







 本文介绍了一个Python情感分析项目,包括准备工作、情感词库、程度副词和否定词列表的使用。项目利用jieba库进行分词,通过判断情感词、程度副词和否定词来确定情感极性,并应用K-近邻算法思想解决二义性问题。文章提供代码实现,并分享了项目的百度网盘和Gitee下载链接。
本文介绍了一个Python情感分析项目,包括准备工作、情感词库、程度副词和否定词列表的使用。项目利用jieba库进行分词,通过判断情感词、程度副词和否定词来确定情感极性,并应用K-近邻算法思想解决二义性问题。文章提供代码实现,并分享了项目的百度网盘和Gitee下载链接。
前言
为什么要写这篇文章?
前段时间帮人写了一个这样的小项目,在网上查找资料的过程中,有不少关于该项目的资料,由于各个博主写的代码不尽相同,且没有一个详尽的分析方法,所以我在完成该项目后,想到可以把该项目的分析方法写出来,供大家学习。
> 2021/6/14日更新:最下面有百度网盘的下载链接和提取码。
> 另外我还上传到了gitee,可以直接下载压缩文件在解压,打开项目即可。
准备工作及环境
工具:pycharm、python 3.8.6
其他:大连理工大学情感词汇本体(excel)、程度副词(excel)、否定词列表(txt)
大连理工大学情感词汇下载地址:https://github.com/ZaneMuir/DLUT-Emotionontology
程度副词采用三个等级:1, 1.5, 2
后续会把项目上传到我的资源,如果没有下载积分可以留邮箱,我可以把整个项目发送过去。
项目分析
相信打开这篇文章的同学对情感分析有一定的了解,这里就简单阐述下中文情感分析的大概思路(基个人思路):
jieba库进行分词 – > 分词后,一个词一个词分析是否在情感词表中 --> 如果存在,则在该情感词前寻找是否有程度副词和否定词 --> 如果有,则对该情感词进行处理。
情感倾向的数学表达式:

要点1:一个情感词可能会有不同的情感极性(消极或是积极),例如情感词:八面玲珑。改成语具有褒贬两个不同的情感极性,在有的句子中是褒义,有的却是贬义,那么该情感词如何确定极性呢?这里我引入了K-近邻算法中的思想:
对于这种具有两种不同极性的词语,它的极性由前后各四个情感值的极性来确定,且前四个占比75%,后四个占比25%,得出两个结果之和,在计算该情感值两个极性(一般都是由两个极性构成,且都是数字,例如0(中性),-1(消极))离这个结果的绝对距离的大小,小的则表示该情感词极性更接近该极性,那么就可以确定该极性。
例如前四个结果为2,后四个结果为-1,相加之和:1,该情感词具有两个极性分别为1和-1,算绝对距离为0和2,0<2,所以可以确定该词的极性为中性(0)
为什么这么做?可以这么理解:在一段文字中,所具有的情感大概率是一致的,就比如你在夸奖某个人,即便你夸奖的词语中出现了一个不确定情感的词,那么因为你大篇幅都是在夸奖ta,所以你这个词大概率也是在夸奖(积极的)他,而不是在阴阳怪气(消极的)。
要点2:双重否定为肯定,或者换个说法:奇数个否定词为否定,偶数个否定词为肯定。所以在计算否定词的时候,不是直接赋值为-1,而是要根据否定词的个数来,所以应该是 W3 *= -1
整个项目代码
import jieba
import re
import math
from openpyxl import load_workbook
negative_file = '否定词.txt'
adv_file = '程度副词.xlsx'
emotional_file = '情感词汇本体.xlsx'
test_file = '测试文章.txt'
alpha = 0.75 # 不确定的情感值极性前后判断因素的比例,默认为0.75
'''
判断情感词极性,传入参数:情感词,情感字典
判断依据:情感分为0, 1, -1, 3,分别表示:中性,积极,消极,褒(积)贬(消)不一四种
1、若一个情感词有两种相同的极性,例如都是1,或者-1,0,那么情感值由第一个[强度,极性]确定
2、若一个情感词有两种相同的极性且都是3,那么该情感值的极性由该情感词前0-4个的情感值极性*0.75(可以修改前后比重), 后0-4个情感值极性*0.25的和共同确定,计算只包括0,1,-1。
最后结果根据离-1,0,1这三个数的绝对距离确定
3、若一个情感词前后极性不同,那么该情感值的极性同上。
4、若只有一个情感词,则直接返回该数值即可
'''
def anaysisPolarity(word, dict_of_emtion):
str1 = dict_of_emtion[word][0][0] # 第一个强度
plo1 = dict_of_emtion[word][0][1] # 第一个极性
if len(dict_of_emtion[word]) > 1: # 若有两个极性
str2 = dict_of_emtion[word][1][0]
plo2 = dict_of_emtion[word][1][1]
if plo1 == plo2 and plo1 in [-1, 0, 1]: # 判断依据1
