







注:本文章只作为本人笔记来使用,内容浅显,如有不当之处,敬请指正!
教材:汇编语言 王爽著
1.段的理解
教材中有这样一些表述:
我们注意到,“段地址”这个名称中包含着“段”的概念。这种说法可能会对一些学习者产生了误导,使人误认为内存被划分成了一个一个的段,每一个段有一个段地址。如果我们在一开始形成了这种认识,将影响以后对汇编语言的深入理解和灵活应用。
其实,内存并没有分段,段的划分来自于CPU,由于8086CPU用“基础地址(段地址×16)+偏移地址=物理地址”的方式给出内存单元的物理地址,使得我们可以用分段的方式来管理内存。

我所理解的段地址,就如偏移地址和基础地址一样,只是一个名字,而所谓的可以用分段的方式来管理内存,是在有了段地址这一名称之后,随之而分化出来的,是为了对内存更方便的管理而衍生出来的一种内存管理方式。段地址仍然是寄存器中的16位二进制代码所表示出来的,基础地址是段地址左移四位得到的,偏移地址与段地址一样均为寄存器中的二进制代码。通俗说就是内存中的地址依然按照一维方式进行排列,它对“CPU是如何通过地址总线访问”这件事置若罔闻,甚至是稀里糊涂的就被CPU划分为N段来进行访问,一切的工作都是CPU费尽心思做出来的。
这样来看,CPU对内存划分为N段后,物理地址仍为(基础地址+偏移地址),偏移地址是由寄存器决定的,为16位,寻址能力为64KB,因此,一个段的长度最大为64KB。
8086CPU有20位地址总线,拥有1MB的寻址能力,而其又是16位结构,如果地址从内部简单发出,只能获得64KB的寻址能力,所以要有些不寻常的方法来实现。

物理地址=段地址×16(10H)+偏移地址
(×16在二进制表示中代表左移4位,在十六进制中代表左移一位)这样就解决了寄存器为16位而地址线为20根的问题。
2.CPU是如何区分指令和数据的?
可以大致看出u指令将某个内存地址开始的字节全部当作指令,d指令将某个内存地址开始的字节全部当作数据。8086CPU中,在任意时刻,CPU将CS:IP所指向的内容全部当作指令来执行。在内存中,指令和数据是没有任何区别的。都是二进制信息,CPU只有在工作的时候才把有的信息当作指令有的信息当作数据。若问CPU根据什么将内存中的信息当作指令的话,CPU将CS:IP指向的内存单元中的内容当作指令。(有人可能会问到若CS:IP会依次指向内存所有地址,岂不是内存中只有指令没有数据?——首先,内存中的数据和指令本来就没有区别,而CS:IP不会指向所有的内存单元,并且只有CS:IP指向的内存单元里的数据才会被当作指令去执行。)
几种回答:(来源 知乎 侵删)

1.

