







!!! 有需要的小伙伴可以通过文章末尾名片咨询我哦!!!
💕💕作者:小马
💕💕个人简介:混迹在java圈十年有余,擅长Java、微信小程序、Python、Android等,大家有这一块的问题可以一起交流!
💕💕各类成品java系统 。javaweb,ssh,ssm,springboot等等项目框架,源码丰富,欢迎咨询交流。学习资料、程序开发、技术解答、代码讲解、源码部署,需要请看文末联系方式。
基于Spark的音乐数据分析平台的设计与实现
摘 要
随着信息化时代的到来和数字音乐市场的迅速发展,国内外数字化音乐数量和音乐平台用户数量都在急剧增加,音乐数据分析的需求日益增长。本文设计并实现一个基于Spark的音乐数据分析平台,利用分布式技术对音乐数据进行统计分析,获得音乐的热度榜、分类等信息,并以多种的可视化形式进行展示,提高了音乐搜索的效率和准确性,为用户提供音乐服务。
本文详细介绍该平台的总体架构。首先,利用scrapy库进行音乐数据的爬取,以分布式文件系统HDFS形式对获得的音乐数据进行存储,然后使用Spark组件对音乐数据进行分布式的统计分析,将分析后的结果存储到MySQL数据库,最后采用wordcloud、echarts等多种可视化技术对分析结构进行展示,该系统不仅可以帮助用户了解自己的音乐类型偏好和行为习惯,还可以为平台运营者提供丰富的音乐信息和准确的市场趋势预测。
Design and implementation of Spark-based music data analysis platform
Abstract
With the advent of the information age and the rapid development of the digital music market, the number of digital music and music platform users both domestically and internationally is rapidly increasing, and the demand for music data analysis is growing day by day. This article designs and implements a music data analysis platform based on Spark, which uses distributed technology to statistically