







查找
8.1 查找的相关概念
查找:在数据集合中寻找满足某种条件的数据元素的过程称为查找
查找表(查找结构):用于查找的数据集合称为查找表,它由同一类型的数据元素(或记录)组成
关键字:数据元素中唯一标识该元素的某个数据项的值,使用基于关键字的查找,查找结果应该是唯一的。
静态查找表:只需要进行数据元素的查找操作,仅关注查找速度即可
动态查找表:不但需要进行数据元素的查找,也需要对数据元素进行增删操作,除了查找速度,也要关注插/删操作是否方便实现。
8.2 顺序表的查找
8.2.1 查找方式
从头到脚(或者从脚到头)挨个找
适用于顺序表、链表,表中元素有序无序都可以
8.2.2 实现代码
typedef struct{//查找表的数据结构(顺序表)
ElemType *elem;//动态数组基址
int TableLen;//表的长度
}SSTable;
//顺序查找
int Search_Seq(sSTable ST,ElemType key){
int i;
for( i=0; i<ST.TableLen && ST.elem[i] !=key; ++i);
//查找成功,则返回元素下标;查找失败,则返回-1
return i==ST.TableLen? -1 : i;
}
也可在0号位置存“哨兵”,从尾部向头部挨个查找优点:循环时无需判断下标是否越界。
//顺序查找
int Search_Seq(sSTable ST,ElemType key){