return [[str1, plo1]] # 返回第一个强度,极性
elif (plo1 == plo2 and plo1 == 3) or (plo1 != plo2): # 判断依据2,3
return [[str1, plo1], [str2, plo2]] # 两个都返回
else:
return [[str1, plo1]]
'''传入参数:文段,情感字典,副词字典,否定词列表'''
def analysisWords(words, dict_of_emtion, dict_of_adv, list_of_negative, par_W):
for word in words:
if word in dict_of_emtion.keys(): # 如果这个词在情感词中,则进行分析
w3 = 1 # 默认没有否定词
w4 = 1 # 默认副词为没有,也就是弱,为1
w1w2 = anaysisPolarity(word, dict_of_emtion) # 判断极性
for num in range(1, words.index(word)):
index = words.index(word) - num
index_w = words[index] # 当前下标表示的词语
if index_w == ',':
break
else:
if index_w in list_of_negative: # 如果在否定词列表中
w3 *= -1 # 找到了否定词,置为-1
if index_w in dict_of_adv.keys():
w4 = dict_of_adv[index_w] # 副词
try:
par_W.append([w1w2, w3, w4])
except Exception as e:
print("错误:", e)
def main():
'''读取情感词汇到字典'''
wb = load_workbook(emotional_file)
ws = wb[wb.sheetnames[0]] # 读取第一个sheet
dict_of_emtion = {}
for i in range(2, ws.max_row):
word = ws['A' + str(i)].value
strength = ws['F' + str(i)].value # 一个强度
polarity = ws['G' + str(i)].value # 一个极性
if polarity == 2:
polarity = -1
assist = ws['H' + str(i)].value # 辅助情感分类
if word not in dict_of_emtion.keys():
dict_of_emtion[word] = list([[strength, polarity]])
else:
dict_of_emtion[word].append([strength, polarity]) # 添加二义性的感情词
if assist != None:
str2 = ws['I' + str(i)].value
pola2 = ws['J' + str(i)].value
if pola2 == 2:
pola2 = -1
dict_of_emtion[word].append([str2, pola2])
'''读取程度副词副字典'''
dict_of_adv = {}
wb = load_workbook(adv_file)
ws = wb[wb.sheetnames[0]]
for i in range(2, ws.max_row):
dict_of_adv[ws['A' + str(i)].value] = ws['B' + str(i)].value
'''读取否定词列表'''
list_of_negative = []
with open(negative_file, "r", encoding='utf-8') as f:
temps = f.readlines()
for temp in temps:
list_of_negative.append(temp.replace("\n", ""))
para_W = [] # W1*W2*W3*W4参数的值
with open(test_file, 'r', encoding="utf-8") as f:
txt = f.readlines()
for info in txt:
article = re.findall(r'[^。!?\s]+', info) # 一句一句分析
if len(article) != 0:
for par in article:
words = jieba.lcut(par) # 一句一句分词
analysisWords(words, dict_of_emtion, dict_of_adv, list_of_negative, para_W)
new_para_W = {}
index = 1 # 情感参数的数量
