







调用MapReduce对文件中各个单词出现次数进行统计
文章目录
要求
1.将待分析的文件(不少于10000英文单词)上传到HDFS
2.调用MapReduce对文件中各个单词出现的次数进行统计
3.将统计结果下载本地。
一、安装Ubuntu
一般来说,如果要做服务器,我们选择CentOS或者Ubuntu Server;如果做桌面系统,我们选择Ubuntu Desktop。但是在学习Hadoop方面,虽然两个系统没有多大区别,但是个人在学习生活中常用Ubuntu,所以本实验采用Ubuntu Kylin版本。相关下载文件可以从参考资料[1]中获取。
二、准备工作
1.创建Hadoop账户
代码如下(示例):
1.首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash
这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
2.设置hadoop密码 :
代码如下(示例):
sudo passwd hadoop
该处使用的url网络请求的数据。
3.为hadoop用户增加管理员权限:
代码如下(示例):
sudo adduser hadoop sudo
最后注销当前用户(点击屏幕右上角的齿轮,选择注销),返回登陆界面。在登陆界面中选择刚创建的 hadoop 用户进行登陆。
4.更新 apt
用 hadoop 用户登录后,先更新一下 apt,后续将使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:
代码如下(示例):
sudo apt-get update
5.安装vim
后续需要更改一些配置文件,这里采用的是 vim(vi增强版,基本用法相同),相对于vi更有辨识度,编辑起来更好用。
代码如下(示例):
sudo apt-get install vim
6.配置SSH
集群、单节点模式都需要用到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令),Ubuntu 默认已安装了 SSH client,此外还需要安装 SSH server
代码如下(示例):
sudo apt-get install openssh-server
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有如下提示(SSH首次登陆提示),输入 yes 。然后按提示输入密码 hadoop,这样就登陆到本机了。

但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。

三.安装Java环境
1.安装JDK
Hadoop3.1.3需要JDK版本在1.8及以上。需要按照下面步骤来自己手动安装JDK1.8。
我们已经把JDK1.8的安装包jdk-8u162-linux-x64.tar.gz放在了百度云盘,可以点击这里到百度云盘下载(提取码:lnwl)。
接下来在Linux命令行界面中,执行如下Shell命令(注意:当前登录用户名是hadoop):
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
2.验证JDK安装情况
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls
3.设置JAVA坏境变量
cd ~
vim ~/.bashrc
通过vim编辑器。打开环境变量配置.bashrc文件,在文件开头添加如下几行内容:
(vim编辑器中,按“i”进去编辑模式,按“:wq”保存并返回终端)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
验证安装情况
java -version
若返回如下信息,则代表JAVA环境配置成功
(图为java1.7版本)

四.安装Hadoop
Hadoop安装文件,可以到Hadoop官网下载hadoop-3.1.3.tar.gz。 也可以直接点击这里从百度云盘下载软件(提取码:lnwl) 我们选择将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop./bin/hadoop version

五.Hadoop伪分布式配置
1.修改配置文件
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
cd /usr/local/hadoop/etc/hadoop/
在进行修改配置文件前,需要创建相应的文件夹进行存放,以防后续操作无法启动Hadoop
sudo mkdir /usr/local/hadoop/tmp
sudo mkdir /usr/local/hadoop/tmp/dfs/name
sudo mkdir /usr/local/hadoop/tmp/dfs/data
完成前面的工作后,开始配置core-site.xml 和 hdfs-site.xml。首先对core-site.xml进行修改
vim core-site.xml
在配置文件中找到下面这个标签对
<configuration></configuration>
修改为下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property></configuration>
2.格式化 NameNode
配置完core-site.xml 和 hdfs-site.xml,我们需要对NameNode进行格式化:
cd /usr/local/hadoop./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 的提示,具体返回信息类似如下:
2020-01-08 15:31:31,560 INFO namenode.NameNode:
STARTUP_MSG: /************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hadoop/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.3
*************************************************************/......2020-01-08 15:31:35,677 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name **has been successfully formatted**.2020-01-08 15:31:35,700 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression2020-01-08 15:31:35,770 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .2020-01-08 15:31:35,810 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 02020-01-08 15:31:35,816 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.2020-01-08 15:31:35,816 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop/127.0.1.1
*************************************************************/
3.开启NameNode和DataNode守护进程
cd /usr/local/hadoop./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
若出现如下SSH提示,输入yes即可。
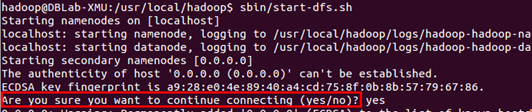
4.校验安装
当程序启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”。