ST.elem[0]=key;//“哨兵”
int i;
for(i=ST.TableLen;ST.elem[i] !=key;--i);
//从后往前找
return i;
//查找成功,则返回元素下标;查找失败,则返回0
}
8.2.3 算法优化
第一种
可以把所查找的表改进成有序表
优点:查找失败时ASL更少
成功结点的关键字对比次数=结点所在层数
失败结点的关键字对比次数=其父节点所在层数
默认情况下,各种失败情况或成功情况都等概率发生
第二种
若各个关键字被查找的概率不同,可按被查概率降序排列
优点:查找成功时ASL更少
8.2.4 时间复杂度:O(n)
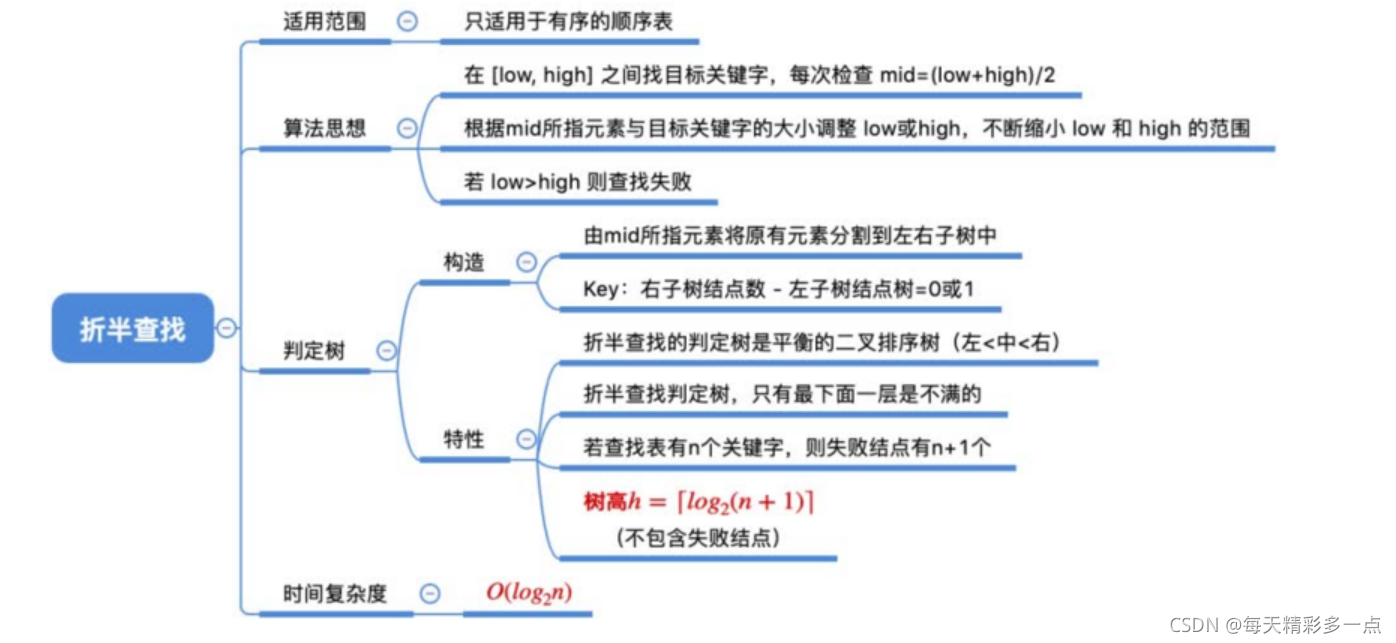
8.3 折半查找法
8.3.1 代码实现
//折半查找
typedef struct{//查找表的数据结构(顺序表)
ElemType *elem;//动态数组基址
int TableLen;//表的长度
}SSTable;
int Binary_Search(SSTable L,ElemType key){
int low=0,high=L.TableLen-1,mid;
while(low<=high){
mid=(low+high)/2;//取中间位置
if(L.elem [mid]==key)
return mid;//查找成功则返回所在位置
