







查找
8.6 B-树
二叉排序树比较适合于在内存中组织较小的索引。对于存放在外存中的较大的文件系统,用二叉排序树来组织索引就不太合适了。若以结点作为内外存交换的单位,则在查找过程中需对外存进行 log2n 次访问,显然很费时。因此在文件检索系统中大最使用的是用B-树或 B+树做文件案引。
8.6.1 动态的m路查找树
- m路查找树定义:
它或者是一棵空树,或者是满足如下性质的树。
1)根结点 最多有m棵子树,并具有如下的结构:(n,p0,k1,p1,k2,p2,…,kn,pn)。其中,pi是指向子树的指针,ki是数据元素的关键字:1<=i<=n<m。
2)ki<ki+1,1<=i<n。
3)在Pi所指的子树中所有的数据元素的关键字都小于ki+1,且大于ki,0<i<n。
4)在pn所指的子树中所有数据元素的关键字都大于kn,而子树P0中的所有数据元素的关键字都小于k1。
5)pi所指的子树也是m路查找树,0<=i<=n。
类似静态表的分块(索引)查找。根节点可有m个子树,并且子树有序。每个子树有n,p0,k1,p1,k2,p2,…,kn,pn。n<p0<k1。 - 一个具体例子
下图是一棵三路查找树,它有9个数据元素。每个结点最多有三棵子树,因而最多有两个数据元素;但最少有一个数据元素(有0棵子树)。
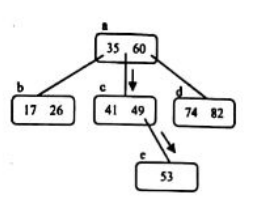
在这棵三路查找树中,结点a的格式为(2,b, 35,c,60,d);结点b上所有数据元素的关键字均小于35;结点c上所有数据元素的关键字都介于35~60;结点d上所有数据元素的关键字都大于60;结点e中所有数据元素的关键字均大于49,但要小于60。
如果想查找关键字为53的数据元素,需要从根开始查找。首先从磁盘中读入结点a,沿35与60之间的子树指针找到结点c:再读入结点c,沿30 右侧子树指针找到结点,最后读入结点c,在结点e中找到关键字为53的数据元素。 - 对于一棵m路查找树,适当提高查找树的路数m,可以改善m路查找树的查找性能。如果查找树是平衡的,可以使m路查找树的查找性能接近最佳。
8.6.2 B-树
(1)B-树的定义
一棵m阶B-树是一棵平衡的m路查找树,它具有如下的特性。
1)根结点至少有两个孩子。
2)除根结点以外的所有结点(不包括失败结点)至少有⌈m/2⌉ (向上取整)个孩子。
3)所有的失败结点都位于同一层。事实上,这些结点都是作为外部结点存在,不是B树上的结点,可以视为查找失败时才能到达的结点,指向它们的指针都为空值。

【本图来自:https://blog.csdn.net/u011109881/article/details/80344606】
- 一个具体例子
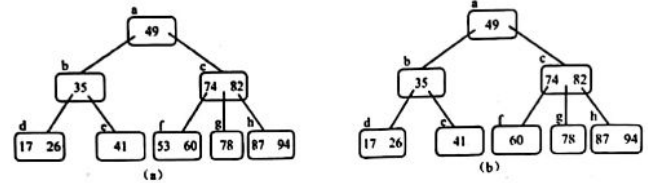
下图(a)是一棵三阶B-树,灰色所示的结点为败结点,实现时用空指针表示。它的所有失败结点都在同一层上:而图(b)就不是B-树。