for x in para_W: # 将只有一个情感极值的列表合并
if len(x[0]) == 1:
w = x[0][0][0] * x[0][0][1]
for numx in x[1:]:
w *= numx
new_para_W[index] = w
else:
new_para_W[index] = x
index += 1
for i in range(1, len(new_para_W) + 1):
if type(new_para_W[i]) == list: # 如果该情感值是未计算的
temp_result = 0
k = i-1 if i-1 != 0 else i
index = 1
while index <= 4: # 计算0-4个的值
if type(new_para_W[k]) != list:
temp_result += new_para_W[k] * alpha # 当前值乘以alaph
else:
temp_result += new_para_W[k][0][0][1] * alpha #如果没有,则默认为第一个极性
k -= 1
index += 1
if k <= 0:
break
k = i + 1 if i+1 < len(new_para_W) else i # 计算后四个的值
index = 1
while index <= 4:
if type(new_para_W[k]) != list and new_para_W[k] != 3: # 只考虑后面
temp_result += new_para_W[k] * (1-alpha)
k += 1
index += 1
if k > len(new_para_W): # 如果超出了最长长度,后面则不考虑计算
break
w2 = distance_of_num(temp_result, new_para_W[i][0][0][1], new_para_W[i][0][1][1]) # 求出w2
dict_of_str_plo = {} # 存放极值---强度的字典
str1 = new_para_W[i][0][0][0]
plo1 = w2 if new_para_W[i][0][0][1] == 3 else new_para_W[i][0][0][1] # 将褒贬不一的置为求出的局部感情极值
str2 = new_para_W[i][0][1][0]
plo2 = w2 if new_para_W[i][0][1][1] == 3 else new_para_W[i][0][1][1]
dict_of_str_plo[plo2] = str2
dict_of_str_plo[plo1] = str1
if w2 == 0:
new_para_W[i] = 0
else:
try:
new_para_W[i] = dict_of_str_plo[w2] * new_para_W[i][1] * new_para_W[i][2]
except Exception as e:
print("错误:", e)
molecular = 0 # 分子
denominator = 0 # 分母
for value in new_para_W.values():
molecular += value
denominator += math.fabs(value)
if denominator == 0:
print("情感倾向 = 0.00")
else:
print("情感倾向 = %.4f" % (molecular / denominator))
def distance_of_num(result, x1, x2):
num1 = math.fabs(result - x1)
num2 = math.fabs(result - x2)
if num1 > num2:
return x2
else:
return x1
if __name__ == '__main__':
main()
文章测试
这里随便找一篇文章进行测试:https://baijiahao.baidu.com/s?id=1698154205016909657&wfr=spider&for=pc
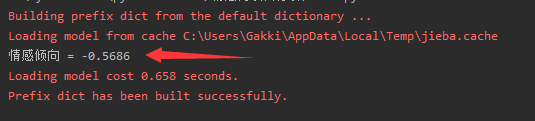
可以观察到改文章比较偏消极,本人直观上也感受到改文章偏负面多一点。
另一篇文章:https://www.xcar.com.cn/bbs/viewthread.php?tid=96468962
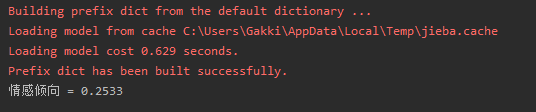
其他
否定次txt文本:
不大
不丁点儿
不甚
不怎么
聊
没怎么
不可以
怎么不
几乎不
从来不
从不
不用
不曾
不该
不必
不会
不好
不能
很少
极少
没有
不是
难以
放下
扼杀
终止
停止
放弃
反对
缺乏
缺少
不
甭
勿
别
未
反
没
否
木有
非
无
请勿
无须
并非
毫无
决不
休想
永不
不要
未尝
未曾
毋
莫
从未
从未有过
尚未
