







RDD的分区
-
spark.default.parallelism:(默认的并发数)= 2,当配置文件spark-default.conf中没有显示的配置,则按照如下规则取值:
- 本地模式
spark-shell --master local[N] spark.default.parallelism = N spark-shell --master local spark.default.parallelism = 1 - 伪分布式(x为本机上启动的executor数,y为每个executor使用的core数,z为每个 executor使用的内存)
spark-shell --master local-cluster[x,y,z] spark.default.parallelism = x * y - 分布式模式(yarn & standalone)
spark.default.parallelism = max(应用程序持有executor的core总数, 2)
- 本地模式
-
配置文件spark-default.conf中没有显示的配置。如果配置了,则spark.default.parallelism = 配置的值
-
SparkContext初始化时,同时会生成两个参数,由上面得到的
// 从集合中创建RDD的分区数 sc.defaultParallelism = spark.default.parallelism // 从文件中创建RDD的分区数 sc.defaultMinPartitions = min(spark.default.parallelism, 2)
创建 RDD 的几种方式
-
通过集合创建,如果创建RDD时没有指定分区数,则rdd的分区数 = sc.defaultParallelism
val rdd = sc.parallelize(1 to 100) rdd.getNumPartitions -
通过textFile创建
val rdd = sc.textFile("data/start0721.big.log") rdd.getNumPartitions -
如果没有指定分区数:
- 本地文件。rdd的分区数 = max(本地文件分片数, sc.defaultMinPartitions)
- HDFS文件。 rdd的分区数 = max(hdfs文件 block 数, sc.defaultMinPartitions)
- 本地文件分片数 = 本地文件大小 / 32M
- 如果读取的是HDFS文件,同时指定的分区数 < hdfs文件的block数,指定的数不生效
RDD分区器
- 只有Key-Value类型的RDD才可能有分区器,Value类型的RDD分区器的值是None。
分区器的作用及分类:
-
在 PairRDD(key,value) 中,很多操作都是基于key的,系统会按照key对数据进行重组,如groupbykey;
-
数据重组需要规则,最常见的就是基于 Hash 的分区,此外还有一种复杂的基于抽样Range 分区方法;
-
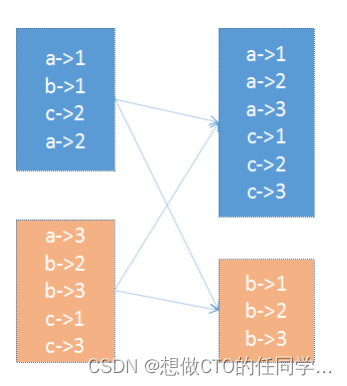
HashPartitioner:最简单、最常用,也是默认提供的分区器。对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则用 余数+分区的个数,最后返回的值就是这个key所属的分区ID。该分区方法可以保证key相同的数据出现在同一个分区中。
-
可通过partitionBy主动使用分区器,通过partitions参数指定想要分区的数量。
val rdd1 = sc.makeRDD(1 to 100).map((_, 1)) rdd1.getNumPartitions // 仅仅是将数据大致平均分成了若干份;rdd并没有分区器 rdd2.glom.collect.foreach(x=>println(x.toBuffer)) rdd1.partitioner // 主动使用 HashPartitioner val rdd2 = rdd1.partitionBy(new org.apache.spark.HashPartitioner(10)) rdd2.glom.collect.foreach(x=>println(x.toBuffer)) // 主动使用 HashPartitioner val rdd3 = rdd1.partitionBy(new org.apache.spark.RangePartitioner(10, rdd1)) rdd3.glom.collect.foreach(x=>println(x.toBuffer)) -
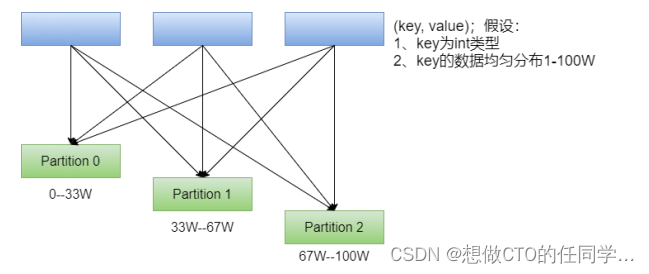
RangePartitioner:简单的说就是将一定范围内的数映射到某一个分区内。在实现中,分界的算法尤为重要,用到了水塘抽样算法。sortByKey会使用RangePartitioner。
-
在执行分区之前其实并不知道数据的分布情况,如果想知道数据分区就需要对数据进行采样;Spark中RangePartitioner在对数据采样的过程中使用了水塘采样算法。
-
水塘采样:从包含n个项目的集合S中选取k个样本,其中n为一很大或未知的数量,尤其适用于不能把所有n个项目都存放到主内存的情况;在采样的过程中执行了collect()操作,引发了Action操作
-
自定义分区器:Spark允许用户通过自定义的Partitioner对象,灵活的来控制RDD的分区方式。
实现自定义分区器按以下规则分区:
分区0 < 100
100 <= 分区1 < 200
200 <= 分区2 < 300
300 <= 分区3 < 400
... ...
