







文章目录
用户活跃度
用户活跃度需求分析
- 用户数据是各类应用的重要数据,以美团为例,活跃用户往往可领取蛮多的优惠卷,而且美团普通用户仅需登录注册就可以了,但是有些平台的高级会员具有时效性,比如腾讯,饿了么,美团,京东这类的付费会员。
用户活跃度计算指标
- 新增用户:每日新增用户
- 活跃用户:每日,每周,每月的活跃用户数
- 用户留存:1日,2日,3日会员留存数,1日,2日,3日会员留存率
用户活跃度指标口径业务逻辑
- 用户:以设备作为判断标准,每个独立设备认为是一个用户,Android系统通常根据IMEI号,IOS系统通常根据OpenUDID 来标识一个独立用户,每部移动设备是一个用户
- 活跃用户:打开应用的用户即为活跃用户,暂不考虑用户的实际使用情况。一台设备每天多次打开计算为一个活跃用户,在自然周内启动过应用的会员为周活跃用户,同理还有月活跃用户;
- 用户活跃率:一天内活跃用户数于总用户数的比率是日活跃率;还有周活跃率(自然周)、月活跃率(自然月);
- 新增用户:第一次使用应用的用户,定义为新增用户;卸载再次安装的设备,不会被算作一次新增。新增用户包括日新增用户、周(自然周)新增用户、月(自然月)新增用户
- 留存用户与留存率:某段时间的新增用户,经过一段时间后,仍继续使用应用认为是留存用户;这部分用户占当时新增用户的比例为留存率。
用户活跃度——启动日志数据采集
-
在明确了用户活跃度各项指标后,即可着实从启动日志和事件日志中采集有效数据,将有效数据分离为新增用户数据,活跃用户数据,留存用户数据,并着手建立离线数仓
-
数据采集流程:日志文件——>Flume——>HDFS——>ODS
-
一条原始启动日志数据如下:
2021 - 09 - 16 16: 55: 01.203[main] INFO com.lagou.ecommerce.AppStart - { "app_active": { "name": "app_active", "json": { "entry": "1", "action": "0", "error_code": "0" }, "time": 1595260800000 }, "attr": { "area": "连云港", "uid": "2F10092A1", "app_v": "1.1.8", "event_type": "common", "device_id": "1FB872-9A1001", "os_type": "0.43", "channel": "PN", "language": "chinese", "brand": "iphone-7" } }
数据采集流程
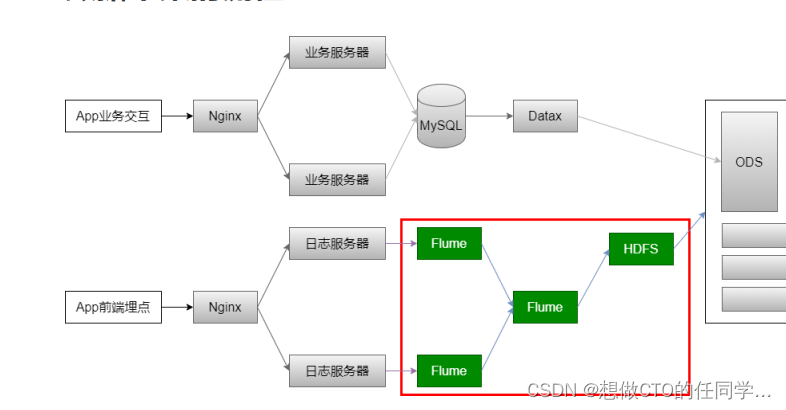
- 原始数据采集有两种方式,一种是从业务服务器上采集,另一种是从日志服务器上采集(学习的项目是从日志服务器上采集),并且使用Flume作为采集日志数据的工具(参考的Flume开发文档:https://flume.liyifeng.org/)
- 在此项目中,使用Flume时,选择的source为taildir Source,选择的channels为memorychannel,选择的sink为hdfs sink。
- taildir Source的特点:
- 监控的文件中,一旦有数据写入,Flume就会将信息写入到指定的Sink中
- 高可靠,不会丢失数据
- 不会对跟踪文件有任何处理,不会重命名也不会删除
- 不支持Windows,不能读二进制文件。支持按行读取文本文件
- memorychannel:将数据缓存到内存中
- hdfs sink::将 events 写进HDFS。支持创建文本和序列文件,支持两种文件类型压缩。文件可以基于数据的经过时间、大小、事件的数量周期性地滚动
Flume Agent的配置文件:
- taildir source配置
- positionFile:配置检查点文件的路径,检查点文件会以 json 格式保存已经读取文件的位置,解决断点续传的问题
- filegroups:指定filegroups,可以有多个,以空格分隔(taildir source可同时监控多个目录中的文件)
- filegroups:配置每个filegroup的文件绝对路径,文件名可以用正则表达式匹配
- hdfs sink都会采用滚动生成文件的方式,滚动生成文件的策略有:
- 基于时间。hdfs.rollInterval 30秒
- 基于文件大小。hdfs.rollSize 1024字节
- 基于event数量。hdfs.rollCount 10个event
- 基于文件空闲时间。hdfs.idleTimeout 0
- 0,禁用
- minBlockReplicas。默认值与 hdfs 副本数一致。设为1是为了让 Flume 感知不到hdfs的块复制,此时其他的滚动方式配置(时间间隔、文件大小、events数量)才不会受影响
完整Flume Agent的配置文件如下
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# taildir source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /data/lagoudw/conf/startlog_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/lagoudw/logs/start/.*log
# memorychannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 2000
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/start/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 1000
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
解决java.lang.OutOfMemoryError: GC overhead limit exceeded
-
原因:缺省情况下 Flume jvm堆最大分配20m,这个值太小,需要调整。
-
解决方案:在 $FLUME_HOME/conf/flume-env.sh 中增加以下内容