一无
并未
尚无
从没
绝非
远非
切莫
绝不
毫不
禁止
忌
拒绝
杜绝
弗
程度副词excel数据,可以先复制到txt,在excel内通过“数据”导入到excel内:
词语 强弱程度
百分之百 2
倍加 2
备至 2
不得了 2
不堪 2
不可开交 2
不亦乐乎 2
不折不扣 2
彻头彻尾 2
充分 2
到头 2
地地道道 2
非常 2
极 2
极度 2
极端 2
极其 2
极为 2
截然 2
尽 2
惊人地 2
绝 2
绝顶 2
绝对 2
绝对化 2
刻骨 2
酷 2
满 2
满贯 2
满心 2
莫大 2
奇 2
入骨 2
甚为 2
十二分 2
十分 2
十足 2
死 2
滔天 2
痛 2
透 2
完全 2
完完全全 2
万 2
万般 2
万分 2
万万 2
无比 2
无度 2
无可估量 2
无以复加 2
无以伦比 2
要命 2
要死 2
已极 2
已甚 2
异常 2
逾常 2
贼 2
之极 2
之至 2
至极 2
卓绝 2
最为 2
佼佼 2
郅 2
綦 2
齁 2
最 2
不过 1.5
不少 1.5
不胜 1.5
惨 1.5
沉 1.5
沉沉 1.5
出奇 1.5
大为 1.5
多 1.5
多多 1.5
多加 1.5
多么 1.5
分外 1.5
格外 1.5
够瞧的 1.5
够戗 1.5
好 1.5
好不 1.5
何等 1.5
很 1.5
很是 1.5
坏 1.5
可 1.5
老 1.5
老大 1.5
良 1.5
颇 1.5
颇为 1.5
甚 1.5
实在 1.5
太 1.5
太甚 1.5
特 1.5
特别 1.5
尤 1.5
尤其 1.5
尤为 1.5
尤以 1.5
远 1.5
着实 1.5
曷 1.5
碜 1.5
大不了 1
多 1
更 1
更加 1
更进一步 1
更为 1
还 1
还要 1
较 1
较比 1
较为 1
进一步 1
那般 1
那么 1
那样 1
强 1
如斯 1
益 1
益发 1
尤甚 1
逾 1
愈 1
愈 ... 愈 1
愈发 1
愈加 1
愈来愈 1
愈益 1
远远 1
越 ... 越 1
越发 1
越加 1
越来越 1
越是 1
这般 1
这样 1
足 1
足足 1
点点滴滴 1
多多少少 1
怪 1
好生 1
还 1
或多或少 1
略 1
略加 1
略略 1
略微 1
略为 1
蛮 1
稍 1
稍稍 1
稍微 1
稍为 1
稍许 1
挺 1
未免 1
相当 1
些 1
些微 1
些小 1
一点 1
一点儿 1
一些 1
有点 1
有点儿 1
有些 1
半点 1
不大 1
不丁点儿 1
不甚 1
不怎么 1
聊 1
没怎么 1
轻度 1
弱 1
丝毫 1
微 1
相对 1
不为过 1.5
超 1.5
超额 1.5
超外差 1.5
超微结构 1.5
超物质 1.5
出头 1.5
多 1.5
浮 1.5
过 1.5
过度 1.5
过分 1.5
过火 1.5
过劲 1.5
过了头 1.5
过猛 1.5
过热 1.5
过甚 1.5
过头 1.5
过于 1.5
过逾 1.5
何止 1.5
何啻 1.5
开外 1.5
苦 1.5
老 1.5
偏 1.5
强 1.5
溢 1.5
忒 1.5
有不足之处欢迎指出。
有时候不能及时通过邮件发送,所以我特意上传到百度网盘了,有需要的小伙伴可以直接下载:
链接: https://pan.baidu.com/s/1TwvgGze_LBzh8DX4Gh13rA
提取码: nkdx
1m多大小,普通用户一分钟也能下载完。
懒的用百度网盘的可以选择从gitee下载:
https://gitee.com/russianready/Sentiment-Analysis
第三次更新:2021/11/8
本次更新,将原先的代码进行了扩展,有的小伙伴可能需要对大量不同的数据进行批次处理,那么使用本代码的话,会极其麻烦,所以我修改了源代码,可以满足上述要求:
import jieba
import re
import math
import openpyxl
from openpyxl import load_workbook
negative_file = '否定词.txt'
adv_file = '程度副词.xlsx'
emotional_file = '情感词汇本体.xlsx'
test_file = '测试文章.txt'
dict_of_emtion = {} # 情感词
dict_of_adv = {} # 副词
list_of_negative = [] # 否定词列表
alpha = 0.75 # 不确定的情感值极性前后判断因素的比例,默认为0.75
'''
判断情感词极性,传入参数:情感词,情感字典
判断依据:情感分为0, 1, -1, 3,分别表示:中性,积极,消极,褒(积)贬(消)不一四种
1、若一个情感词有两种相同的极性,例如都是1,或者-1,0,那么情感值由第一个[强度,极性]确定
2、若一个情感词有两种相同的极性且都是3,那么该情感值的极性由该情感词前0-4个的情感值极性*0.75(可以修改前后比重), 后0-4个情感值极性*0.25的和共同确定,计算只包括0,1,-1。