900 <= 分区9 < 1000
import org.apache.spark.rdd.RDD
import org.apache.spark.{Partitioner, SparkConf, SparkContext}
import scala.collection.immutable
class MyPartitioner(n: Int) extends Partitioner{
// 有多少个分区数
override def numPartitions: Int = n
// 给定key,如果去分区
override def getPartition(key: Any): Int = {
val k = key.toString.toInt
k / 100
}
}
object UserDefinedPartitioner {
def main(args: Array[String]): Unit = {
// 创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
// 业务逻辑
val random = scala.util.Random
val arr: immutable.IndexedSeq[Int] = (1 to 100).map(idx => random.nextInt(1000))
val rdd1: RDD[(Int, Int)] = sc.makeRDD(arr).map((_, 1))
rdd1.glom.collect.foreach(x => println(x.toBuffer))
println("************************************************************************")
val rdd2 = rdd1.partitionBy(new MyPartitioner(11))
rdd2.glom.collect.foreach(x => println(x.toBuffer))
// 关闭SparkContext
sc.stop()
}
}
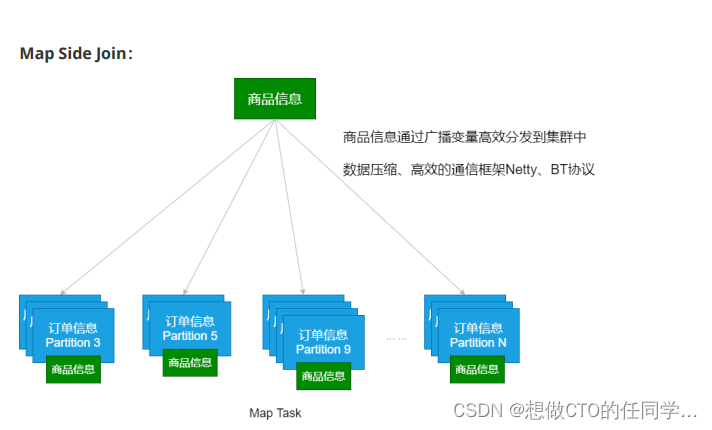
广播变量
- 有时候需要在多个任务之间共享变量,或者在任务(Task)和Driver Program之间共享变量。为了满足这种需求,Spark提供了两种类型的变量:广播变量(broadcast variables)和累加器(accumulators)。广播变量、累加器主要作用是为了优化Spark程序
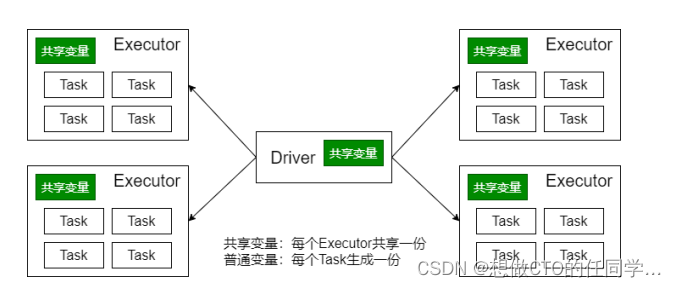
- 广播变量将变量在节点的 Executor 之间进行共享(由Driver广播出去);
- 广播变量用来高效分发较大的对象。向所有工作节点(Executor)发送一个较大的只读值,以供一个或多个操作使用。
- 使用广播变量的过程如下:
- 对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T]对象。 任何可序列化的类型都可以这么实现(在 Driver 端)
- 通过 value 属性访问该对象的值(在 Executor 中)
- 变量只会被发到各个 Executor 一次,作为只读值处理
- 广播变量的相关参数:
- spark.broadcast.blockSize(缺省值:4m)
- spark.broadcast.checksum(缺省值:true)
- spark.broadcast.compress(缺省值:true)
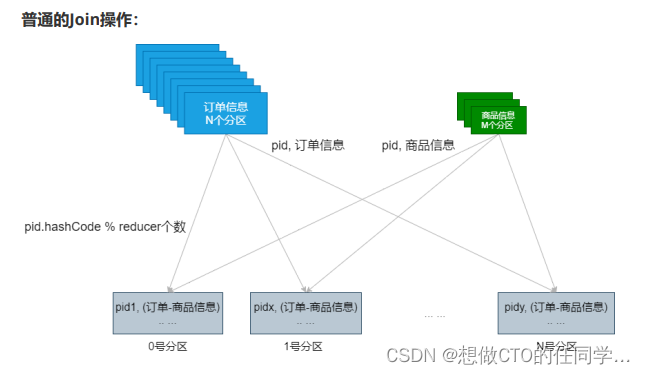
广播变量的运用(Map Side Join)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object JoinDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName.init)
val sc = new SparkContext(conf)
// 设置本地文件切分大小
sc.hadoopConfiguration.setLong("fs.local.block.size", 128*1024*1024)
// map task:数据准备
val productRDD: RDD[(String, String)] = sc.textFile("data/lagou_product_info.txt")
.map { line =>
val fields = line.split(";")
(fields(0), line)
}
val orderRDD: RDD[(String, String)] = sc.textFile("data/orderinfo.txt",8 )
.map { line =>
val fields = line.split(";")
(fields(2), line)
}
// join有shuffle操作
val resultRDD: RDD[(String, (String, String))] = productRDD.join(orderRDD)
println(resultRDD.count())
Thread.sleep(1000000)
sc.stop()
}
}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object MapSideJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName.init)
val sc = new SparkContext(conf)
// 设置本地文件切分大小
sc.hadoopConfiguration.setLong("fs.local.block.size", 128*1024*1024)
// map task:数据准备
val productMap: collection.Map[String, String] = sc.textFile("data/lagou_product_info.txt")
.map { line =>
val fields = line.split(";")
(fields(0), line)
}.collectAsMap()
