






selenium学习之路1
参考视频:https://www.bilibili.com/video/BV1NM4y1K73T/?p=63&spm_id_from=pageDriver&vd_source=7963e4096d2b51e52877519dc0202e3e
此为链接
一、环境安装
- 安装Python3编译器
- 安装Pycharm软件集成环境
- 安装selenium包:pip install selenium
- 安装浏览器
- 安装浏览器对应的WebDriver驱动程序(点击这里下载最新的驱动
,驱动要放进要测试脚本的路径内)
二、代码示例
备注1:建立python文件时,名字以拼音或英文命名,不要以数字开头,不写中文,避免引用出错!
备注2:要根据浏览器写代码时,最好先打开浏览器的无痕窗口,没有cookie,就相当于代码打开的浏览器一样。
#先打开无痕模式。
#导包
from selenium import webdriver
import time
#webdriver获取浏览器对象
driver = webdriver.Chrome() # 记得是大写的Chrome
#准备地址
url = "https://www.baidu.com"
#使用driver,打开浏览器
driver.get(url)
#页面停留5秒
time.sleep(5)
#最后回收资源
driver.quit()
运行后会打开页面,并自动关闭
三、基本语法
(一)元素查找
1、目的:定位浏览器的元素
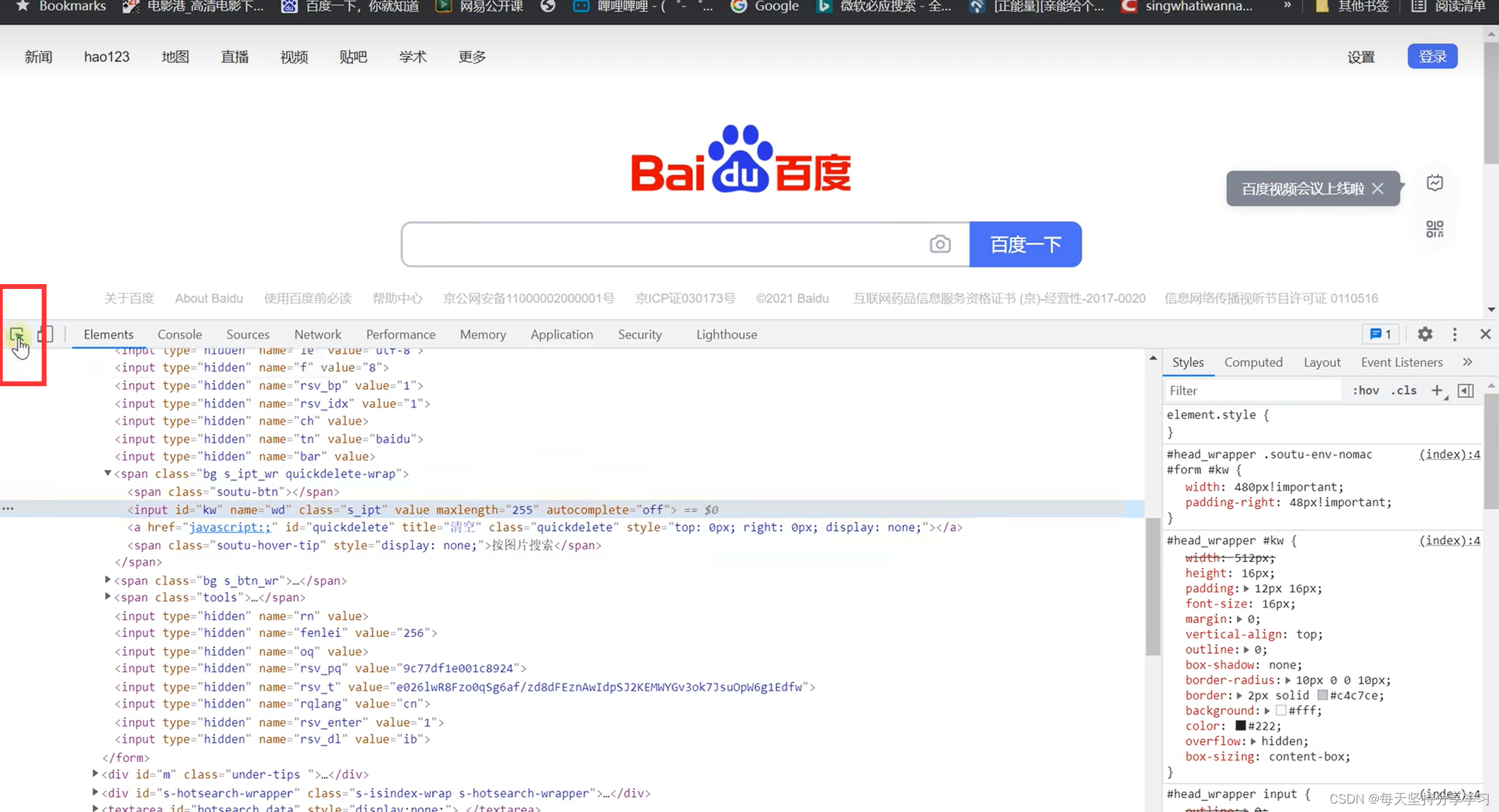
2、浏览器查看id\name\class\tag等:打开浏览器-》点击右键-》点击检查-》点击小箭头-》点击想查看的任意元素,标蓝的代码就是元素的id\name\class\tag等
(或直接点击 Fn + F12 )
3、查找方式:
(1)普通查找 (下面这几种方式并不一定都用,有id用id)
id:唯一
name
class_name(在浏览器里其实叫class)(如果class里面出现了空格,就用小圆点代替)
tag_name(一般不使用,重复性太高)
示例:
#导包
from selenium import webdriver #必须导!