最后结果根据离-1,0,1这三个数的绝对距离确定
3、若一个情感词前后极性不同,那么该情感值的极性同上。
4、若只有一个情感词,则直接返回该数值即可
'''
def anaysisPolarity(word, dict_of_emtion):
str1 = dict_of_emtion[word][0][0] # 第一个强度
plo1 = dict_of_emtion[word][0][1] # 第一个极性
if len(dict_of_emtion[word]) > 1: # 若有两个极性
str2 = dict_of_emtion[word][1][0]
plo2 = dict_of_emtion[word][1][1]
if plo1 == plo2 and plo1 in [-1, 0, 1]: # 判断依据1
return [[str1, plo1]] # 返回第一个强度,极性
elif (plo1 == plo2 and plo1 == 3) or (plo1 != plo2): # 判断依据2,3
return [[str1, plo1], [str2, plo2]] # 两个都返回
else:
return [[str1, plo1]]
'''传入参数:文段,情感字典,副词字典,否定词列表'''
def analysisWords(words, dict_of_emtion, dict_of_adv, list_of_negative, par_W):
for word in words:
if word in dict_of_emtion.keys(): # 如果这个词在情感词中,则进行分析
w3 = 1 # 默认没有否定词
w4 = 1 # 默认副词为没有,也就是弱,为1
w1w2 = anaysisPolarity(word, dict_of_emtion) # 判断极性
for num in range(1, words.index(word)):
index = words.index(word) - num
index_w = words[index] # 当前下标表示的词语
if index_w == ',':
break
else:
if index_w in list_of_negative: # 如果在否定词列表中
w3 *= -1 # 找到了否定词,置为-1
if index_w in dict_of_adv.keys():
w4 = dict_of_adv[index_w] # 副词
try:
par_W.append([w1w2, w3, w4])
except Exception as e:
print("错误:", e)
# 处理之前加载各种信息
def load_infos():
'''读取情感词汇到字典'''
wb = load_workbook(emotional_file)
ws = wb[wb.sheetnames[0]] # 读取第一个sheet
for i in range(2, ws.max_row):
word = ws['A' + str(i)].value
strength = ws['F' + str(i)].value # 一个强度
polarity = ws['G' + str(i)].value # 一个极性
if polarity == 2:
polarity = -1
assist = ws['H' + str(i)].value # 辅助情感分类
if word not in dict_of_emtion.keys():
dict_of_emtion[word] = list([[strength, polarity]])
else:
dict_of_emtion[word].append([strength, polarity]) # 添加二义性的感情词
if assist != None:
str2 = ws['I' + str(i)].value
pola2 = ws['J' + str(i)].value
if pola2 == 2:
pola2 = -1
dict_of_emtion[word].append([str2, pola2])
'''读取程度副词副字典'''
wb = load_workbook(adv_file)
ws = wb[wb.sheetnames[0]]
for i in range(2, ws.max_row):
dict_of_adv[ws['A' + str(i)].value] = ws['B' + str(i)].value
'''读取否定词列表'''
with open(negative_file, "r", encoding='utf-8') as f:
temps = f.readlines()
for temp in temps:
list_of_negative.append(temp.replace("\n", ""))
def distanceOfNum(result, x1, x2):
num1 = math.fabs(result - x1)