else if(L.elem[mid]>key)
high=mid-1;//从前半部分继续查找
else
low=mid+1;//从后半部分继续查找
}
return -1;//查找失败,返回-1
}
8.3.2 总结
8.4 分块查找
8.4.1 具体实现
分块查找需要建立“索引表",其中保存每个分块的最大关键字和分块的存储区间。
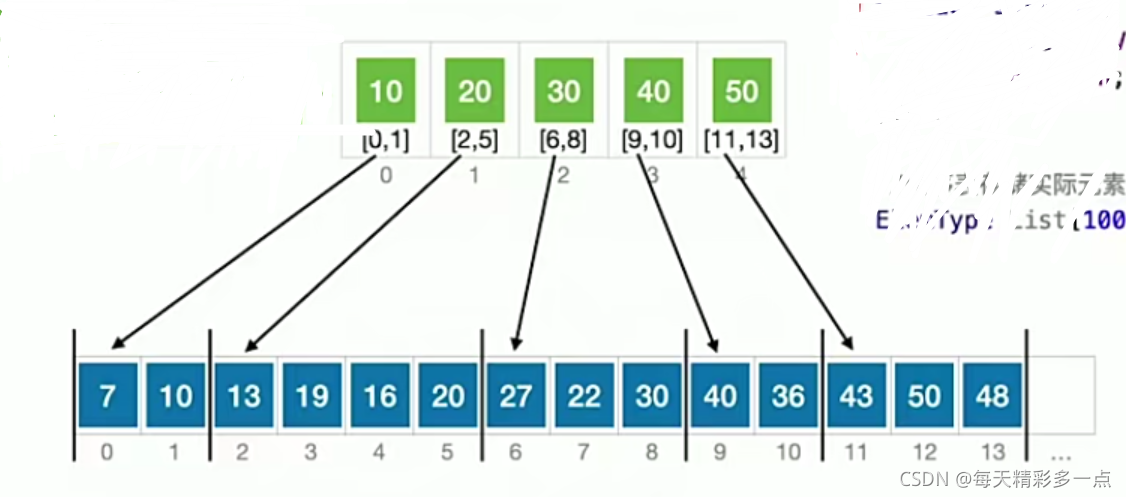
特点:块内无序,块间有序
分块查找,又称索引顺序查找,算法过程如下:
①在索引费中确定待查记录所属的分块(可顺序、可折半)
②在块内顺序查找
若索引表中不包含目标关键字,则折半查找索引表最终停在(low>high)要在low所指分块中查找
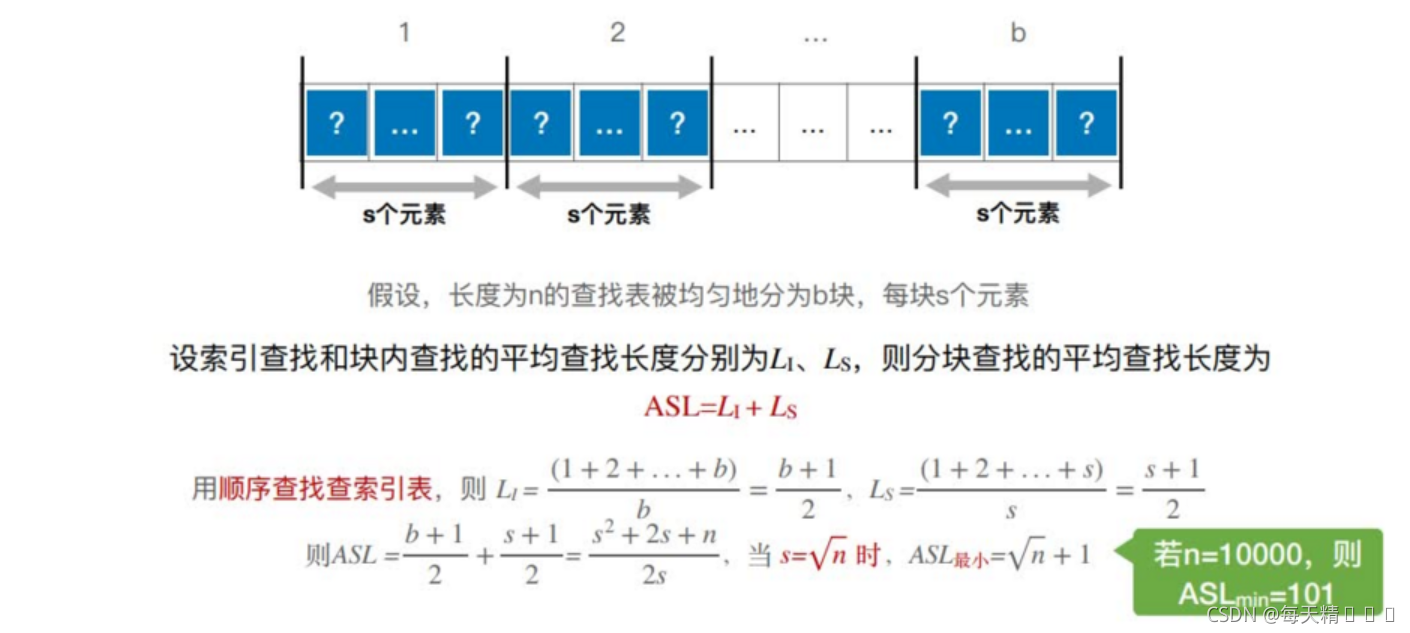
8.4.2 效率分析
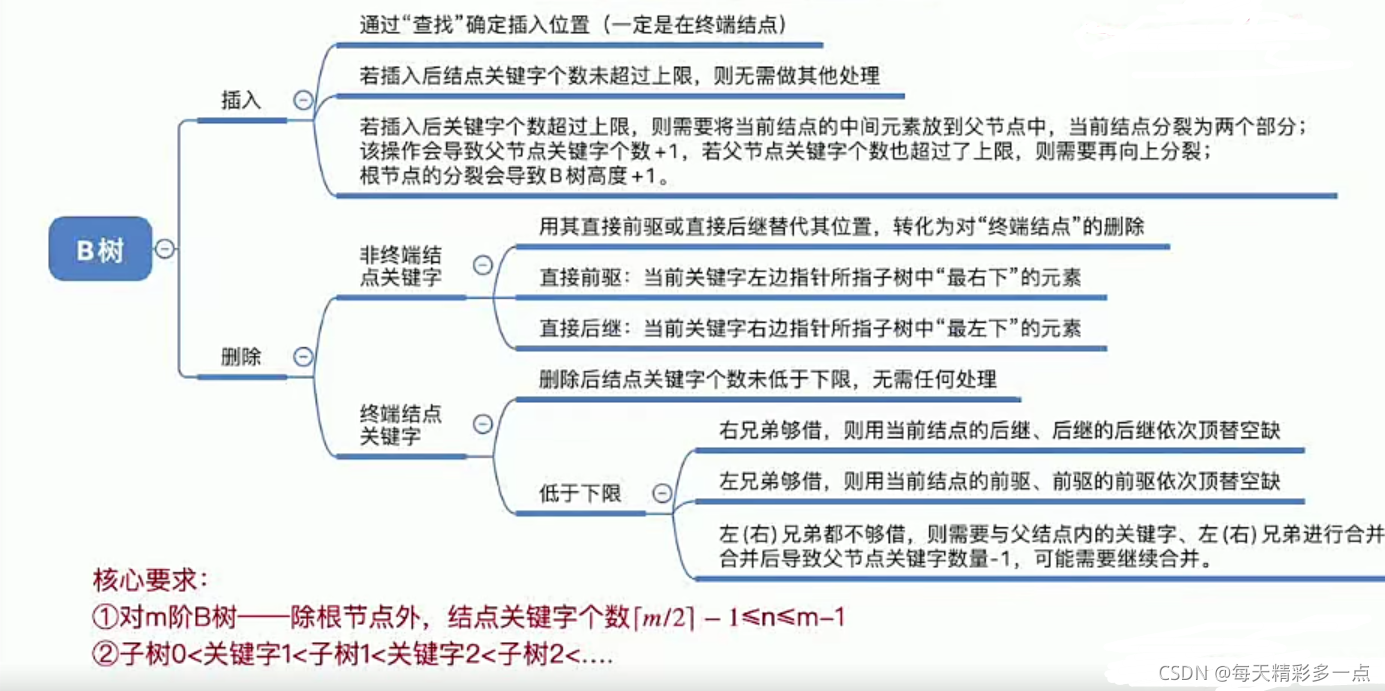
8.5 B树
8.6 散列查找
8.6.1 基本概念
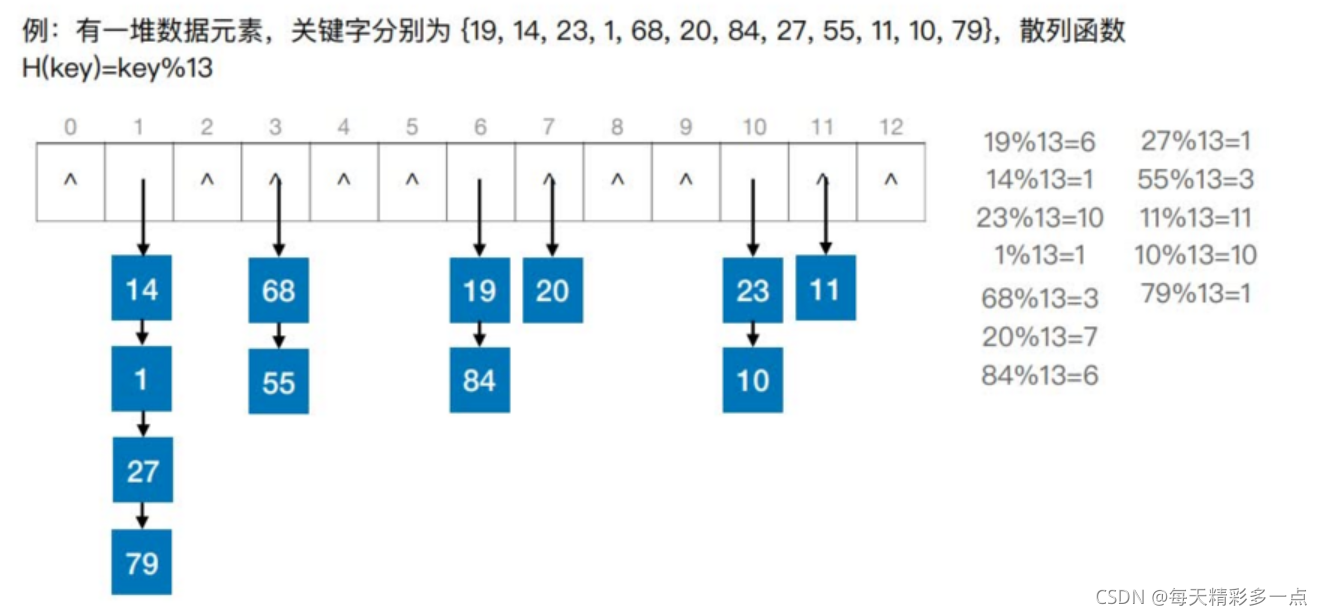
散列表(Hash Table),又称哈希表。是一种数据结构,特点是,数据元素的关键字与其存储地址直接相关
通过“散列函数(哈希函数)”: Addr=H(key)来建立关键字和其存储地址的联系。
同义词:若不同的关键字通过散列函数映射到同一个值
