







K-means
概念
K-means算法是一种无监督学习的聚类算法,也叫做K均值聚类,通过均值的计算,对样本分为K个不同的簇。
距离度量
使用K-means算法时,样本的距离度量必须满足一定的条件:

对样本属性的距离度量计算时,可以采取不同的距离度量公式,

k-means一般采用p=2时,也就是欧式距离。
迭代计算
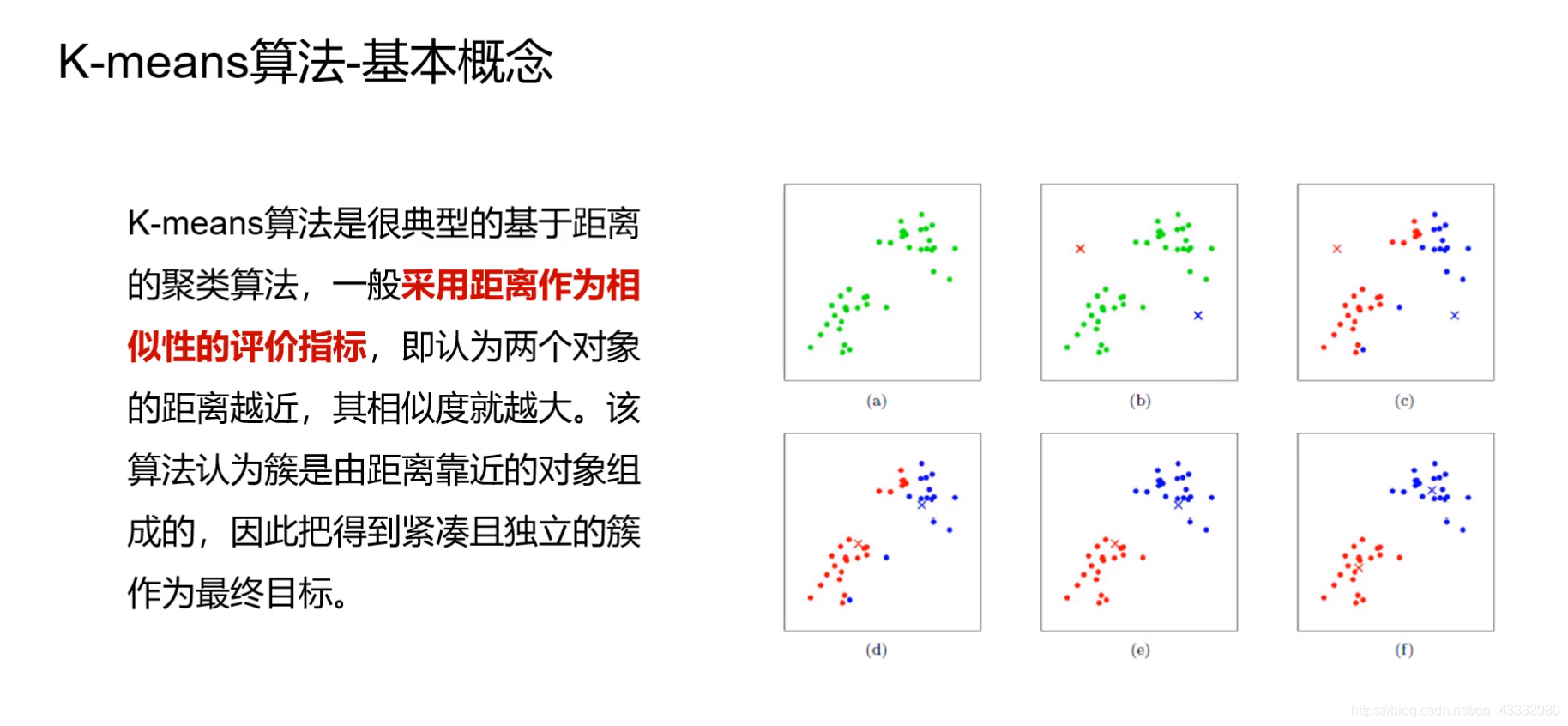
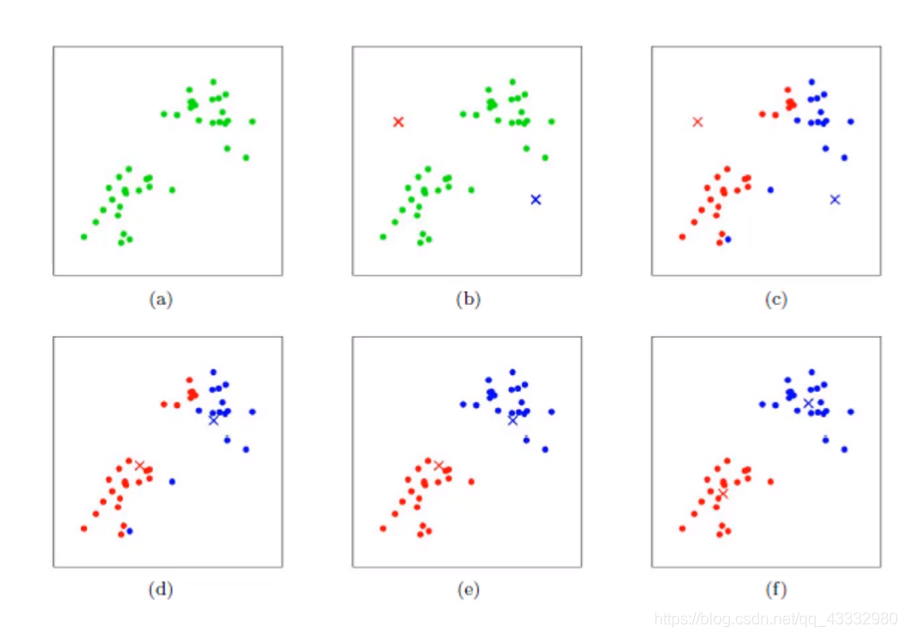
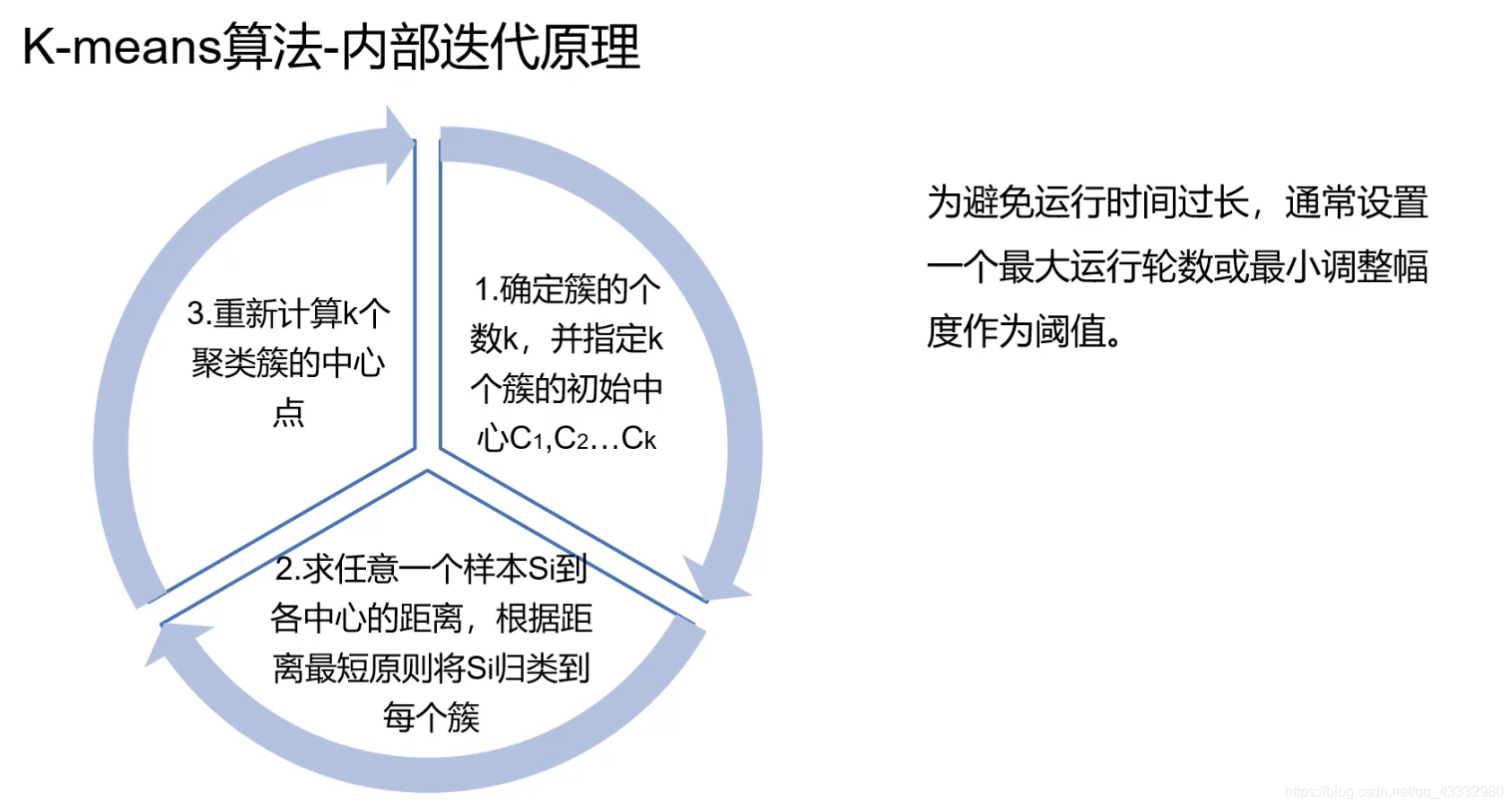