在图(a)所示的B-树中查找关键字为53的数据元素,首先通过根指针找到根结点a,进行关键字的比较:53>49,因此按49的右侧指针找到下一层结点c;在结点c中进行关键字比较:53<60,沿60的左侧指针找到下一层结点f;最后在结点f中进行关键字比较:53=53,查找成功,报告结点地址及在结点中的关键字序号。
但如果想查找的是关键字为58的数据元素。前面的过和查找关键字为53的数据元素一样,在结点f中做关键字比较:58>53,沿53的有侧指针向下一层查找,结果到达失败结点,所以查找失败。 - B-树的查找过程是一个在结点内查找和按某一条路径向下一层查找交替进行的过程。
显然,如果【提高B-树的阶数m】,可以减少树的高度,从而减少读入结点的次数,因而可减少读磁盘的次数。事实上,m受到内存可使用空间的限制。当m很大超出内存工作区容量时,结点不能一次读入到内存。增加了读盘次数,也增加了结点内查找的难度。 - 如果将结点中的有序关键字序列放入内存,进行优化查找(可以用折半),相比查找代价极低。而B树的高度很小,因此在这一背景下,B树比任何二叉结构查找树的效率都要高很多。
- 如何选择合理的m值?前提应是使得在B-树中找到关键字k的时间总量达到最小。这个时间由两部分组成:
(1)从磁盘中读人结点所用时间;
(2)在结点中查找关键字为k的数据元素所用时间。
因此,B-树的查找时间与B-树的阶数m和B-树的高度h直接有关,必须加以权衡。
//B-树的阶,暂设3
#define m 3
typedef int KeyType;
typedef struct BTNode{
int keynum;//关键字个数,即结点大小
struct BTNode *parent;
KeyType key[m+1];//关键字向量 0号不用
struct BTNode *ptr[m+1];//子树指针向量,关键词m个指针m+1个
Record *recptr[m+1];//记录指针向量,0号未用
}BTNode,*Btree;
typedef struct
{
BTNode *pt;//指向找到的结点
int i;//关键字在结点中的序号
int tag;//0失败1成功
}Result;
/** B-树查找操作
* 在m阶B-树T上查找关键字K,返回结果(pt,i,tag)。
* 若查找成功,tag=1,pt所指结点中第i个关键字等于K;
* 否则tag=0,K的关键字应插入在pt所指结点中第i和i+1个关键字之间。**/
Result SearchBTree(Btree T,KeyType K){
BTNode *p=T,*q=NULL;
bool found=false;
int i=0;
//初始化p指向待查节点,q指向p的双亲
while(p&&!found){
i=Search(p,K);//在P->key[1...keynum]中查找i使得 p->key[i] <= K <p->key[i+1]
if(i>0 && p->key[i]==K) found=true;
else{
q=p;p=p->ptr[i];
}
}
if(found) return (p,i,1);//查找成功
else return (p,i,0);//查找失败,返回K的插入位置信息
}
(2)B-树的插入
- B-树的插入是在查找失败时进行的,因而总是插在某个叶结点(即最底层的非失败结点)内。在一棵m阶B-树中。每个非失败结点的关键字个数都在(⌈m/2⌉-1) ~ (m-1)。如果在关键字插入后结点中的关键字个数未超出上述范围的上界m-1,则可以直接插入;否则结点需要“分裂”。
- 实现结点“分裂”的原则是:设结点p中已经有m-1 个关键字,当再插入一个关键字后结点中的状态为(m,P0, K1,P1, K2,P2,…,Km, Pm)其中Ki<Ki+1,1<=i<m。
这时必须把结点p分裂成两个结点p和p’,它们包含的信息分别为:
结点p:(⌈m/2⌉-1,P0,K1,P1,…,K⌈m/2⌉-1,P⌈m/2⌉-1);
结点p’:(m-⌈m/2⌉,P⌈m/2⌉,K⌈m/2⌉+1,P⌈m/2⌉+1,…,Km,Pm)。
位于中间的关键字K⌈m/2⌉与指向新结点p‘的指针形成一个二元组(K⌈m/2⌉,p’),并插入这两个结点的双亲结点中去。 - 例如,当m=3时,所有结点最多有两个关键字。若当结点中已经有两个关键字时,结点己满,如图(a)所示。如果再插入一个关键字 75,则结点中的关键字个数为3,超出了m-1,如图(b)所示。此时必须进行结点分裂,分裂的结果如图(c)所示。

