






希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因DL.Shell于1959年提出而得名。希尔排序是记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
我们分割待排序记录的目的是减少待排序记录的个数,并使整个序列向基本有序发展。而如上面这样分完组后,就各自排序的方法达不到我们的要求。因此,我们需要采取跳跃分割的策略:将相距某个“增量”的记录组成一个子序列,这样才能保证在子序列内分别进行直接插入排序后得到的结果是基本有序而不是局部有序。
1. 算法步骤
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
操作流程图:

操作步骤:
初始时,有一个大小为 10 的无序序列。
(1)在第一趟排序中,我们不妨设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。
(2)接下来,按照直接插入排序的方法对每个组进行排序。
在第二趟排序中,我们把上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为 2 组。
(3)按照直接插入排序的方法对每个组进行排序。
(4)在第三趟排序中,再次把 gap 缩小一半,即gap3 = gap2 / 2 = 1。 这样相隔距离为 1 的元素组成一组,即只有一组。
(5)按照直接插入排序的方法对每个组进行排序。此时,排序已经结束。
2. 动图演示
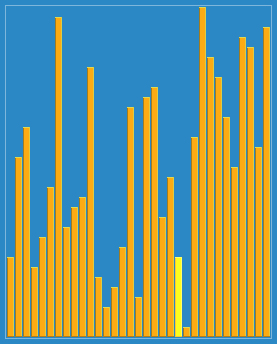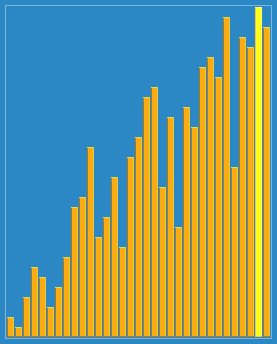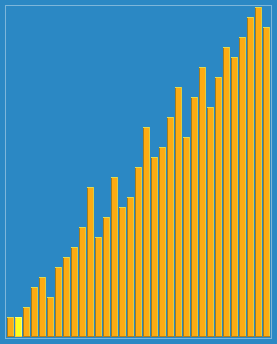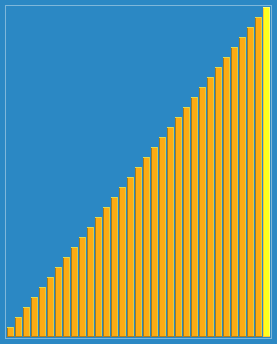
3.源代码
public class ShellSort {
// 我们的算法类不允许产生任何实例
private ShellSort(){}
public static void sort(Comparable[] arr){
int n = arr.length;
// 计算 increment sequence: 1, 4, 13, 40, 121, 364, 1093...
int gap = 1;
while (gap < n/3)
gap = 3*gap + 1;
//初始化增量gap,采用{n/3,(n/3)/3...1}这一增量序列,其性能优于{n/2,(n/2)/2...1}
while (gap >= 1) {
// h-sort the array
for (int i = gap; i < n; i++) {
// 对 arr[i], arr[i-gap], arr[i-2*gap], arr[i-3*gap]... 使用插入排序
Comparable e = arr[i];
int j = i;
for ( ; j >= gap && e.compareTo(arr[j-gap]) < 0 ; j -= gap)
arr[j] = arr[j-gap];
arr[j] = e;
}
gap /= 3;
}
}
}
4.效率分析
时间复杂度:
最好情况:由于希尔排序的好坏和步长gap的选择有很多关系,因此,目前还没有得出最好的步长如何选择(现在有些比较好的选择了,但不确定是否是最好的)。所以,不知道最好的情况下的算法时间复杂度。
最坏情况下:O(N*logN),最坏的情况下和平均情况下差不多。
已知的最好步长序列是由Sedgewick提出的(1, 5, 19, 41, 109,…)。
这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
空间复杂度
由直接插入排序算法可知,我们在排序过程中,需要一个临时变量存储要插入的值,所以空间复杂度为1。
算法稳定性
希尔排序中相等数据可能会交换位置,所以希尔排序是不稳定的算法。
和其他算法进行比较
我们分别取乱序和近乎有序的两组数据来进行测试
1.乱序数组
测试代码
public static void main(String[] args){
Integer[] arr1 = SortTestHelper.generateRandomArray(100000,1,100000);
Integer[] arr2 = Arrays.copyOf(arr1,arr1.length);
Integer[] arr3 = Arrays.copyOf(arr1,arr1.length);
Integer[] arr4 = Arrays.copyOf(arr1,arr1.length);
SortTestHelper.testSort("com.company.InsertionSort",arr1);
System.out.println();
SortTestHelper.testSort("com.company.ShellSort",arr2);
System.out.println();
SortTestHelper.testSort("com.company.BubbleSort",arr3);
System.out.println();
SortTestHelper.testSort("com.company.SelectionSort",arr4);
}
测试结果

可以看出希尔排序的效率远远优于几种O(n2)级别的排序算法
2. 接近有序的数组
测试代码
public static void main(String[] args){
Integer[] arr1 = SortTestHelper.generateNearlyOrderedArray(100000,100);
Integer[] arr2 = Arrays.copyOf(arr1,arr1.length);
Integer[] arr3 = Arrays.copyOf(arr1,arr1.length);
Integer[] arr4 = Arrays.copyOf(arr1,arr1.length);
SortTestHelper.testSort("com.company.InsertionSort",arr1);
System.out.println();
SortTestHelper.testSort("com.company.ShellSort",arr2);
System.out.println();
SortTestHelper.testSort("com.company.BubbleSort",arr3);
System.out.println();
SortTestHelper.testSort("com.company.SelectionSort",arr4);
}
测试结果

可以看出在处理有序数组时希尔排序保留了插入排序的优势,在两种情况下表现都很优秀。















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









