







代码地址 https://github.com/ckl666/search
文章目录
环境
- mysql数据库
- redis数据库
- ubuntu 系统
- python3
- flask 框架
- gevent库
系统设计
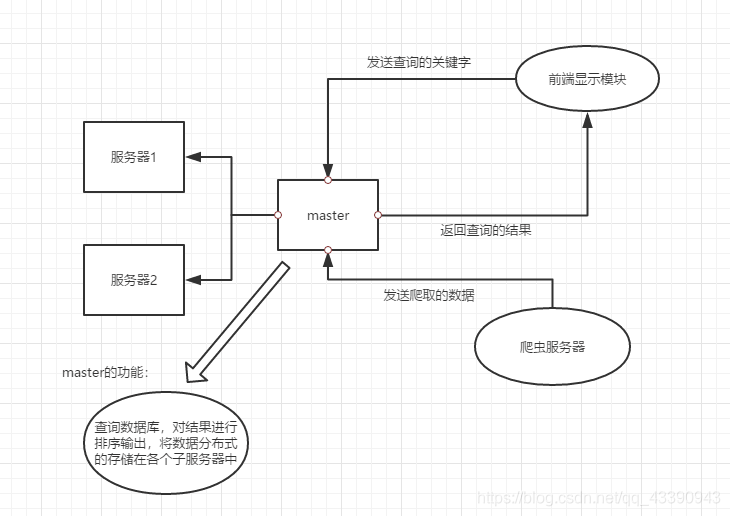
系统分为四个模块:
masterServer模块
- 中间的master服务器模块,整个系统的核心部件,主要负责接收webServer的请求,将请求分发给solve服务器,然后接收slave的查询结果,返回给webServer
- 爬虫服务器会将即将要爬取的url发送给master服务器,master负责去除已经爬取过的url和重复的url,然后反馈给爬虫服务器
考虑到master服务器是整个系统的核心部分,与各个组件都有关联,其效率一定要高,所以网络通信的方式采用异步IO+ 协程方式,即能简化编程,又能提高并发效率,master服务器要进行url的比对过程,要存储大量的爬取过的url,如果存放在磁盘上,要牵扯到大量的磁盘IO的操作,所以这里采用了redis数据库,将数据存放在内存上,提高速度。
slaveServer模块
- 负责存储爬取的数据
- 根据关键字与url页面建立倒排索引存储在MySQL数据库中
- 负责处理masterServer发来的查询的请求
对查询的结果按照一定的算法计算出页面对于用户的价值度,按价值度的高低进行排序,返回给masterServer
- 根据关键字在网页中的词频来计算当前网页的权重
- 提出超链接的说明文字,这部分文字更能代表网页的主要内容,所占的权重较大
- 根据网页间的链接的关系,采用PageRank算法计算网页的权重
- 根据上面的三个网页的影响因素按照一定的比例相加,最终所得到的网页的权重越大,页面链接的排名越靠前
solveServer是分布式存储的子节点,这里单个的solveServer节点之间不存在通信的问题,简化了编程,每个solve节点只需要与masterServer节点进行通信即可。
爬虫模块
1、给定一个初始的url进行爬取
2、提取出爬取的网页中的url,发送给master,接收经过master处理后的url,迭代进行爬取
- 采用bs4获取网页的文本的内容
- 采用jieba库提取网页的关键字与关键字在网页中的权重
(爬虫模块采用集群式的爬虫,每个单个的节点采用多线程的并发模式)
webServer模块
1、获取用户输入的关键字,将关键字发送给masterServer
2、接收masterServer返回的结果,将结果反馈给用户
这里将webServer于文件存储模块分开,方便webServer的集群的设计,也方便了数据库的分布式部署。这里并没有将webServer设计为集群模式,我只是做了基本的功能实现,webSerber与数据的存储已经分开了,所以webServer的集群设计应该会很容易实现
数据库设计
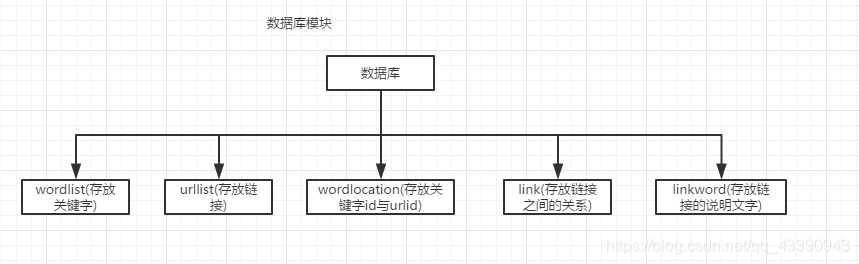
- wordlist 存放网页中提取出来的关键字
- urllist 存放网页的链接
- wordlocation 存放关键自在网页中所占的比重(对查询结果排序的时候用)
- link 存放链接之间的关系(排序)
- linkword 存放超链接的说明文字与超链接的对应关系(排序)
模块的具体实现
masterServer
master监听两个端口,一个负责接受web端的链接,一个负责接受solve端的链接
def createSockte():
serverSocket1 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serverSocket2 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
host = socket.gethostname()
port1 = 6666
serverSocket1.bind((host,port1))
serverSocket1.listen(5)
port2 = 6667
serverSocket2.bind((host,port2))
serverSocket2.listen(5)
return serverSocket1, serverSocket2
master采用多协程的并发模式,简化编程,提高并发
def main():
while True:
g1 = gevent.spawn(acceptConn, serverSocket1)
g2 = gevent.spawn(acceptConn, serverSocket2)
# gevent.sleep(1)
g1.join()
g2.join()
在redis数据库中存储已经爬取过的url,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