analyze music data, obtain music popularity charts, classifications, and other information, and display them in various visual forms, improving the efficiency and accuracy of music search and providing music services to users.
This article provides a detailed introduction to the overall architecture of the platform. Firstly, using the Scrapy library for music data crawling, the obtained music data is stored in the form of a distributed file system HDFS. Then, using the Spark component for distributed statistical analysis of the music data, the analyzed results are stored in the MySQL database. Finally, various visualization technologies such as wordcloud and echarts are used to display the analysis structure. This system not only helps users understand their music type preferences and behavior habits, but also provides platform operators with rich music information and accurate market trend predictions.
目录
第3章 基于Spark的音乐数据分析平台的系统设计... 9
插图清单
表格清单
音乐作为一种跨越时代和文化的艺术形式,自古以来就一直是人类生活的一部分。从原始社会的打击乐器到现代的电子音乐,音乐的演变反映了人类文化和技术的进步。在数字化和信息技术飞速发展的今天,音乐产业经历了从传统物理媒介到数字格式的转变,尤其是流媒体平台的兴起,极大地改变了人们获取和享受音乐的方式[1]。
这一变革带来了海量的音乐消费数据,这些数据涵盖了从用户行为到音乐内容分析的各个方面。然而,如何从这些庞大而复杂的数据中提取有价值的信息,支持音乐产业的决策制定和创新发展,成为了一个待解决的问题[2]。
随着大数据技术不断的发展和进步,数据处理的方法和工具日益多样化和强大。Apache Spark作为一种高效的大数据处理框架,在处理大量的数据集时展现出高效率和高速度的特点,成为研究和工业界广泛采用的技术。同时,现代数据可视化技术,如Echarts,为数据呈现提供了动态、交互式的图表和仪表板,使得非专业用户也能直观理解数据分析结果[3][4]。
本文基于Apache Spark设计和实现了一个音乐数据分析平台,旨在支持音乐产业的数字化转型。这个平台将能够应对音乐产业在数字化转型过程中产生的大规模数据处理需求,提供从数据收集、存储、处理到分析和可视化的一站式解决方案。本研究的成果可以为用户迅速了解音乐热度榜单,专辑热度榜单,专辑在各个城市售卖情况等信息,本研究在技术实现、行业应用和战略决策三个层面都具有深远的意义,旨在为音乐行业提供数据分析的洞察,支持业务增长和创新发展[5]。
在21世纪的浪潮中,我国信息技术事业如同一颗璀璨明珠般熠熠生辉。随着技术的迅猛进步,我国互联网平台上累积了庞大的用户数据。伴随着数字时代的到来,人们的生活逐渐被数字化所主导,这无疑提升了社会生活的数字化程度。因此,越来越多的人选择通过互联网进行娱乐活动,比如在线观看电影、聆听音乐、阅读电子书等[6]。
国外有Spotify、Netflix、Apple Music等音乐平台,而国内也有众多音乐平台如QQ音乐、网易云音乐等平台。本论文将重点探讨大数据技术在音乐平台上的应用[7][8]。
随着大数据技术的不断发展与进步,音乐数据分析已成为备受关注的研究方向。在其中,作为国内最大的在线音乐平台之一,网易云音乐的数据分析也备受瞩目。并且针对网易云的音乐数据分析已成为研究者们热衷选择的对象[9][10]。并且国外的Spotify、Apple Music等音乐流媒体平台利用大数据技术实现了为用户查看各种类型歌曲热度榜单,提供了丰富的音乐内容和服务。可见,随着技术的不断进步和研究的深入,音乐数据分析平台在未来将发挥更加重要的作用,为用户带来如专辑购买情况、歌手热度榜单等信息[11]。
大数据技术在音乐行业中的应用已经成为一种趋势,并在音乐数据分析平台中展现出了许多独特的数据网络特点[12],如下图1-1。

