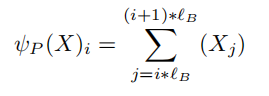
等同于把块内所有token的特征结合在一起,这种信息过于局部化,这里更新的方法是从第0个token的embedding开始,结合至第i个块的token的全部embedding,这样就会使得当前块的信息是具有前面所有的上下文信息的
除此之外,因为常见的句子embedding中会出现与其他都无关系的不重要部分,这里也用了常见的top-k方法来屏蔽那些不重要的权重
简单来说就是使用排序网络进行P排序的时候只取值较高的进行attention计算
总结
1.sparse attention的进化版,利用分块的方法减小计算量,同时还使用了排序的方法增强了全局稀疏点之间的关系,同样排序的方法也会使得就算block计算领域也显得能模拟全局

















 5431
5431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