2.
3.
3.指令的执行过程
①. CPU从CS:IP所指向的内存单元读取指令,存放到指令寄存器中;
②. IP=IP+所读指令所占的字节数,从而指向下一条指令;
③. 执行指令寄存器中的内容(执行过程有可能IP的值再一次被改变,如 jmp 指令),回到步骤①。
4.字的存储
CPU中16位寄存器存储一个字(2Byte),高八位存放高位字节,低八位存放低位字节,而在内存中,每个内存单元存放一个字节(1Byte),因此一个字要用两个地址连续的内存单元存放。如下,用0、1两个内存单元存放(4E20),低地址单元存放低位字节,高地址单元存放高位字节。
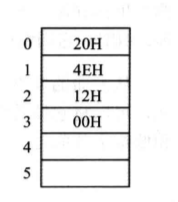
存放一个字型数据(16位)的内存单元称为字单元,由两个地址连续的内存单元组成。
5.DS和[address]
若要读写一个内存单元的时候,必须给出这个内存单元的地址,内存地址由段地址和偏移地址组成,DS寄存器通常用来存放要访问数据的段地址。
示例:
mov bx,1000H mov ds,bx mov al,[0]
“[…]” 表示一个内存单元,里面的值即“…”表示内存单元的偏移地址,ds中存储段地址,从而可以访问内存单元。
需要注意一些问题,引述上例,如 mov al,[0]是将10000H单元的数据送入低位寄存器al中,而 mov ax,[0]是将10000H和10001H中的数据送入寄存器ax中。
6.部分指令
目前只学到了基础指令,如add,sub,mov
mov指令可以由如下方式:
mov 寄存器,数据 如:mov ax,8
mov 寄存器,寄存器 如:mov ax,bx
mov 寄存器,内存单元 如:mov ax,[0]
| 指令 | 区域 | 示例 |
|---|---|---|
| mov | 寄存器,数据 | mov ax,8 |
| mov | 寄存器,寄存器 | mov ax,bx |
| mov | 寄存器,内存单元 | mov ax,[0] |
| mov | 内存单元,寄存器 | mov [0],ax |
| mov | 段寄存器,寄存器 | mov ds,ax |
| mov | 寄存器,段寄存器 | mov ax,ds |
| mov | 内存单元,段寄存器 | mov [0],cs |
| mov | 段寄存器,内存单元 | mov ds,[0] |
1.CS:IP:指示了CPU当前要读取指令的地址。
2.DS寄存器:通常用来存放要访问数据的段地址。[…]表示一个内存单元,…表示内存单元的偏移地址。
3.push 入栈,pop 出栈:例如,push ax 表示将寄存器ax中的数据送入栈中,pop ax 表示从栈顶取出数据送入ax。
4.段寄存器SS存放栈顶的段地址,寄存器SP存放栈顶的偏移地址,任意时刻,SS:SP 指向栈顶元素。
4.1Debug的 t 指令在执行修改寄存器SS的指令时,下一条指令也紧接着被执行。
5.[bx]同样表示一个内存单元,偏移地址在bx中,段地址默认在ds中(例如:[bx] 即 ds:[bx])。
6.inc bx为自增指令,执行完后(bx)=(bx)+1。
7.loop循环指令执行时分为两步:① (cx)=(cx)-1;②判断cx中的值,不为零则转至标号处执行程序,如果为零
则向下执行。循环次数存储在cx中。
8.g命令实现一次性执行到某条指令之前:g 0012 表示执行程序到当前代码段(段地址在CS中)的0012h处。
9.在汇编源程序中,应写作 段寄存器:[…],来表示物理地址,或直接用[bx]表示段地址默认为ds的物理地址。
10.段前缀:[bx]中内存单元的偏移地址由bx给出,而段地址默认在ds中。可以在访问内存单元的指令中显式地给出
内存单元的段地址所在的段寄存器。例如:ds:[bx]、cs:[bx]、ss:[bx]、es:[bx]。以及不带有bx的 ss:[0]、cs:[0]。
11.8086CPU不允许将一个数值直接送入段寄存器中,需通过 mov ax,… mov ds,ax的方式。
12.dw定义字型数据(数据之间以逗号分开),db为字节型数据。需注意,段的起始地址为16的倍数,即如果在开始
自定义的数据段中定义了3个字型数据,占用6个字节,那么下一段的起始地址不紧接其后,而是“另起一行”。
dw、db可相当于C语言中的数组。
13.用多个段来分别存放数据、代码和栈使程序更加清晰。自定义的段名代表了段地址,如定义数据段名称为data,则
mov ax,data,mov ds,ax 代表将数据段段地址放入 ds 中。
14.and 与操作,通过该指令可将操作对象的相应位设为0;or 或操作,通过该指令可将操作对象的相应位设为1,
例:and al,00111011B,or al,00111011B。
15.[bx]指明一个内存单元,也可用[bx+idata]表示,其偏移地址为(bx)+idata,可写作mov ax,200[bx]
(或者 [bx+200]、[200+bx]、[bx].200)。
16.SI和DI是和bx功能相近的寄存器,但si和di不能分成两个8位寄存器来使用。可用[bx(si或di)+idata]来指明内存
单元。
17.另外的方式:①.[bx+si(或di)],偏移地址为(bx)+(si);②.[bx+si(或di)+idata],偏移地址为(bx)+(si)+idata,
可写作 bx+si+200、200[bx][si]、[bx][si].200。
18.使用双重循环时,应将外层循环的cx值保存起来,执行完内层循环时,再恢复外层循环的cx数值,可以利用栈空间。
19.在8086CPU中,①只有bx,si,di,bp这四个寄存器可以用在“[…]”中来进行内存单元的寻址。②在[…]中,这四个寄存器可以单个出现,或只能以4种组合出现:bx和si,bx和di,bp和si,bp和di。③只要在[…]中使用寄存器bp,而指令中没有显性地给出段地址,段地址就默认在ss中。