图 1‑1 音乐数据特征
大数据技术在音乐行业中的应用为音乐数据分析平台带来了许多独特的数据网络特点,包括海量数据处理能力、多样化数据来源、实时性和即时性、个性化推荐和服务等优势方面。这些特点使得音乐数据分析平台能够更好地满足用户和音乐产业的需求,推动音乐产业的数字化转型和创新发展[13]。
音乐数据分析平台的系统设计研究是针对音乐数据分析的需求和挑战,通过应用大数据技术和分析方法[14],设计高效、可靠的数据处理和分析系统。研究内容主要包括以下几个方面:系统架构设计、数据采集与存储、数据处理与分析、数据可视化与应用[15]。具体过程如下:
- 确定系统整体架构,包括处理流程、模块划分及实现、组件选择等。考虑系统的可扩展性、容错性、性能和安全性等方面,以应对日益增长的数据规模和复杂性。
- 设计数据采集模块,从多种数据源获取音乐相关数据,如音频文件、用户行为、社交互动等。选择合适的数据存储技术,如分布式文件系统(如HDFS)、关系型数据库等,以支持大规模数据存储和高并发访问[16]。
- 开发数据处理和分析模块,利用大数据技术(如Spark、Hadoop)进行数据清洗、转换、计算和挖掘。设计并实现音乐特征提取、情感分析、用户画像构建、音乐推荐算法等功能,以实现对音乐数据的深入分析和挖掘。
- 开发数据可视化模块,设计直观、友好的可视化界面,将分析结果以简易形式展示给用户。
随着信息化时代的到来和数字音乐市场的迅速发展,国内外数字化音乐数量和音乐平台用户数量都在急剧增加,音乐数据分析的需求日益增长。本文旨在音乐数据分析的需求,设计并实现一套基于Spark的音乐数据分析平台。
本文的主要研究内容如下:
- 音乐数据分析平台需求分析
结合国内某音乐流媒体平台的运营现状,明确该平台的总体需求。基于用户的角度进行了功能性需求,对系统的可行性进行了分析并从系统性能、易用性等角度描述了非功能性需求,还对系统的架构进行了总结,为系统的实现做好充足的准备。
- 基于Spark的音乐数据分析
Spark分析音乐数据的过程包括以下步骤:首先,使用Spark的read方法从存储系统读取音乐数据,生成一个DataFrame。然后,使用groupBy和count等聚合函数对数据进行统计分析,计算每首歌曲的播放次数。之后,利用orderBy函数对统计结果按播放次数进行降序排序,获取播放次数最多的歌曲。最后,通过limit函数提取前5首歌曲,并使用show函数展示top榜单。这一系列操作通过Spark的分布式计算能力,实现了对海量音乐数据的高效分析和处理。