“冲突":通过散列函数确定的位置已经存放了其他元素
查找长度:在查找运算中,需要对比关键字的次数称为查找长度
8.6.2 处理冲突的方法
1.拉链法
把所有同义词放在一个链表中存储
上图的平均查找长度:
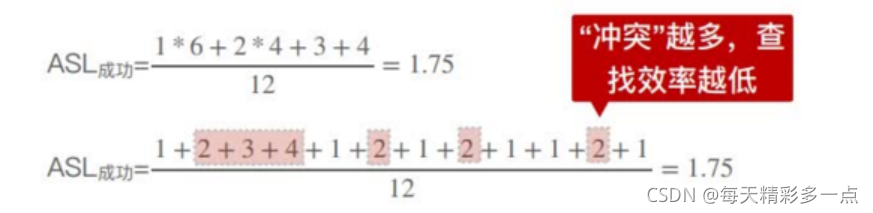

2. 开放定址法
是指可存放新表项的空闲地址既向它的同义词表项开放,又向它的非同义词表项开放。
其数学递推公式为:
Hi= (H(key) + di) %m
i = 0, 1, 2,…, k(k ≤ m-1),m表示散列表表长;di为增量序列;i可理解为“第i次发生冲突”
①线性探测法
di= 0, 1, 2, 3, …, m-1;
即发生冲突时,每次往后探测相邻的下⼀个单元是否为空
H(key)=1%13=1
H0=(1+d0)%16=1—冲突–>H1=(1+d1)%16=2
注意:
采用“开放定址法”时,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填⼊散列表的同义词结点的查找路径,可以做⼀个“删除标记”,进行逻辑删除
线性探测法很容易造成同义词、非同义词的“聚集(堆积)”现象,严重影响查找效率
产生原因:冲突后再探测⼀定是放在某个连续的位置
②平方探测法。
当di= 02, 12, -12, 22, -22, …, k2, -k2时,称为平方探测法,又称二次探测法,其中k≤m/2。