val productBC: Broadcast[collection.Map[String, String]] = sc.broadcast(productMap)
val orderRDD: RDD[(String, String)] = sc.textFile("data/orderinfo.txt",8 )
.map { line =>
val fields = line.split(";")
(fields(2), line)
}
// 完成map side join操作。
// RDD[(String, (String, String))]:(pid, (商品信息,订单信息))
val resultRDD: RDD[(String, (String, String))] = orderRDD.map { case (pid, orderInfo) =>
val productInfoMap: collection.Map[String, String] = productBC.value
val produceInfoString: String = productInfoMap.getOrElse(pid, null)
(pid, (produceInfoString, orderInfo))
}
println(resultRDD.count())
Thread.sleep(1000000)
sc.stop()
}
}
累加器
- 累加器的作用:可以实现一个变量在不同的 Executor 端能保持状态的累加;累计器在 Driver 端定义,读取;在 Executor 中完成累加;
- 累加器也是 lazy 的,需要 Action 触发;Action触发一次,执行一次,触发多次,执行多次;
- 累加器一个比较经典的应用场景是用来在 Spark Streaming 应用中记录某些事件的数量;
val data = sc.makeRDD(Seq("hadoop map reduce", "spark mllib"))
// 方式1
val count1 = data.flatMap(line => line.split("\\s+")).map(word => 1).reduce(_ + _)
println(count1)
// 方式2。错误的方式
var acc = 0
data.flatMap(line => line.split("\\s+")).foreach(word => acc += 1)
println(acc)
// 在Driver中定义变量,每个运行的Task会得到这些变量的一份新的副本,但在
Task中更新这些副本的值不会影响Driver中对应变量的值
- Spark内置了三种类型的累加器,分别是
- LongAccumulator 用来累加整数型
- DoubleAccumulator 用来累加浮点型
- CollectionAccumulator 用来累加集合元素
val data = sc.makeRDD("hadoop spark hive hbase java scala hello world spark scala java hive".split("\\s+")) val acc1 = sc.longAccumulator("totalNum1") val acc2 = sc.doubleAccumulator("totalNum2") val acc3 = sc.collectionAccumulator[String]("allWords") val rdd = data.map { word => acc1.add(word.length) acc2.add(word.length) acc3.add(word) word } rdd.count rdd.collect println(acc1.value) println(acc2.value) println(acc3.value)
topN
object TopN {
def main(args: Array[String]): Unit = {
// 创建SparkContext
val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val N = 9
// 生成数据
val random = scala.util.Random
val scores: immutable.IndexedSeq[String] = (1 to 50).flatMap { idx =>
(1 to 2000).map { id =>
f"group$idx%2d,${random.nextInt(100000)}"
}
}
val scoresRDD: RDD[(String, Int)] = sc.makeRDD(scores).map { line =>
val fields: Array[String] = line.split(",")
(fields(0), fields(1).toInt)
}
scoresRDD.cache()
// TopN的实现
// groupByKey的实现,需要将每个分区的每个group的全部数据做shuffle
scoresRDD.groupByKey()
.mapValues(buf => buf.toList.sorted.takeRight(N).reverse)
.sortByKey()
.collect.foreach(println)
println("******************************************")
// TopN的优化
scoresRDD.aggregateByKey(List[Int]())(
(lst, score) => (lst :+ score).sorted.takeRight(N),
(lst1, lst2) => (lst1 ++ lst2).sorted.takeRight(N)
).mapValues(buf => buf.reverse)
.sortByKey()
.collect.foreach(println)
// 关闭SparkContext
sc.stop()
}
}















 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