在进行聚类时,要先确定簇的个数k,然后进行下面操作:
- 指定k个簇的初始化中心C1,C2,C3…Ck。 ( b )
- 求每个样本到各个中心的距离,并将其划分到距离最小的中心的簇中。( c )
- 对划分的每个簇重新计算簇中心。( d )
- 如果簇中心发生变化则回到第2步 ( e ),否则达到迭代次数或者中心变化幅度过低可认为完成聚类退出。( f )
聚类评估方法
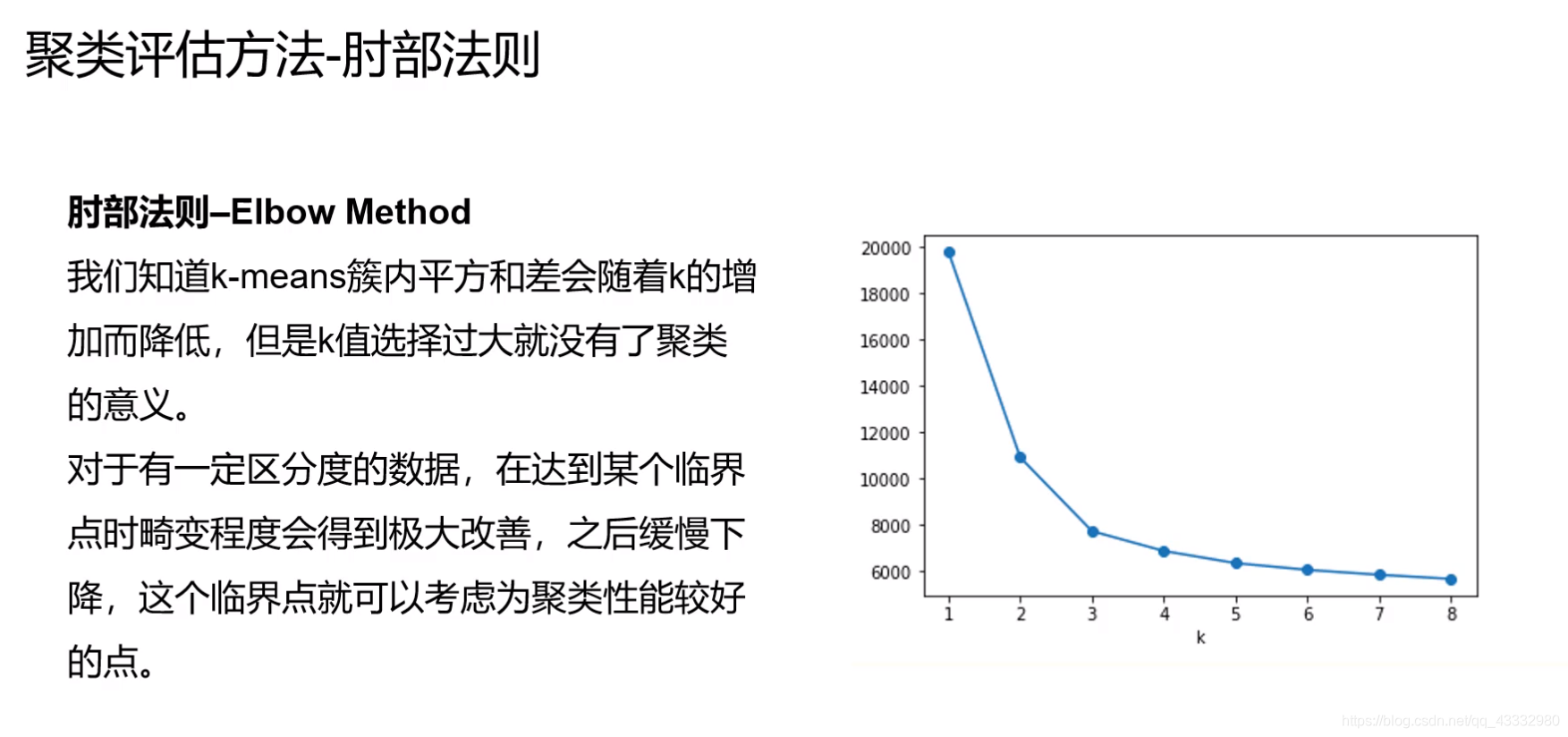
簇内平方和

簇内平方和会随着k的增加而降低,所以对于k的选取则需要采取一定的策略,肘部法则
轮廓系数

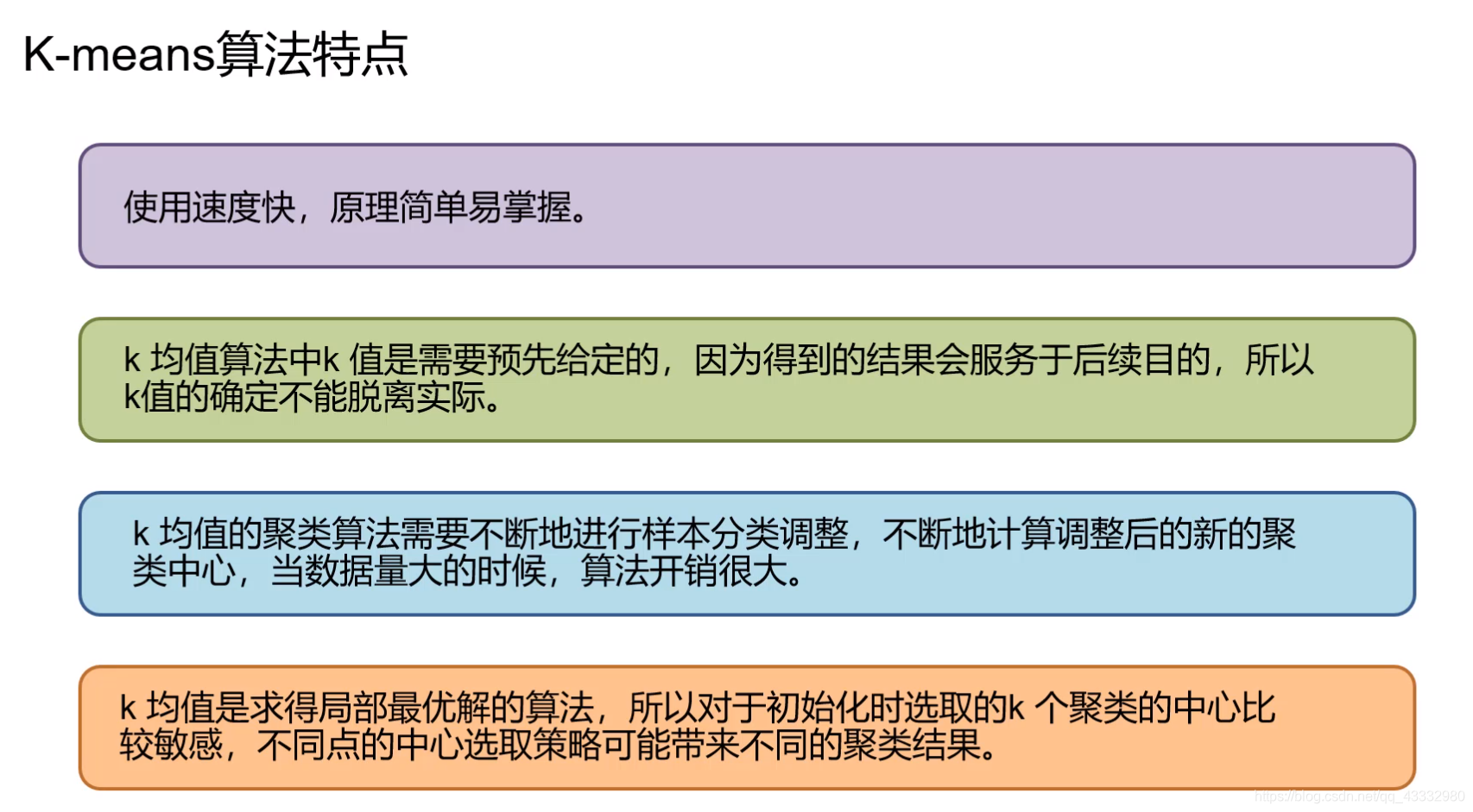
