







强化学习简介
我们知道,强化学习广泛应用于玩一些较为简单的游戏,其思想就是:过一段时间(例如0.1秒)拍一张(游戏)图片,然后机器看一下,看完之后做出决定,下一步应该干些什么,例如是往左移动还是往右移动,还是射击。执行完这一步动作之后,机器会读取游戏的分数,如果分数高机器就会记住,以后遇到那个图片的时候就走这一步,相反,如果分数低或者直接被敌人杀了,机器就会记住下次再遇到那个图片,就不走那一步了。如此反复下去,直到学会怎么玩游戏。
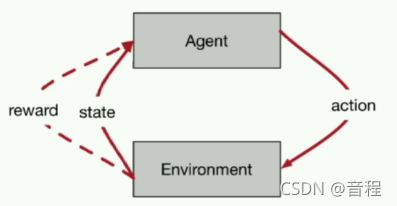
在这个例子中,机器(玩家)就是agent,state就是图像,Environment就是游戏,reward就是当前得分,action就是左移,右移等玩家可以执行的游戏动作。如下:
gym简介
import gym
gym是大名鼎鼎的openai组织开发的,其还开发过GPT3。
其初衷是:We provide the environment; you provide the algorithm.
也就是说gym来提供强化学习的环境,而研究人员提供强化学习的算法。
可以看到,环境是强化学习甚至gym中非常重要的概念,gym中内置了一些环境(http://gym.openai.com/envs/#classic_control,http://gym.openai.com/envs/),其中一个就就是我们今天要玩的游戏CliffWalking-v0,如下:
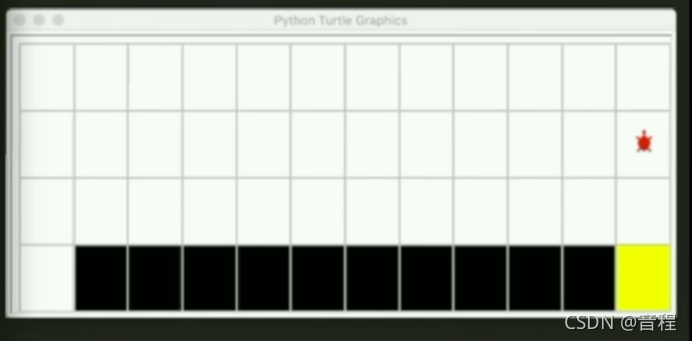
初始默认你会在左下角,黑色代表悬崖,踩上去并不会game over,但是会获得非常大的惩罚(reward=-100),黄色是我们的终点,一旦踩到终点,这局游戏结束,于是agent开始反思这局玩得怎么样(这是强化学习算法的核心,目前有很多算法),并调整策略,比如下次再也不踩悬崖了。
下面我们就来实战玩一局游戏,但是由于本文的篇幅限制,我们并不会涉及玩完一局游戏之后agent如何反思,调整,这个内容之后会专门出一篇文章来总结当今流行的算法。
CliffWalking-v0
那么我们如何开启这个环境呢?如下即可:
env=gym.make("CliffWalking-v0")#v0表示版本一
然后env就有了如下的方法。

env.reset()#初始化这个游戏,返回36,即机器玩家的初始位置,是下面的x
env.render()#返回一个图像
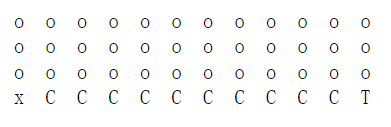
注意到一行12个位置,x的位置是36(本来是37,但是从0开始编码)。
其中C表示cliff,悬崖。T表示terminal终点。
然后我们使用接口(2),即让机器玩家执行动作的接口。比如我们向上移动一个位置,在这个游戏中,0,1,2,3分别代表上,右,下,左。
print(env.step(0))#向上走一步
env.render()#重绘图像(提交)

24代表位置,-1代表奖励,由于没有走到终点,所以奖励为负数,为什么不是奖励为0呢,奖励为负数的好处在于可以让我们尽快的走到终点。False就是说没有到达终点,本局游戏还没有结束。最后一个字典类型用不到,是辅助信息不用管。
一个注意的点是:如果走到了终点T,那么需要我们手动去重置游戏reset(),否则你继续step的话,其仍然还是在原地不动。


















 4522
4522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