num2 = math.fabs(result - x2)
if num1 > num2:
return x2
else:
return x1
def cal_res(txt) -> float:
para_W = [] # W1*W2*W3*W4参数的值
article = re.findall(r'[^。!?\s]+', txt) # 一句一句分析
if len(article) != 0:
for par in article:
words = jieba.lcut(par) # 一句一句分词
analysisWords(words, dict_of_emtion, dict_of_adv, list_of_negative, para_W)
new_para_W = {}
index = 1 # 情感参数的数量
for x in para_W: # 将只有一个情感极值的列表合并
if len(x[0]) == 1:
w = x[0][0][0] * x[0][0][1]
for numx in x[1:]:
w *= numx
new_para_W[index] = w
else:
new_para_W[index] = x
index += 1
for i in range(1, len(new_para_W) + 1):
if type(new_para_W[i]) == list: # 如果该情感值是未计算的
temp_result = 0
k = i - 1 if i - 1 != 0 else i
index = 1
while index <= 4: # 计算0-4个的值
if type(new_para_W[k]) != list:
temp_result += new_para_W[k] * alpha # 当前值乘以alaph
else:
temp_result += new_para_W[k][0][0][1] * alpha # 如果没有,则默认为第一个极性
k -= 1
index += 1
if k <= 0:
break
k = i + 1 if i + 1 < len(new_para_W) else i # 计算后四个的值
index = 1
while index <= 4:
if type(new_para_W[k]) != list and new_para_W[k] != 3: # 只考虑后面
temp_result += new_para_W[k] * (1 - alpha)
k += 1
index += 1
if k > len(new_para_W): # 如果超出了最长长度,后面则不考虑计算
break
w2 = distanceOfNum(temp_result, new_para_W[i][0][0][1], new_para_W[i][0][1][1]) # 求出w2
dict_of_str_plo = {} # 存放极值---强度的字典
str1 = new_para_W[i][0][0][0]
plo1 = w2 if new_para_W[i][0][0][1] == 3 else new_para_W[i][0][0][1] # 将褒贬不一的置为求出的局部感情极值
str2 = new_para_W[i][0][1][0]
plo2 = w2 if new_para_W[i][0][1][1] == 3 else new_para_W[i][0][1][1]
dict_of_str_plo[plo2] = str2
dict_of_str_plo[plo1] = str1
if w2 == 0:
new_para_W[i] = 0
else:
try:
new_para_W[i] = dict_of_str_plo[w2] * new_para_W[i][1] * new_para_W[i][2]
except Exception as e:
print("错误:", e)
molecular = 0 # 分子
denominator = 0 # 分母
for value in new_para_W.values():
molecular += value
denominator += math.fabs(value)
if denominator == 0:
return 0.0
else:
return (molecular / denominator)
if __name__ == '__main__':
load_infos() # 加载情感处理所需要的词汇信息
# for txt in txts:
txt = "在这里修改txt,调用 cal_res 方法即可返回结果。如果是有多个数据,写成for的形式,多次调用即可。"
res = cal_res(txt)
print(res)


















 4199
4199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