特点
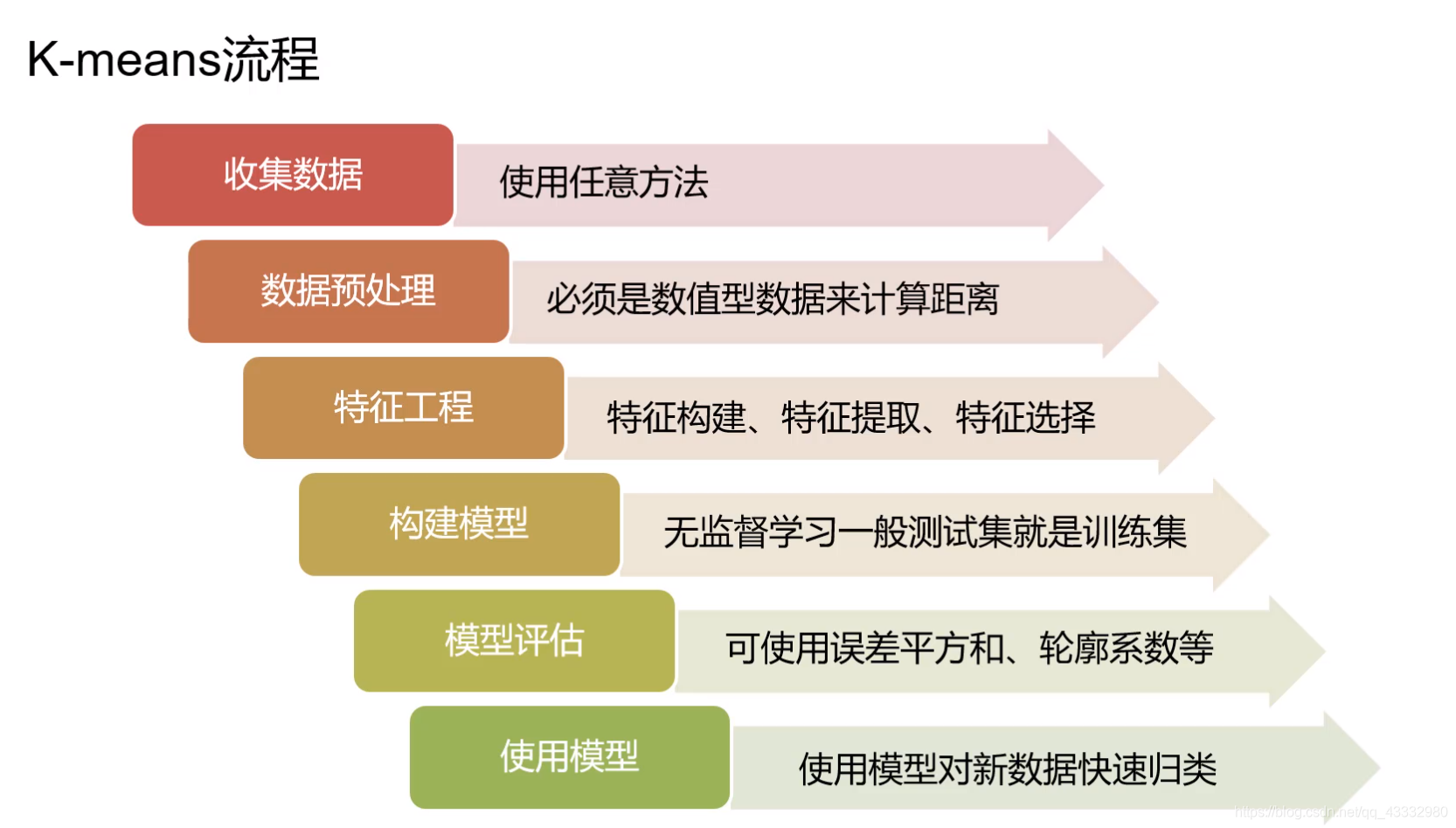
使用

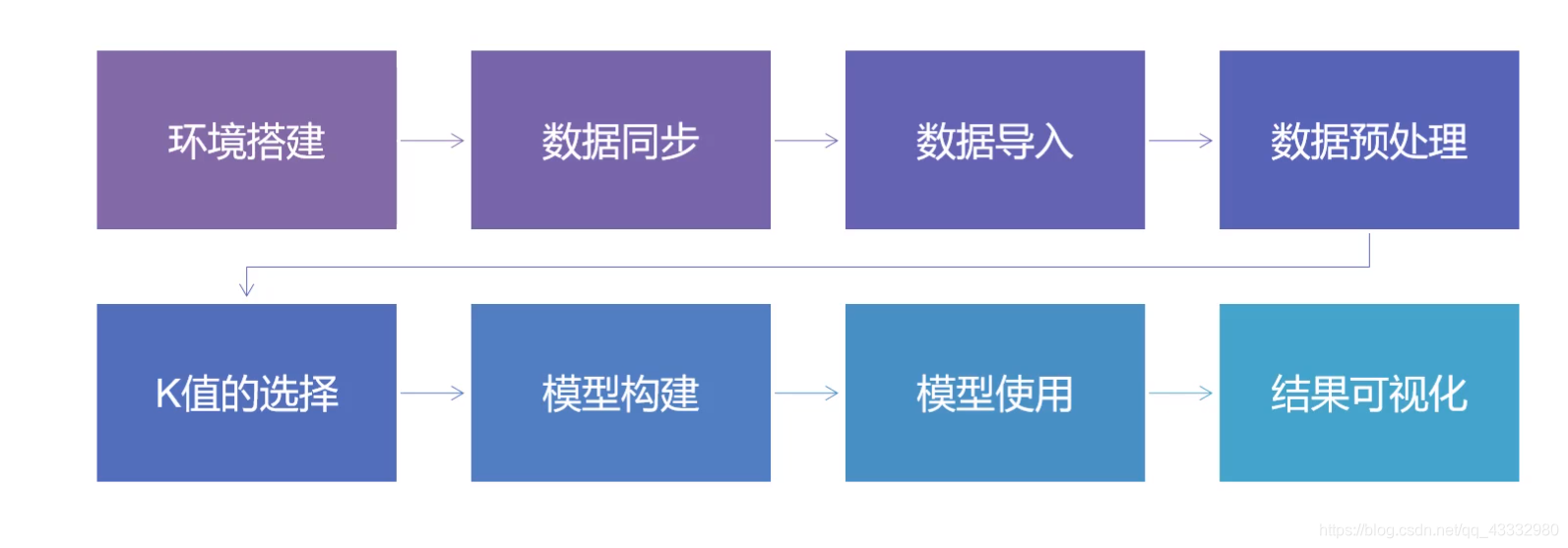
实战开发
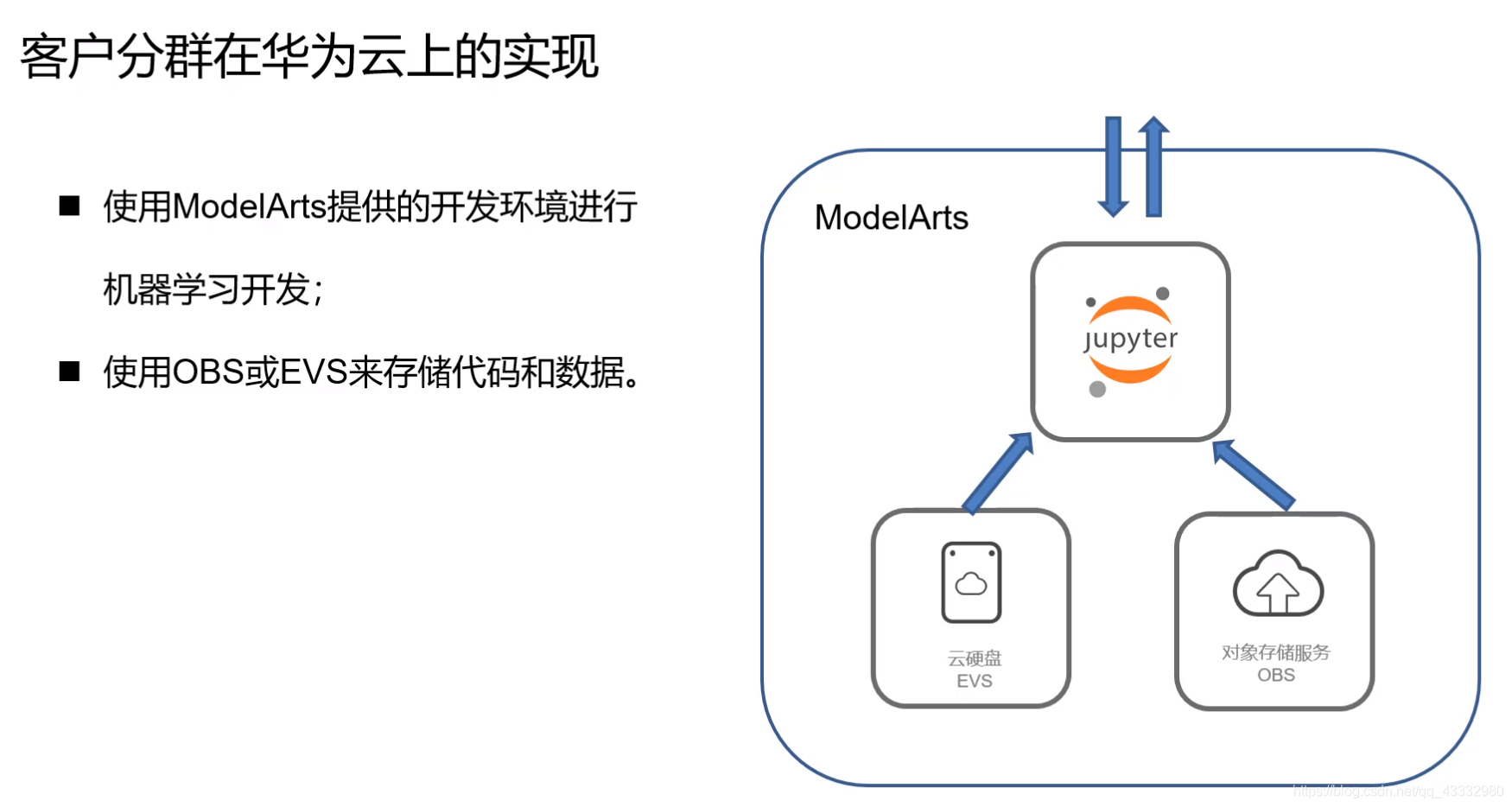