20.指定指令要处理的数据有多长,①.通过寄存器名指明要处理的数据的尺寸(例:字操作mov ax,1、mov ds:[0],ax;字节操作mov al,1、mov ds:[0],al); ②.在没有寄存器名存在的情况下,用操作符X ptr指明内存单元的长度,X可为word或byte,例:字操作mov word ptr ds:[0],1、字节操作mov byte ptr ds:[0],1。
21.转移指令
offset:offset 标号,取得标号的偏移地址,例:mov ax,offset s
jmp指令集合:
jmp short 标号:段内短转移,转移到标号处执行命令,修改IP寄存器,
(IP)=(IP)+8位位移(对应机器码中包含转移的位移,而不是直接给出);
jmp near ptr 标号:段内近转移,修改IP寄存器,(IP)=(IP)+16位位移;
jmp far ptr 标号:段间转移,修改CS和IP寄存器,(CS)=标号所在段的段地址,(IP)=标号在段中的偏移地址;
jmp 16位寄存器(reg):修改IP寄存器,(IP)=(16位reg);
jmp word ptr 内存单元地址(段内转移):修改IP寄存器,(IP)=(字单元数据)
jmp dword ptr 内存单元地址(段间转移):修改CS和IP寄存器,修改后CS中为高地址的字,IP中为低地址的字;
jcxz 标号:有条件转移指令,当(cx)=0时,(IP)=(IP)+8位位移,当(cx)≠0时,什么也不做(程序向下执行);
loop 标号:循环指令,执行时(cx)=(cx)-1,若(cx)≠0,(IP)=(IP)+8位位移。
22.①.ret:修改IP中的内容,近转移,执行后(IP)=((ss)*16+(sp)),(sp)=(sp)+2,相当于pop IP;
②.retf:修改CS和IP的内容,远转移,执行后(IP)=((ss)*16+(sp)),(sp)=(sp)+2,(CS)=((ss)*16+(sp)),(sp)=(sp)+2,相当于pop IP,pop CS;
call指令(call指令均为远转移)
① .依据位移进行转移的call指令 call 标号:执行后(sp)=(sp)-2,((ss)*16+(sp))=(IP),(IP)=(IP)+16位位移,相当于push IP,jmp near ptr 标号;PS:在执行CALL指令时,IP的值先变成CALL指令后的第一个字节的偏移地址,然后才被压入栈。
② .转移的目的地址在指令中的call指令 call far ptr 标号:段间转移,执行后
(sp)=(sp)-2,((ss)*16+(sp))=(CS),(sp)=(sp)-2,((ss)*16+(sp))=(IP),(CS)=标号所在段的段地址,(IP)=标号在段中的偏移地址,相当于 push CS,
push IP,jmp far ptr 标号。
③ .转移地址在寄存器中的call指令 call 16位reg:执行时(sp)=(sp)-2,((ss)*16+(sp))=(IP),(IP)=(16位reg),相当于push IP,jmp 16位reg;
④ .转移地址在内存中的call指令 call:
① .call word ptr 内存单元地址:相当于push IP,jmp word ptr 内存单元地址;
② .call dword ptr 内存单元地址:相当于push CS,push IP,jmp dword ptr 内存单元地址
23.
ZF是flag的第6位,零标志位,记录指令执行后结果是否为0,结果为0,ZF=1;
PF是flag的第2位,奇偶标志位,记录指令执行后结果二进制数中1的个数是否为偶数,结果为偶数时,PF=1;
SF是flag的第7位,符号标志位,记录有符号运算结果是否为负数,结果为负数时,SF=1;
CF是flag的第0位,进位标志位,记录无符号运算结果是否有进/借位,结果有进/借位时,SF=1;
OF是flag的第11位,溢出标志位,记录有符号运算结果是否溢出,结果溢出时,0F=1;
add、sub、 mul、div、inc、or、and、loop等运算指令影响flag;
mov、push、 pop 等传送指令对flag没影响;
adc指令:带进位加法指令。指令格式:adc 操作对象1,操作对象2。功能:操作对象1=操作对象1+操作对象2+CF。
如指令adc ax,bx实现的功能为:(ax)=(ax)+(bx)+CF。
sbb指令:带借位减法指令,利用了CF位上记录的借位值。指令格式:sbb 操作对象1,操作对象2。
功能:操作对象1=操作对象1-操作对象2-CF,如指令sbb ax,bx 实现的功能为:(ax)=(ax)-(bx)-CF。
cmp指令:比较指令,相当于减法指令,但不保存结果,对标志寄存器产生影响。指令格式:cmp 操作对象1,操作对象2。
功能:计算操作对象1-操作对象2,但不保存结果,根据结果对标志寄存器进行设置。
检测比较结果的条件转移指令:所有条件转移指令的转移位移都是[-128,127]。
根据cmp指令的比较结果进行转移的指令分为两种,即根据无符号数的比较结果进行转移的条件转移指令(检测ZF和CF的值)和根据有符号数的比较结果进行转移的条件转移指令(检测SF、OF和ZF的值)。
形如高级语言中的if语句
常见的根据无符号数的比较结果进行转移的条件转移指令:
指令 相对应单词 含义 对应符号 检测的相关标志位
je equal 等于则转移 = ZF=1
jne not equal 不等于则转移 ≠ ZF=0
jb below 低于则转移 < CF=1
jnb not below 不低于则转移 ≥ CF=0
ja above 高于则转移 > CF=0且ZF=0
jna not above 不高于则转移 ≤ CF=1或ZF=1
第十二章 内中断
程序步骤:
① . 编写中断处理程序;
② . 将中断处理程序传送到内存0000: 0200处;
③ .将中断处理程序的入口地址0000: 0200存储在中断向量表对应N号中。















 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