- 基于Spark的音乐数据分析平台详细设计
基于市场对音乐数据的需求分析,设计了基于Spark的音乐数据分析平台,该平台技术上,首先利用scrapy库进行音乐数据的爬取,在数据存储方面使用了HDFS技术进行存储,在数据分析模块中,是利用Spark中自带的groupBy和count等聚合函数对音乐数据进行统计分析,分析出歌曲榜单热度,专辑热度等等信息存储到MySQL上面,最后利用Echarts和词云技术进行可视化,该平台采用django后端技术设计了该平台,通过用户登录,用户可以清楚的看见各种可视化结果。
本文主要分为五个章节。
第一章是绪论。介绍了研究背景和国内外研究现状,随着大数据的发展,数据分析的可视化已经成为了重要的研究和应用领域。
第二章是相关技术简介。介绍了本论文所需要用到的相关技术。
第三章是基于Spark的音乐数据分析平台的系统设计。介绍了该系统的需求分析、总体系统设计及系统详细设计。
第四章是基于Spark的音乐数据分析平台的实现。说明了搭建该平台所需要用到了环境,以及展示了最终实现的结果。
第五章是总结与展望。总结了本文的研究成果,并简述了基于Spark的音乐数据分析平台的不足与对未来的展望。
本章介绍了音乐产业的发展,表明音乐作为人们生活中不可或缺的一项娱乐活动,带来了海量的数据需要从中挖掘其含义,接着对比了国内外音乐数据分析平台,说明了音乐数据分析平台的发展、数据网络特点及系统设计研究,最后介绍了该论文的主要研究内容和结构安排。
技术架构图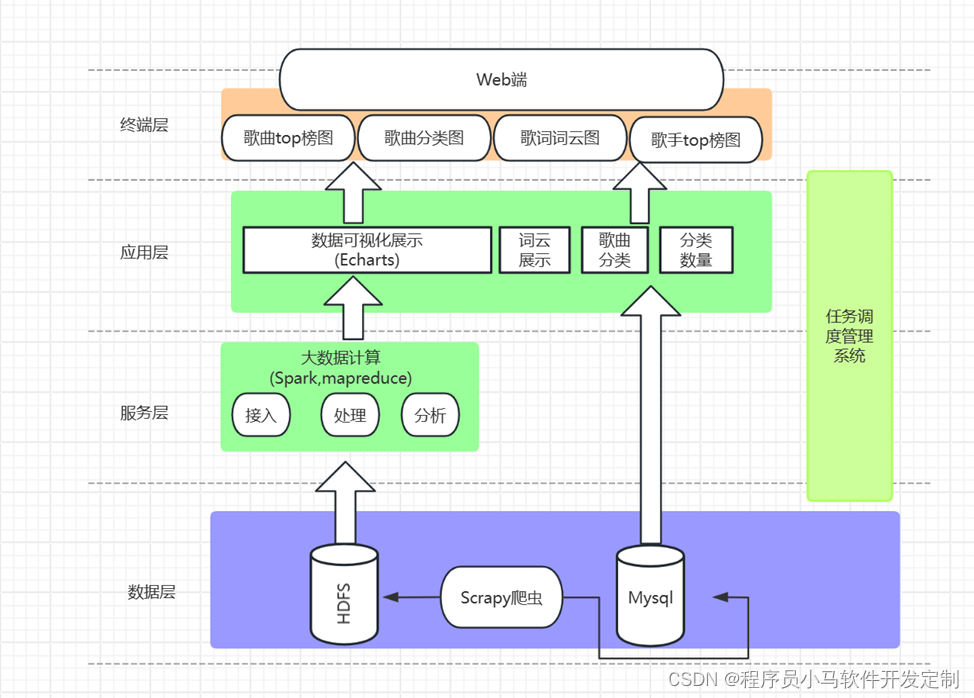
分析结果图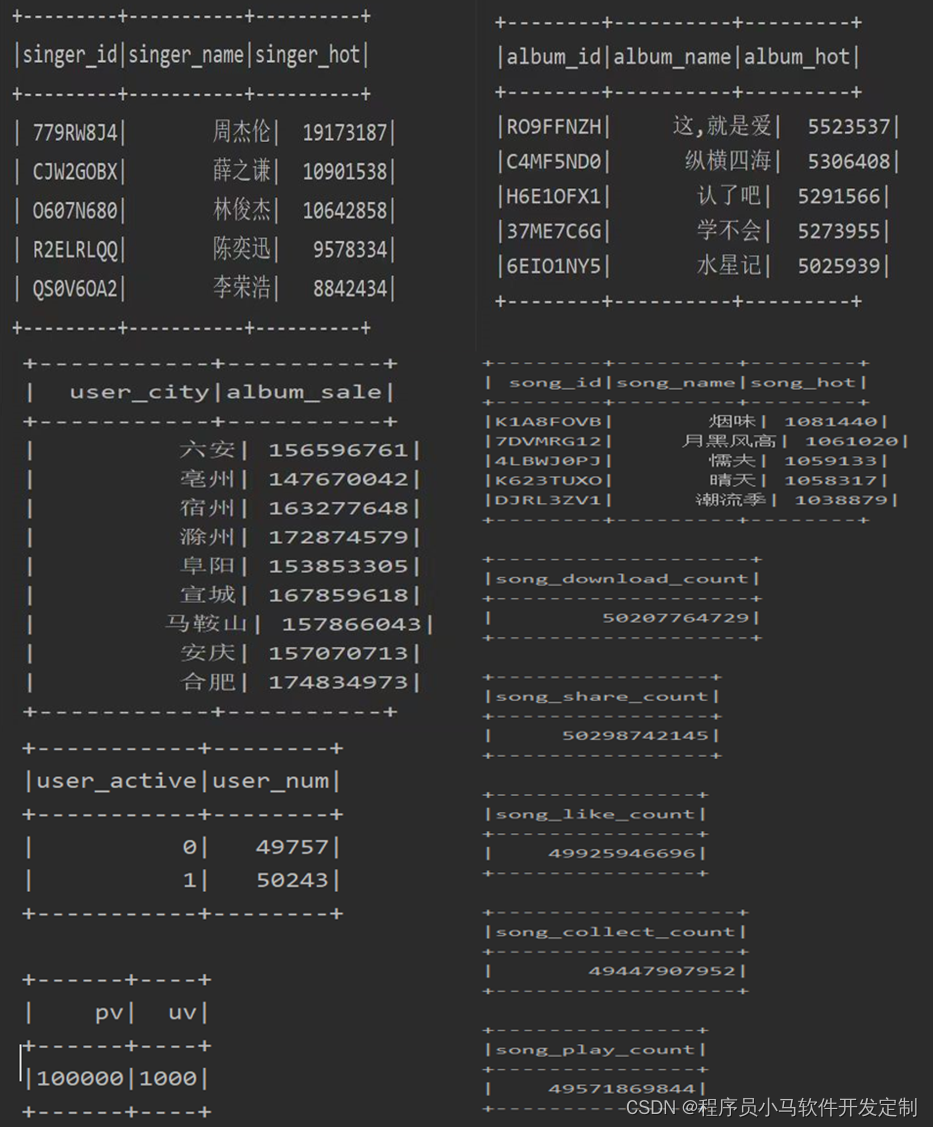
用户登录界面
用户注册界面
歌曲热度排序图
歌曲收藏排序图
歌曲评分排序图
歌曲时间排序图
歌曲分类图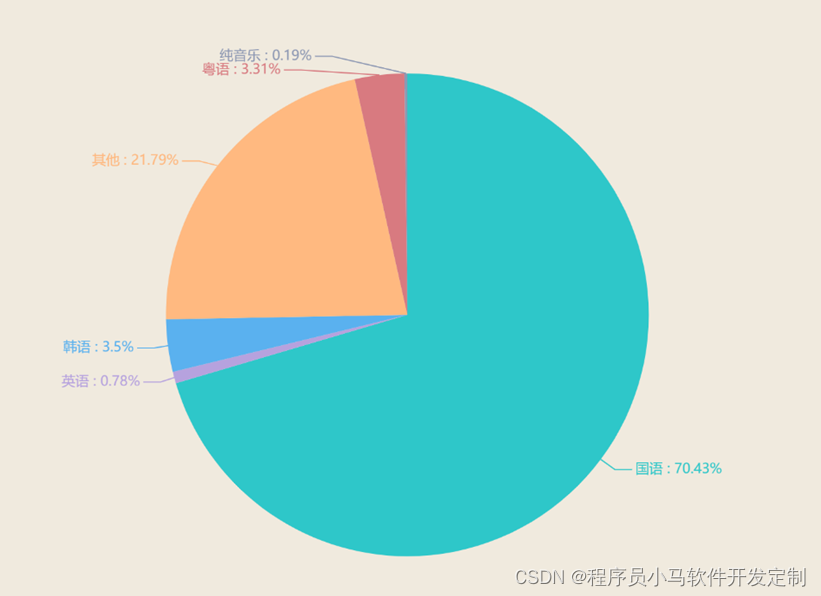
歌手评分词云图

大屏展示图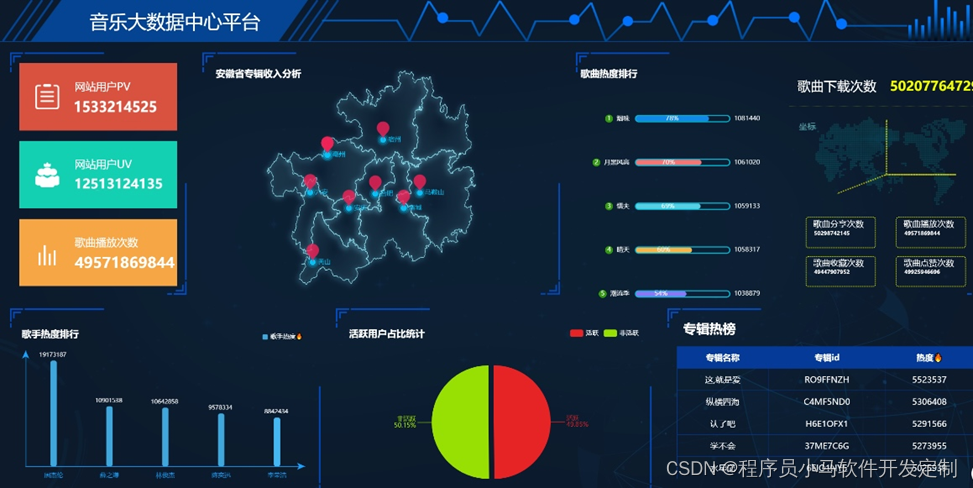
更多项目:
另有1000+份项目源码,项目有java(包含springboot,ssm,jsp等),小程序,python,php,net等语言项目。项目均包含完整前后端源码,可正常运行!
!!! 有需要的小伙伴可以点击下方链接咨询我哦!!!


















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