下面介绍需要使用到的工具:
华为云 ModelArts
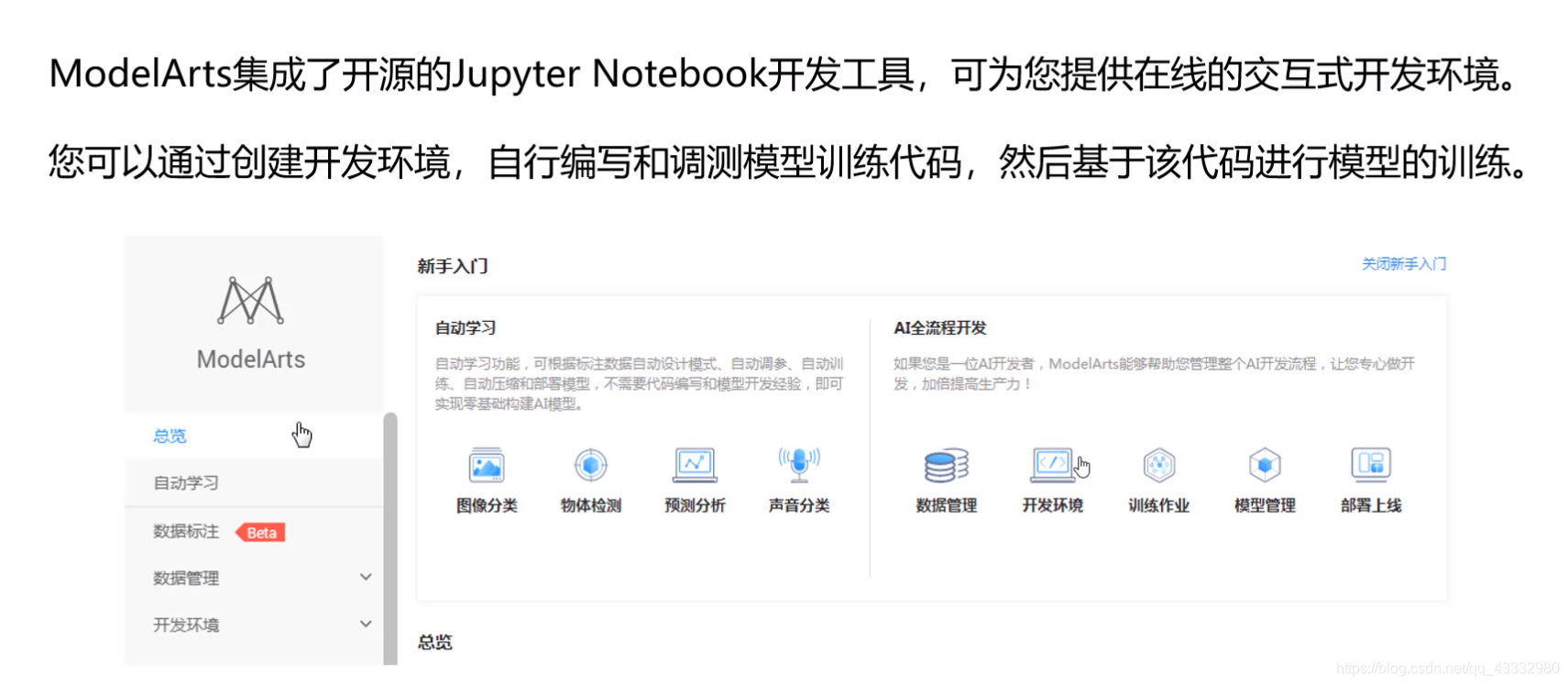
Jupyter Notebook

OBS对象存储

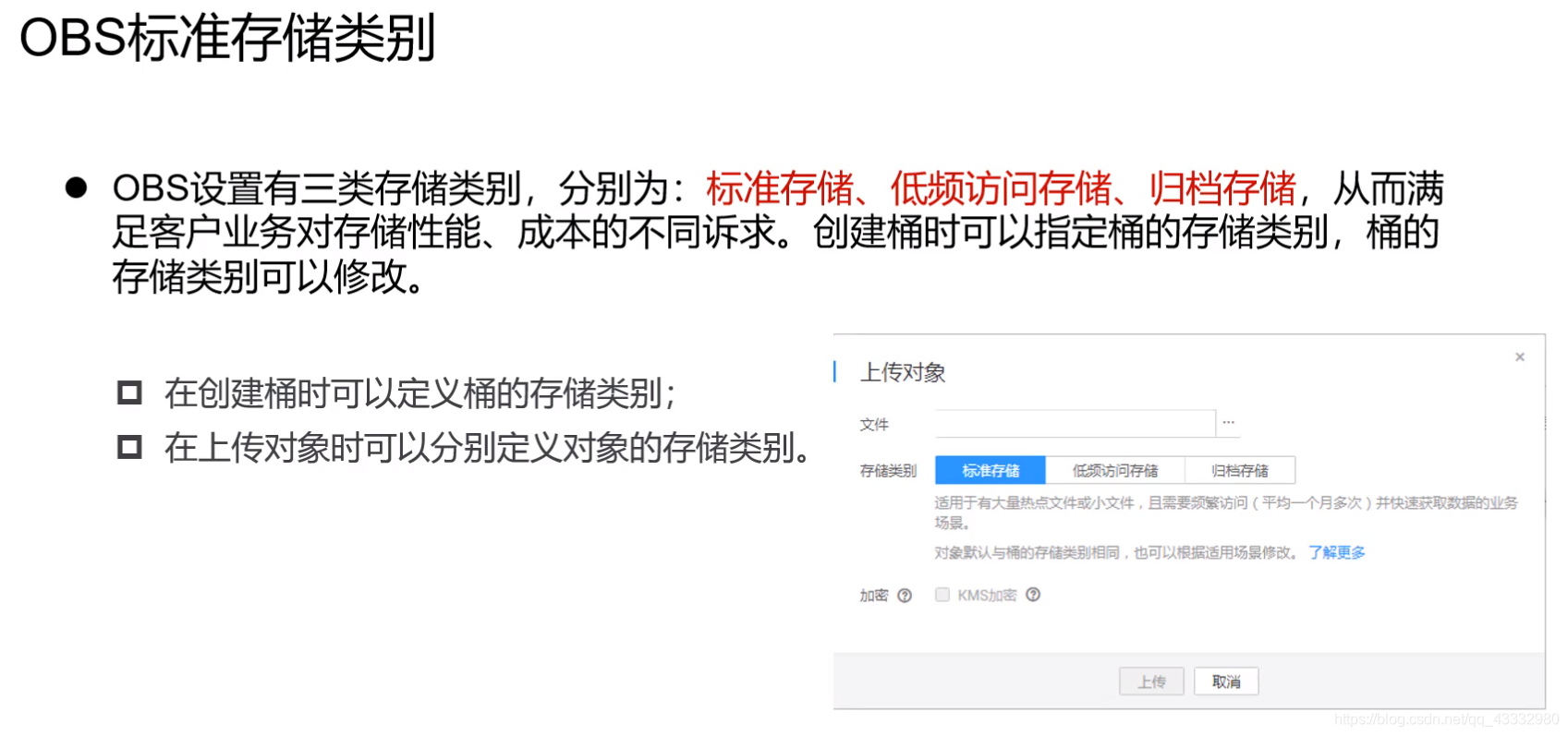
实操