成功启动后,可以访问 Web 界面 http://localhost:50070查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。

五.调用MapReduce执行WordCount对单词进行计数
1.准备工作
首先,准备一个不少于10000万单词的文本文件,内容不限,可从各大英语文献网下载,将这个文件放置于hadoop文件夹中,以便实验。

图中 zwp.txt 为实验文件
接着,将实验的文本文件上传到HDFS中(请确保Hadoop为开启状态)
./bin/hdfs dfs -put /usr/local/hadoop/demo.txt input
• 1
操作完成后调用ls命令查看文件上传情况
./bin/hdfs dfs –ls input
• 1
上传成功后可以在文件中看到实验文件
完成上传后,我们需要安装Eclipse。我们利用Ubuntu左侧边栏自带的软件中心安装软件,在Ubuntu左侧边栏打开软件中心,在搜索框输入Eclipse找到对应文件下载即可。

图中eclipse-java-mars-1-linux-gtk*.tar.gz为文件名
按实际情况输入安装完Eclipse,我们还需要安装 hadoop-eclipse-plugin,用于在 Eclipse 上编译和运行 MapReduce 程序,可下载 Github 上的hadoop2x-eclipse-plugin(备用下载地址:http://pan.baidu.com/s/1i4ikIoP)。
下载后,将 release 中的 hadoop-eclipse-kepler-plugin-2.6.0.jar (还提供了 2.2.0 和 2.4.1 版本)复制到 Eclipse 安装目录的 plugins 文件夹中,运行 eclipse -clean 重启 Eclipse 即可(添加插件后只需要运行一次该命令,以后按照正常方式启动就行了)。
unzip -qo ~/下载/hadoop2x-eclipse-plugin-master.zip -d ~/下载 # 解压到 ~/下载 中
sudo cp ~/下载/hadoop2x-eclipse-plugin-master/release/hadoop-eclipse-plugin-2.6.0.jar /usr/lib/eclipse/plugins/ # 复制到 eclipse 安装目录的 plugins 目录下/usr/lib/eclipse/eclipse -clean # 添加插件后需要用这种方式使插件生效
2. 在Eclipse中创建项目
首先,启动Eclipse,启动以后会弹出如下图所示界面,提示设置工作空间(workspace)。

可以直接采用默认的设置“/home/hadoop/workspace”,点击“OK”按钮。可以看出,由于当前是采用hadoop用户登录了Linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
Eclipse启动以后,呈现的界面如下图所示。

选择“File–>New–>Java Project”菜单,开始创建一个Java工程,弹出如下图所示界面。

在“Project name”后面输入工程名称“WordCount”,选中“Use default location”,让这个Java工程的所有文件都保存到“/home/hadoop/workspace/WordCount”目录下。在“JRE”这个选项卡中,可以选择当前的Linux系统中已经安装好的JDK,比如jdk1.8.0_162。然后,点击界面底部的“Next>”按钮,进入下一步的设置。
3. 为项目添加需要用到的JAR包
需要在这个界面中加载该Java工程所需要用到的JAR包,这些JAR包中包含了与Hadoop相关的Java API。这些JAR包都位于Linux系统的Hadoop安装目录下,对于本教程而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“Libraries”选项卡,然后,点击界面右侧的“Add External JARs…”按钮,弹出如下图所示界面。

在该界面中,上面有一排目录按钮(即“usr”、“local”、“hadoop”、“share”、“hadoop”、“mapreduce”和“lib”),当点击某个目录按钮时,就会在下面列出该目录的内容。
为了编写一个MapReduce程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/mapreduce”目录下的所有JAR包,但是,不包括jdiff、lib、lib-examples和sources目录,具体如下图所示。