export JAVA_OPTS="-Xms4000m -Xmx4000m -Dcom.sun.management.jmxremote" # 要想使配置文件生效,还要在命令行中指定配置文件目录 flume-ng agent --conf /opt/apps/flume-1.9/conf --conf-file /data/lagoudw/conf/flume-log2hdfs1.conf -name a1 -Dflume.root.logger=INFO,console flume-ng agent --conf-file /data/lagoudw/conf/flume-log2hdfs1.conf -name a1 -Dflume.root.logger=INFO,console -
Flume内存参数设置及优化:
- 根据日志数据量的大小,Jvm堆一般要设置为4G或更高
- -Xms -Xmx 最好设置一致,减少内存抖动带来的性能影响
解决采集启动日志时,因使用了本地时间,可能导致数据存放的路径不正确
- Flume Agent 的配置使用了本地时间,可能导致数据存放的路径不正确,要解决这个问题需要使用自定义拦截器。
- agent用于测试自定义拦截器。netcat source =>logger sink
- 采集启动日志(使用自定义拦截器)
自定义拦截器的原理
- 自定义拦截器要集成Flume 的 Interceptor
- Event 分为header 和 body(接收的字符串)
- 获取header和body
- 从body中获取"time":1596382570539,并将时间戳转换为字符串 “yyyy-MM-dd”
- 将转换后的字符串放置header中
自定义拦截器的实现
- 获取 event 的 header
- 获取 event 的 body
- 解析body获取json串
- 解析json串获取时间戳
- 将时间戳转换为字符串 “yyyy-MM-dd”
- 将转换后的字符串放置header中
- 返回event
单独采集启动日志(使用自定义拦截器)
- 给source增加自定义拦截器
- 去掉本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true
- 根据header中的logtime写文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# taildir source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /data/lagoudw/conf/startlog_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/lagoudw/logs/start/.*log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type =cn.lagou.dw.flume.interceptor.CustomerInterceptor$Builder
# memorychannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 2000
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/start/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 1000
# 使用本地时间
# a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
同时采集启动日志、事件日志
- 本项目需要采集两种日志:启动日志,事件日志,不同的日志放置在不同的目录下,要想一次拿到全部日志需要监控多个目录。
- 同时监控多个目录:需要使用taildir监控多个目录,并且修改自定义拦截器,不同来源的数据加上不同标志,其次还要使用hdfs sink 根据标志写文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# taildir source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /data/lagoudw/conf/startlog_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /data/lagoudw/logs/start/.*log
a1.sources.r1.headers.f1.logtype = start
a1.sources.r1.filegroups.f2 = /data/lagoudw/logs/event/.*log
a1.sources.r1.headers.f2.logtype = event
# 自定义拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type =cn.lagou.dw.flume.interceptor.LogTypeInterceptor$Builder
# memorychannel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 2000
# hdfs sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /user/data/logs/%{logtype}/dt=%{logtime}/
a1.sinks.k1.hdfs.filePrefix = startlog.
a1.sinks.k1.hdfs.fileType = DataStream
# 配置文件滚动方式(文件大小32M)
a1.sinks.k1.hdfs.rollSize = 33554432
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.idleTimeout = 0
a1.sinks.k1.hdfs.minBlockReplicas = 1
# 向hdfs上刷新的event的个数
a1.sinks.k1.hdfs.batchSize = 1000
# 使用本地时间
# a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- filegroups:指定filegroups,可以有多个,以空格分隔(taildir source可同时监控多个目录中的文件)
headers.<filegroupName>.<headerKey> - 给 event 增加header key。不同的filegroup,可配置不同的value















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