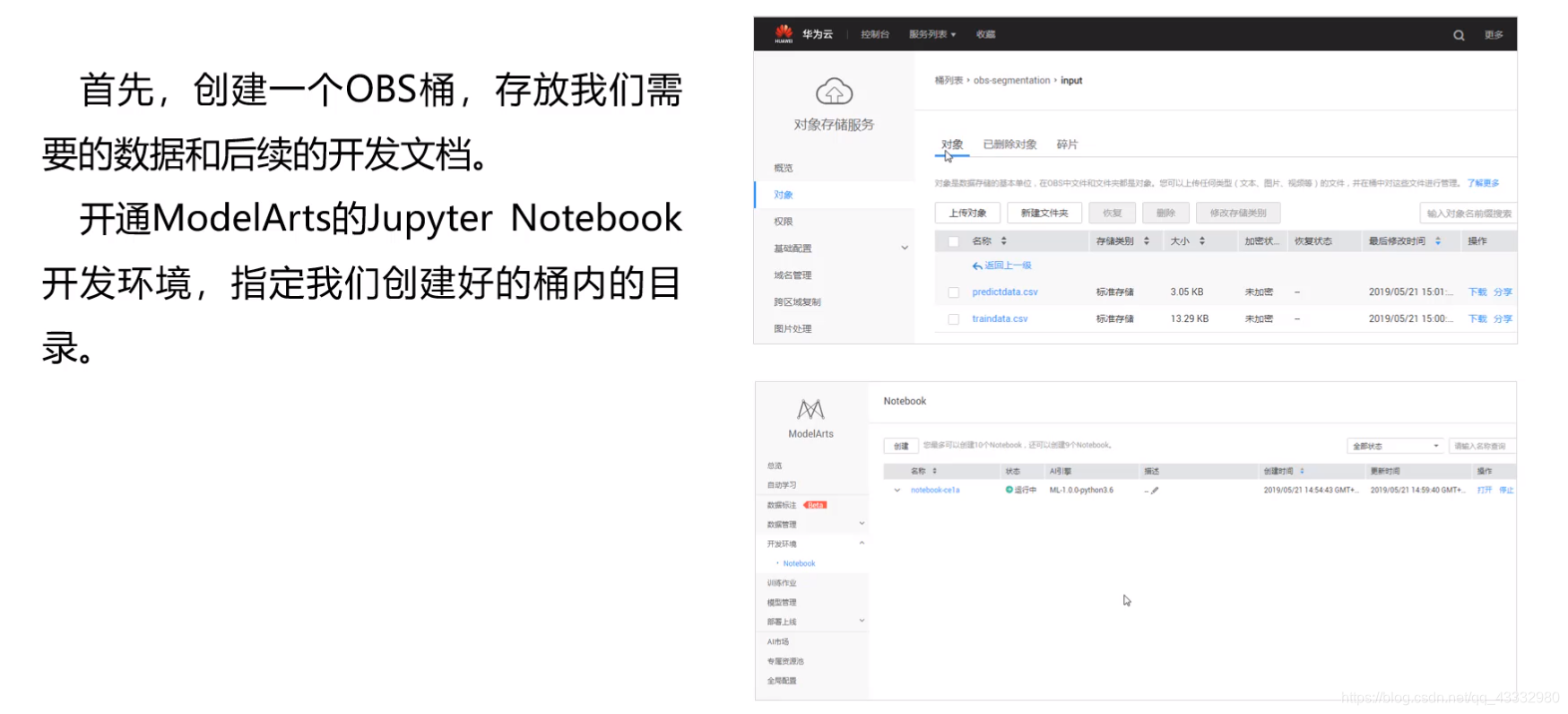
环境搭建
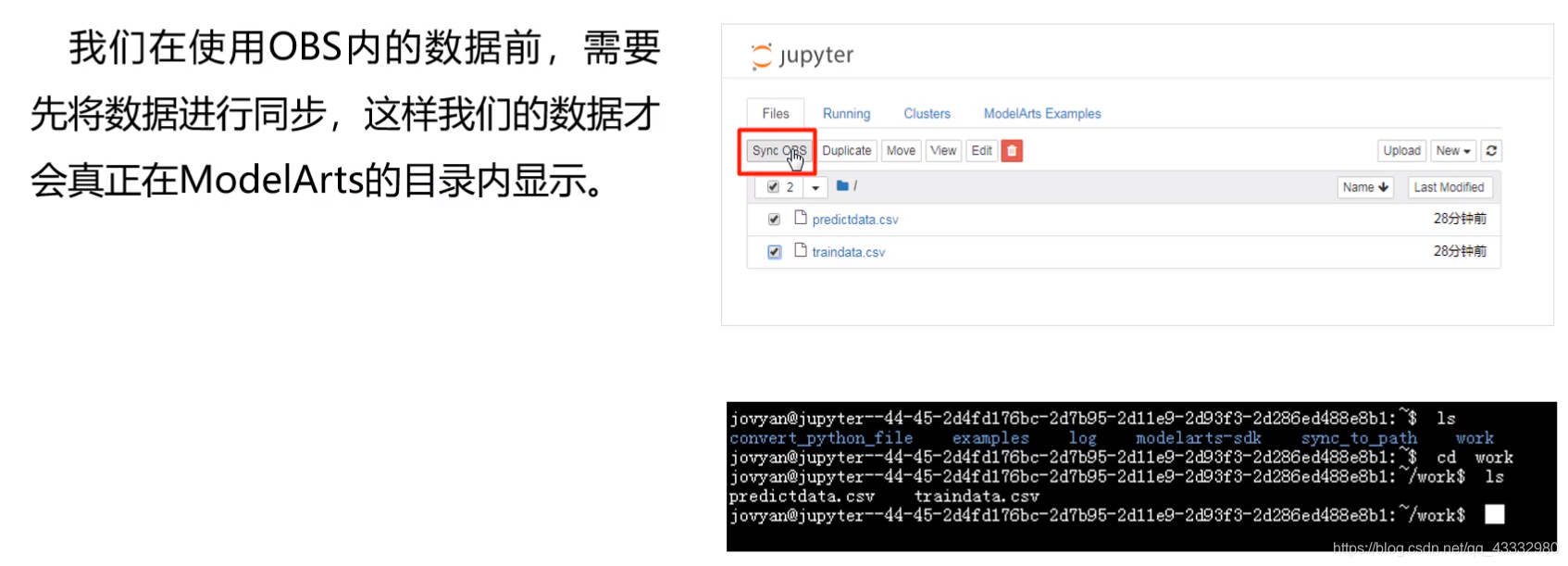
数据同步
数据导入

数据预处理

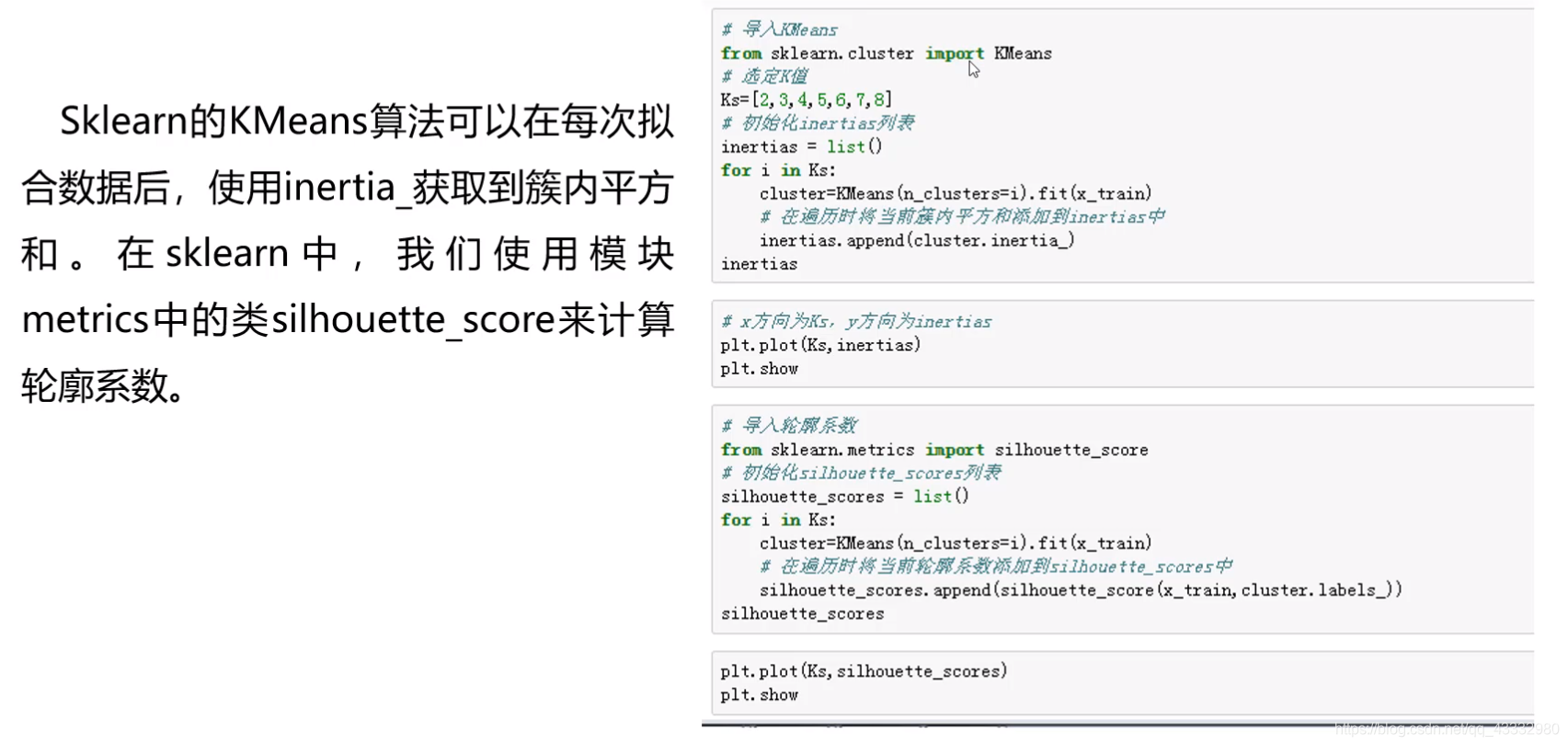
K值的选择