(4)“/usr/local/hadoop/share/hadoop/mapreduce/lib”目录下的所有JAR包。
比如,如果要把“/usr/local/hadoop/share/hadoop/common”目录下的hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar添加到当前的Java工程中,可以在界面中点击相应的目录按钮,进入到common目录,然后,界面会显示出common目录下的所有内容(如下图所示)。

请在界面中用鼠标点击选中hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar,然后点击界面右下角的“确定”按钮,就可以把这两个JAR包增加到当前Java工程中,出现的界面如下图所示。

从这个界面中可以看出,hadoop-common-3.1.3.jar和haoop-nfs-3.1.3.jar已经被添加到当前Java工程中。然后,按照类似的操作方法,可以再次点击“Add External JARs…”按钮,把剩余的其他JAR包都添加进来。需要注意的是,当需要选中某个目录下的所有JAR包时,可以使用“Ctrl+A”组合键进行全选操作。全部添加完毕以后,就可以点击界面右下角的“Finish”按钮,完成Java工程WordCount的创建。
4. 编写Java应用程序
下面编写一个Java应用程序,即WordCount.java。请在Eclipse工作界面左侧的“Package Explorer”面板中(如下图所示),找到刚才创建好的工程名称“WordCount”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New–>Class”菜单。
选择“New–>Class”菜单以后会出现如下图所示界面。

在该界面中,只需要在“Name”后面输入新建的Java类文件的名称,这里采用名称“WordCount”,其他都可以采用默认设置,然后,点击界面右下角“Finish”按钮,出现如下图所示界面。

可以看出,Eclipse自动创建了一个名为“WordCount.java”的源代码文件,并且包含了代码“public class WordCount{}”,请清空该文件里面的代码,然后在该文件中输入完整的词频统计程序代码,具体如下:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}}
5. 编译打包程序
现在就可以编译上面编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”,如下图所示。

点击界面右下角的“OK”按钮,开始运行程序。程序运行结束后,会在底部的“Console”面板中显示运行结果信息(如下图所示)。

下面就可以把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。现在可以把词频统计程序放在“/usr/local/hadoop/myapp”目录下。如果该目录不存在,可以使用如下命令创建:
cd /usr/local/hadoop
mkdir myapp
首先,请在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“WordCount”上点击鼠标右键,在弹出的菜单中选择“Export”,如下图所示。

然后,会弹出如下图所示界面。

在该界面中,选择“Runnable JAR file”,然后,点击“Next>”按钮,弹出如下图所示界面。

可以忽略该界面的信息,直接点击界面右下角的“OK”按钮。至此,已经顺利把WordCount工程打包生成了WordCount.jar。可以到Linux系统中查看一下生成的WordCount.jar文件,可以在Linux的终端中执行如下命令:
cd /usr/local/hadoop/myapp
ls
可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个WordCount.jar文件。

5. 运行程序
在运行程序之前,需要启动Hadoop,命令如下:
cd /usr/local/hadoop./sbin/start-dfs.sh
然后,再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/user/hadoop/input”目录,具体命令如下:
cd /usr/local/hadoop./bin/hdfs dfs -mkdir input
然后,把之前在第7.1节中在Linux本地文件系统中新建的两个文件悲惨世界(英文版).txt,上传到HDFS中的“/user/hadoop/input”目录下,命令如下:
cd /usr/local/hadoop./bin/hdfs dfs -put ./悲惨世界(英文版).txt input
现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
cd /usr/local/hadoop./bin/hadoop jar ./myapp/WordCount.jar input output

词频统计结果已经被写入了HDFS的“/user/hadoop/output”目录中,可以执行如下命令查看词频统计结果:
cd /usr/local/hadoop./bin/hdfs dfs -cat output/*
查看output文件夹是否有运行成功后生成的文件:
./bin/hdfs dfs -ls output

将output文件夹下载至本地:
./bin/hdfs dfs -get output ./output
执行完查看文件:

查看part-r-00000文件:

六.总结
通过本次实验操作,从Ubuntu的安装到WordCount案例完成,系统地将每个部分进行深化解析,包括如何配置Hadoop、MapReduce,Eclipse等,同时将本人之前遇到的困难进行解决希望对正在观看这篇文章的你有所帮助,同时本人也处于学习过程,有错误的地方欢迎指出。















 1492
1492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









