






ASTGCN(一)数据解析
参考文献:
https://blog.csdn.net/panbaoran913/article/details/112350218
数据来源:
数据来自于https://github.com/Davidham3/ASTGCN,PEMS04和08都在其中有下载。
文件夹解析:
用pycharm打开压缩文件包后可以看见一共有如下: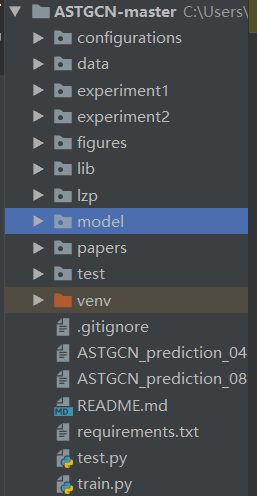
(PS:其中test和lzp是自己加的,experiments是训练过程保存的)
configurations:用于存放参数

data:存放数据集

experiments:存放训练记录文件。其中第一个.params是模型(应该是).tfeven则是用于tensorflow文件,stats_data记录的是均值和均方差。
figures:里面就一张模型示意图
libs:保存的是文章中用于数据处理的自定义的库函数。
model:模型函数
数据详解:
首先解释每一段处理函数。从研究代码的过程开始,首先打开train函数中我们可以看到
all_data = read_and_generate_dataset(graph_signal_matrix_filename,
num_of_weeks,
num_of_days,
num_of_hours,
num_for_predict,
points_per_hour,
merge)
函数中主要处理数据的函数如上,就是这个read_and_generate_dataset()函数。在lib中的data_preparation中,我们可以找到函数定义的部分代码段如下:
def read_and_generate_dataset(graph_signal_matrix_filename,
num_of_weeks, num_of_days,
num_of_hours, num_for_predict,
points_per_hour=12, merge=False):
data_seq = np.load(graph_signal_matrix_filename)['data'] #load数据集中的总数据
all_samples = []
for idx in range(data_seq.shape[0]): #循环取sample并存放在all_samples中
sample = get_sample_indices(data_seq, num_of_weeks, num_of_days,
num_of_hours, idx, num_for_predict,
points_per_hour) #得到sample
if not sample:
continue
week_sample, day_sample, hour_sample, target = sample
all_samples.append((
np.expand_dims(week_sample, axis=0).transpose((0, 2, 3, 1)),
np.expand_dims(day_sample, axis=0).transpose((0, 2, 3, 1)),
np.expand_dims(hour_sample, axis=0).transpose((0, 2, 3, 1)),
np.expand_dims(target, axis=0).transpose((0, 2, 3, 1))[:, :, 0, :]
))
上述函数中在加载数据后经过取sample之后分成了week_sample,day_sample,hour_sample和target四个部分然后前三个仅仅变换了轴,最后target取第三维存放在all_sample中。(具体可以参考参考文献)那么问题就回到了如何实现取sample。同样在lib中可以在utils中找到get_sample_indices()函数
def get_sample_indices(data_sequence, num_of_weeks, num_of_days, num_of_hours,label_start_idx, num_for_predict, points_per_hour=12):
#data_sequence.shape[0]指的是总数据量,16992个
week_indices = search_data(data_sequence.shape[0], num_of_weeks,
label_start_idx, num_for_predict,
7 * 24, points_per_hour)
if not week_indices:
return None
day_indices = search_data(data_sequence.shape[0], num_of_days,
label_start_idx, num_for_predict,
24, points_per_hour)
if not day_indices:
return None
hour_indices = search_data(data_sequence.shape[0], num_of_hours,
label_start_idx, num_for_predict,
1, points_per_hour)
if not hour_indices:
return None
week_sample = np.concatenate([data_sequence[i: j]
for i, j in week_indices], axis=0) #axis=0表示对第一个维度数组操作
day_sample = np.concatenate([data_sequence[i: j]
for i, j in day_indices], axis=0)
hour_sample = np.concatenate([data_sequence[i: j]
for i, j in hour_indices], axis=0)
target = data_sequence[label_start_idx: label_start_idx + num_for_predict]
return week_sample, day_sample, hour_sample, target
这个函数的关键我们可以看到是得到了1个target同时还有3个样本,分样本的关键是indices(int类型的变量),如何得到这个的,则是通过search_data函数,这个函数的定义就在同一个头文件函数中。
def search_data(sequence_length, num_of_batches, label_start_idx,
num_for_predict, units, points_per_hour):
if points_per_hour < 0: #每个小时划分的时间段的个数要>=0不然会报错
raise ValueError("points_per_hour should be greater than 0!")
if label_start_idx + num_for_predict > sequence_length:
return None
#如果预测目标的开始索引+预测的个数>序列长度,即在索引位置处不足以进行预测
x_idx = []
for i in range(1, num_of_batches + 1):
start_idx = label_start_idx - points_per_hour * units * i
end_idx = start_idx + num_for_predict
if start_idx >= 0:
x_idx.append((start_idx, end_idx))
else:
return None
if len(x_idx) != num_of_batches:
return None
return x_idx[::-1]
其中最核心的部分是:
for i in range(1, num_of_batches + 1):
start_idx = label_start_idx - points_per_hour * units * i
end_idx = start_idx + num_for_predict
可以看到这一段代码就是整个分割数据段的关键之一,根据每一个定义的不同(week,day,hour)划分不一样的units进而得到不同的start_idx和end_idx实现样本的划分。
另外一段最核心的部分即:
for idx in range(data_seq.shape[0]): #循环取sample并存放在all_samples中
sample = get_sample_indices(data_seq, num_of_weeks, num_of_days,
num_of_hours, idx, num_for_predict,
points_per_hour) #得到sample
从这一段我们可以知道每一个数据idx是从1到data_seq.shape[0](整个数据长度)依次增大的,所以一段数据储存12个之后,第二段数据是从第一段数据的第二个开始的。最直观的解释,我们打开all_data[‘test’][‘target’]中可以看到如下:
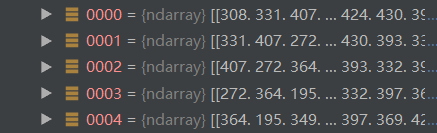
第0条数据记录308,331,407…(12个),第二条331,407…(12个),第三条407,…(12个)可以看到上述结论。所以在取流量数据进行显示的时候取每一条的第一个即可。
显示其中一段流量数据图如下:
















 2829
2829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