import time #停留时间供我们查看
from selenium.webdriver.common.by import By #查找元素时需要
#webdriver获取对象
driver = webdriver.Chrome()
url = "https://www.baidu.com"
#打开百度浏览器
driver.get(url)
#基本查找元素(三种方法)
#输入python
driver.find_element(By.ID,"kw").send_keys("PYTHON") #靠id找到元素
#点击百度
driver.find_element(By.ID,"su").click()
#打开登录界面
driver.find_element(By.NAME,"tj_login").click() #靠name找到元素
#等待五秒
time.sleep(5) #有时候报错,是因为浏览器加载较慢,要给缓冲时间
#关闭登录界面
driver.find_element(By.CLASS_NAME,"close-btn").click() #靠class_name找到元素
time.sleep(5)
#成功退出
driver.quit()
运行成功!
(2)超链接查找(a标签)根据文本进行查找
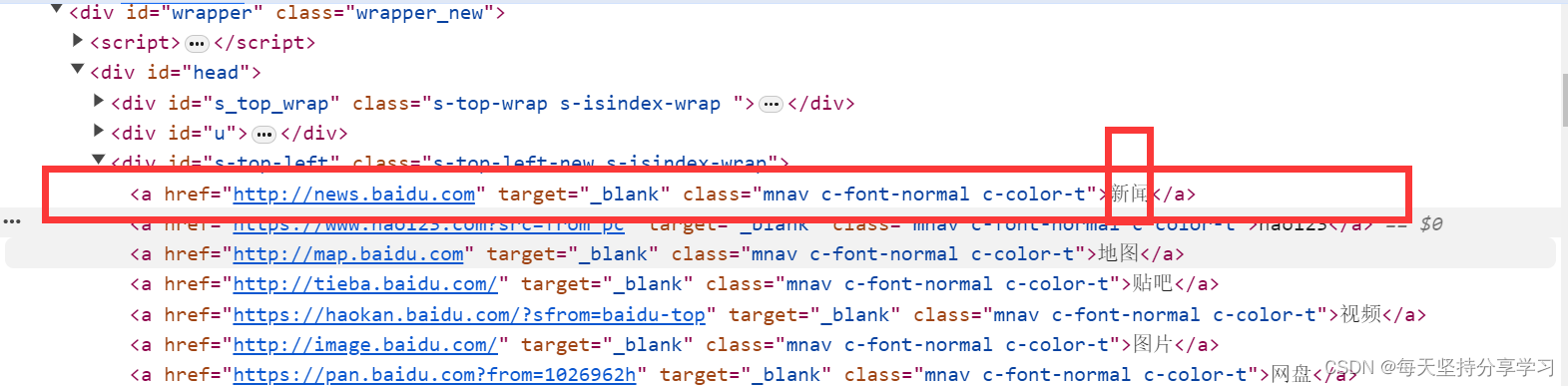
(这个新闻就属于a标签的文本)
link_text
driver.find_element(By.LINK_TEXT,"hao123").click()
partial_link_text
driver.find_element(By.PARTIAL_LINK_TEXT,"hao12").click()
(3)CSS选择器查找(如果不熟悉建议用Xpath的方式)
在CSS中,选择器是选取设置样式的元素的模式
语法:
.class 如.intro 即选择class = 'intro’的所有元素
#id 如#su 即选择id = 'su’的所有元素
[attribute = value] 如[target = bla]即选择属性target=bla的所有元素
注意: 和xpath不一样,CSS的[ ]中括号里面没有引号,但中括号外面有!如 “[target = _blank]”,xpath是里面都有引号。
driver.find_element(By.CSS_SELECTOR,"[target=bla]").click()#CSS定位
示例:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url = "https://www.baidu.com"
driver.get(url)
#打开百度,输入测试
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("测试")
#点击百度
driver.find_element(By.CSS_SELECTOR,".bg.s_btn").click()