平方探测法:比起线性探测法更不易产⽣“聚集(堆积)”问题。
③伪随机序列法。
di是⼀个伪随机序列,如di= 0, 5, 24, 11, …
3. 再散列法
8.6.3 常见的哈希函数
设计目标:让不同关键字的冲突尽可能地少
1. 除留余数法
H(key) = key % p
散列表表长为m,取一个不大于m但最接近或等于m的质数p
2.直接定址法
H(key) = key 或 H(key) = a*key + b
其中,a和b是常数。这种方法计算最简单,且不会产生冲突。它适合关键字的分布基本连续的情况,若关键字分布不连续,空位较多,则会造成存储空间的浪费。
3.数字分析法
选取数码分布较为均匀的若干位作为散列地址
设关键字是r进制数(如十进制数),而r个数码在各位上出现的频率不⼀定相同,可能在某些位上分布均匀⼀些,每种数码出现的机会均等;而在某些位上分布不均匀,只有某几种数码经常出现,此时可选取数码分布较为均匀的若干位作为散列地址。这种方法适合于已知的关键字集合,若更换了关键字,则需要重新构造新的散列函数。
4.平方取中法
取关键字的平方值的中间几位作为散列地址。
具体取多少位要视实际情况而定。这种方法得到的散列地址与关键字的每位都有关系,因此使得散列地址分布比较均匀,适用于关键字的每位取值都不够均匀或均小于散列地址所需的位数。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









