






克隆虚拟机
安装jdk和hadoop
使用SCP指令安全拷贝
一、克隆虚拟机
1)之前我已经将虚拟机的IP地址等配置完毕,也将jdk 卸载掉(我装的是桌面版本),现要利用模板虚拟机hadoop100,克隆三台虚拟机:hadoop102、hadoop103、hadoop104。
注意:克隆时,要先关闭hadoop100
2)克隆步骤:
鼠标右击模板机,点击管理->克隆
点击下一页
下一页
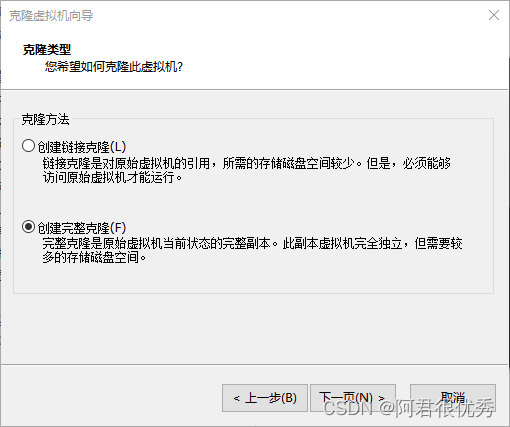
这里要选择“创建完整克隆”,而链接克隆相当于模板机的快捷方式
3)到这里克隆机已经克隆完毕,可以打开这台克隆的虚拟机,修改克隆机的静态IP地址与主机名称。与之前模板机配置过程一样,输入:
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
进入网卡配置文件后,只需要修改IPADDR,将下图框选的100换成102
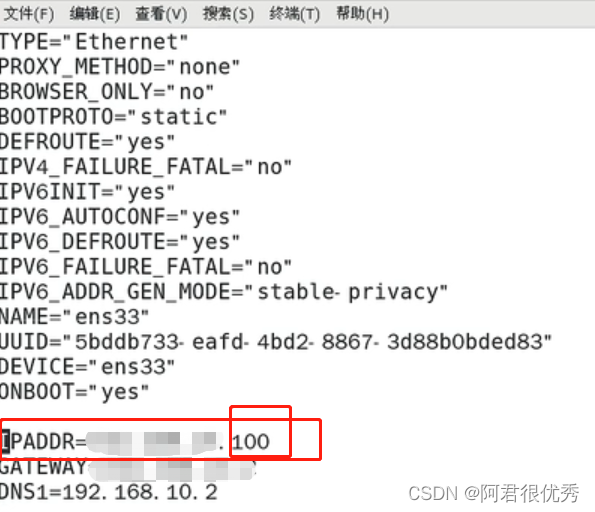
4)接下来,修改主机名称:[root@hadoop100 ~]# vim /etc/hostname hadoop102
5)输入reboot 指令,重启克隆机hadoop102
6) 修改windos 的主机映射文件(hosts文件)
(a)进入 C:\Windows\System32\drivers\etc 路径
(b)拷贝 hosts 文件到桌面
(c)打开桌面 hosts 文件并添加如下内容
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
(d)将桌面 hosts 文件覆盖 C:\Windows\System32\drivers\etc 路径 hosts 文件
二、安装JDK和Hadoop
1)安装JDK
安装jdk之前一定确保提前删除了虚拟机自带的jdk
使用Xshell传输工具将JDK和hadoop 导入到opt 目录下的softeware文件夹下面
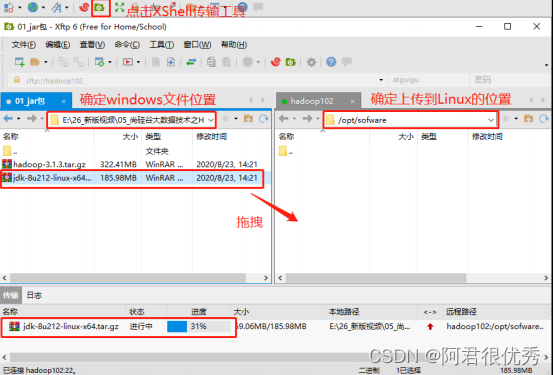
3)在linux系统下的opt目录中查看软件包是否导入成功
[atguigu@hadoop102 ~]$ ls /opt/software/
结果如下:
jdk-8u212-linux-x64.tar.gz
4)解压jdk到/opt/module目录下
[atguigu@hadoop102 software]$ tar -zxvf jdk-8u212-linuxx64.tar.gz -C /opt/module/
5)解压成功,配置jdk环境变量
新建/etc/profile.d/my_env.sh 文件
[atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加以下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
保存后退出::wq
6)source 一下/etc/profile 文件,让新的环境变量 PATH 生效
[atguigu@hadoop102 ~]$ source /etc/profile
测试是否安装成功:
[atguigu@hadoop102 ~]$ java -version
如果能看到以下结果,则代表 Java 安装成功。
java version "1.8.0_212"
如果没有显示安装成功就重启一下
2、安装Hadoop
1)上步中配置jdk 的时候,我们已将hadoop文件上传到linux 系统中
2)进入到Hadoop安装包路径下,江解压安装文件到/opt/module下面
[atguigu@hadoop102 ~]$ cd /opt/software/
[atguigu@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C
/opt/module/
3)查看是否解压成功
[atguigu@hadoop102 software]$ ls /opt/module/
hadoop-3.1.3
4)将Hadoop添加到环境变量
获取hadoop安装路径
[atguigu@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
打开/etc/profiile.d/my_env.sh文件
[atguigu@hadoop102 hadoop-3.1.3]$ sudo vim
/etc/profile.d/my_env.sh
在my_env.sh文件末尾添加如下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存退出
让修改侯的文件生效
[atguigu@hadoop102 hadoop-3.1.3]$ source /etc/profile
并测试是否安装成功
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop version
Hadoop 3.1.3
三、使用SCP指令安全拷贝
scp: 可以实现服务器与服务器之间的数据拷贝。
语法:
scp -r
p
d
i
r
/
pdir/
pdir/fname
u
s
e
r
@
h
o
s
t
:
user@host:
user@host:pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
前面两步中,我们已经在hadoop102 中讲对应的jdk、hadoop 安装完毕,现在需要将它们拷贝到hadoop103、hadoop104上。在操作之前,需要在确保三台虚拟机都已经创建好/opt/moudle和、opt/software这两个目录,并且已经把这两个目录修改为atguigu:atguigu
[atguigu@hadoop102 ~]$ sudo chown atguigu:atguigu -R
/opt/module
在 hadoop102 上,将 hadoop102 中/opt/module/jdk1.8.0_212 目录拷贝到
hadoop103 上。
[atguigu@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212
atguigu@hadoop103:/opt/module
在 hadoop103 上,将 hadoop102 中/opt/module/hadoop-3.1.3 目录拷贝到
hadoop103 上。
[atguigu@hadoop103 ~]$ scp -r
atguigu@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
在 hadoop103 上操作,将 hadoop102 中/opt/module 目录下所有目录拷贝到
hadoop104 上。
[atguigu@hadoop103 opt]$ scp -r
atguigu@hadoop102:/opt/module/*
atguigu@hadoop104:/opt/module















 802
802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