time.sleep(3)#避免页面没有加载出来
#点击页面第一个搜索结果
driver.find_element(By.CSS_SELECTOR,".uph6cgn").click()
time.sleep(3)
#成功退出。
driver.quit()
(4)XPATH查找 :只要在XML中,或者HTML中,都可以用这个方式,但是建议优先使用id,name等去定位,实在找不到再用xpath定位
xpath = xml path,XML和HTML都是标签语言,通过标签的嵌套来表达信息,形成了父节点、子节点、后代节点、祖先节点、同胞节点等,而xpath就是用来在这些节点中找到需要的。
(标签又叫标记,也叫元素,也叫节点)
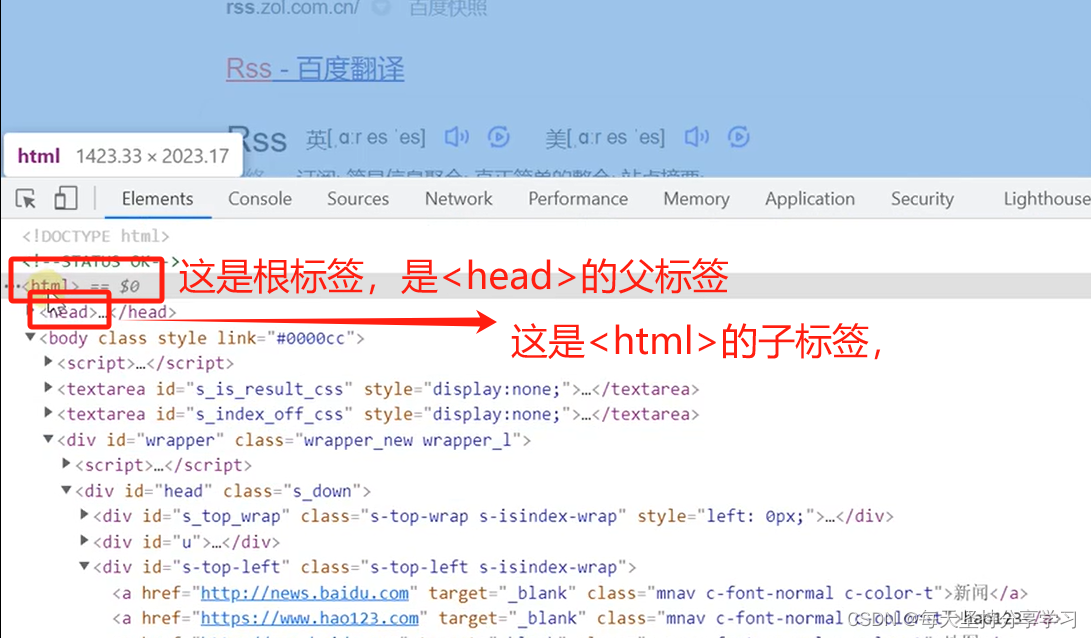

XML的标签可扩展,可自定义。(XPATH国内读叉帕斯,国外读诶克斯帕斯)。
HTML是超文本标记语言,有图片加载等,超出了文本的范畴,标签不能扩展。
xpath表达式:
节点名字:选取此节点的所有子节点
/ 从根节点选取
// 从当前节点选择文档中的节点,而不考虑它们的位置
. 选取当前节点
… 选取当前节点的父节点
获取内容:
@ 选取属性
text() 获取文本
进阶表达式:简便方法(在F12打开开发者工具-》选中一行,右击-》copy-》copy XPath 可以获取xpath)
/bookstore/book[1] 选取属于bookstore子元素的第一个book元素
/bookstore/book[last()] 选取属于bookstore子元素的最后一个book元素
/bookstore/book[last()-1] 选取属于bookstore子元素的倒数第二个book元素
//book/title[text()=‘harry potter’] 选取book下的文本为harry potter的title元素
//div[@lang=“eng”] 选取lang属性为eng的所有div元素 (元素即标签)
注意: 和CSS不一样的是,[ ]里面有引号,外面也有,内外引号要用不一样的。如’//title[@lang=“eng”]’
示例:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url = "https://www.baidu.com"
driver.get(url)
#Xpath 查找,注意引号。
#//*[@id='kw'] 指在任意一个标签,去找id='kw'的元素
driver.find_element(By.XPATH,"//*[@id='kw']").send_keys("美女")
driver.find_element(By.XPATH,"//*[@id='su']").click()
time.sleep(3)
#成功退出。
driver.quit()















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