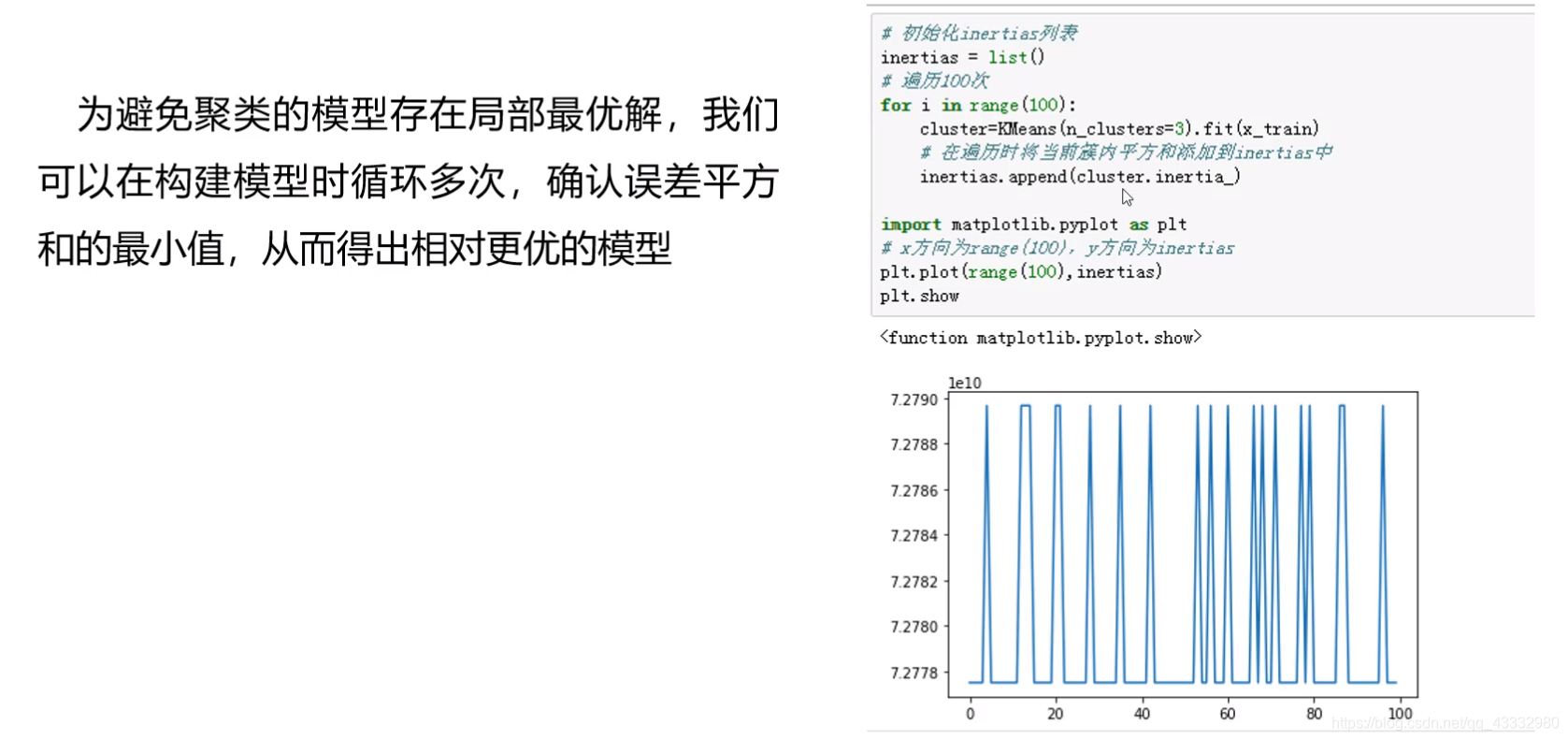
模型的构建
模型的使用

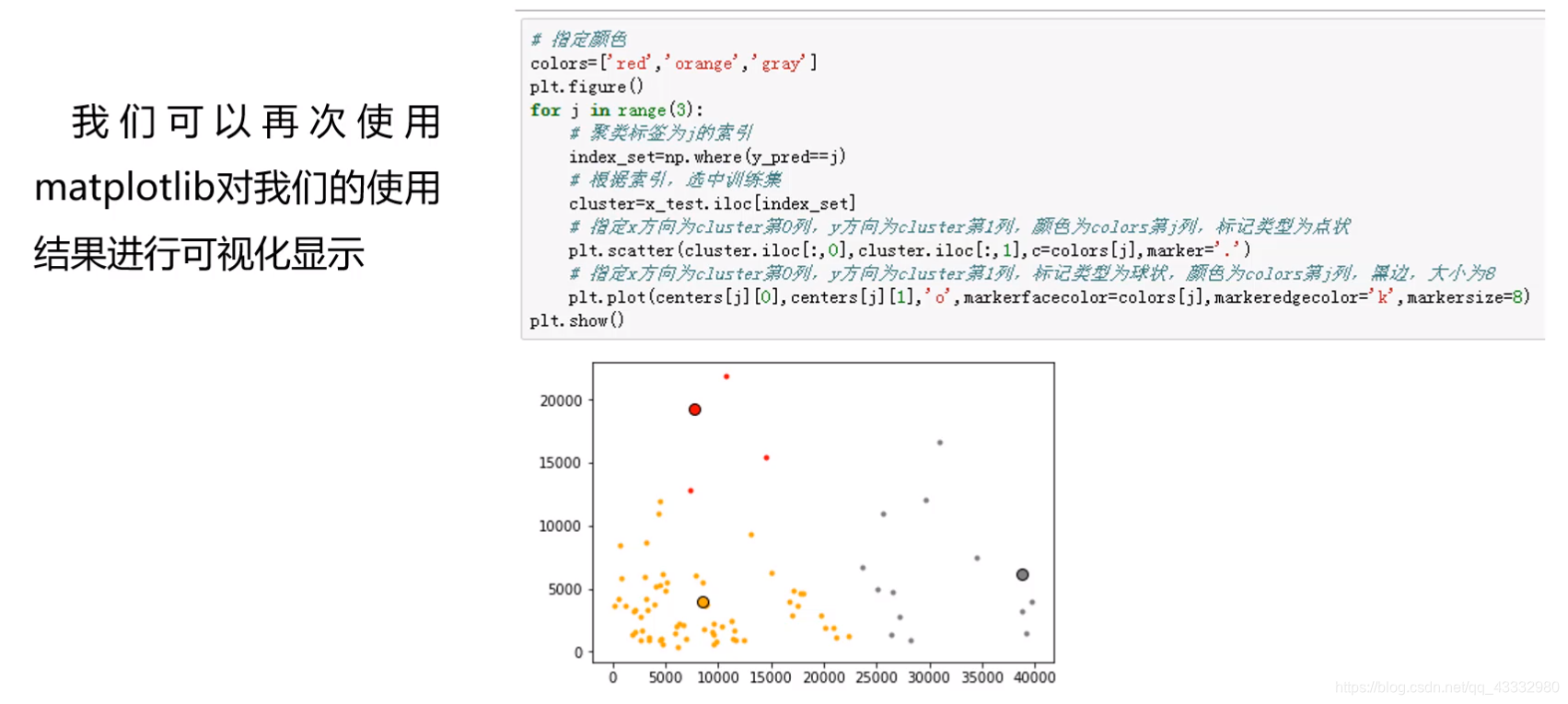
结果可视化


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