- 用此方法可以建立B-树。
例如插入关键字序列{ 35,26,74,60,49,17,41,53 },建立三阶B-树。

上例中,当n=1时,树的高度为1。再加入关键字26,因根结点中关键字个数没有超出 m-1,26 可直接插入,树的高度不变。当再在根结点中插入74后,根结点中关键字个数为3,已超过结点中关键字个数的上限2,必须按结点“分裂”的原则进行处理,树的高度加到2。一般地,若在3阶B-树中总的关键字个数为N,则树的高度为h<=log2((N+1)/2)+1。当N=7时,h<=log2((N+1)/2)+1=3。 - 设B-树的高度为h,那么在自顶向下查找叶结点的过程中需要经过h个结点。在最坏情况下需要自底向上分裂结点,从被插关键字所在叶结点到根的路径上的所有结点都要分裂。因此,完成一次插入操作时,最多需要读写磁盘的次数=(查找插入结点而进行的读盘次数)+(分裂结点而进行的写盘次数)=2h。
/** B树的插入
* 在m阶B-数T上结点*取得key[i]与key[i+1]之间插入关键字K。
* 若引起结点过大,则沿双亲链进行必要的结点分裂调整,使T仍是m阶B树。
* **/
Status InsertBTree(Btree &T,KeyType K,BTree q,int i){
KeyType x=K;
BTNode *ap=NULL;//最先插入的是叶子结点,没有子树
bool finished=false;
while (q && !finished)
{
Insert(q,i,x,ap);//将x和ap分别插入到q->key[i+1]和q->ptr[i+1]
if(q->keynum <m) finished=true;//当前结点关键字个数小于m,插入完成,退出循环
else{//没有插入完成,需要分裂
//将q->key[s+1..m],q->ptr[s..m]和q->recptr[s+1..m]移入新结点*ap
s=(int)(m-1)/2+1;//拆分后结点的元素信息(1..s)给当前结点,后面的信息从s指针和s+1关键字给新生成的结点ap
split(q,s,ap);//依据s将q拆分为两个结点,
x=q->key[s];//拆分的关键字是x,将要移入原节点的父亲节点
q=q->parent;
if(q) i=Search(q,x);//在双亲结点*q中查找x的插入位置
}
}
if(!finished) //如果T是孔数,或者根节点已经分裂为结点,
NewRoot(T,q,x,ap);//*q和*ap生成含信息(T,x,ap)的新的根节点*T,原T和ap为子树指针
return OK;
}
(3)B-树的删除
- 如果想要在B-树上删除一个关键字,首先需要找到这个关键字所在的结点,从中删去这个关键字。若该结点不是叶结点,且被删关键字为Ki(1<=i<=n),则在删去该关键字之后,可以用该结点的Pi所指子树中的最小关键字k(或Pi-1所指子树中的最大关键字k)来代替被删关键字Ki,然后在k所在的叶结点中删除k。
- 在叶结点中删除关键字有以下四种情况需要分别讨论。
1)若被删关键字所在叶结点同时又是根结点且删除前该结点中关键字个数n>=2,则直接删去该关键字并将修改后的结点写回磁盘,删除结束。
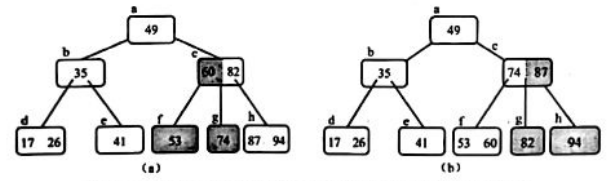
2)若被删关键字所在叶结点不是根结点,且刷除前该结点中关键字个数n>=⌈m/2⌉,则可直接从该叶结点中删除该关键字。 - 例如,在图(a)所示的三阶 B-树中删除关键字53,由于关键字53所在的叶结点中关键字的个数为2,等于⌈m/2⌉=2。因此可以直接删除叶结点f中的关键字53。
3)被删关键字所在叶结点删除前关键字个数n=⌈m/2⌉-1,若这时与该结点相邻的左(或右)兄弟结点的关键字个数n>=⌈m/2⌉,则可按以下步骤调整该结点、左(或右)兄弟结点以及其双亲结点,以达到新的平衡。 - ①将其双亲结点中大于(或小于)该删关键字的所有关键字最小(或最大)的一个关键字Ki下移到被删关键字所在结点中。
- ②将左(或右)兄弟结点中的最大(或最小)关键字上移到双亲结点的k位置。
- ③ 将左(或右)兄弟结点中的最右(或最左)子树指针删除,并将结点中的关键字个数减1。
- 例如,在图(a)所示的三阶B-树中删除关键字78,由于关键字78所在的叶结点g中关键字的个数为1,等于⌈m/2⌉-1,而此时与结点g的相邻的左、右兄弟结点的关键字个数都等于⌈m/2⌉=2,因此,在删除叶结点f中关键字78后,可以考虑从结点g的双亲结点c中下移关键字74,再从结点g的左兄弟结点f中上移最大关键字60,结果如图(a)所示。当然也可以在删除叶结点f中关键字78后,从结点g的双亲结点c中下移关键字82,再从结点g的右兄弟结点h中上移最小关键字87,结果如图(b)所示。
4)被删关键字所在叶结点p删除前关键字个数n=⌈m/2⌉-1,若这时与该结点相邻的左、右兄弟结点中的关键字个数也都为⌈m/2⌉-1,则必须按以下步骤合并这两个结点。 - ①将双亲结点中大于(或小于)该被删关键字的所有关键字中最小(或最大)的一个关键字Ki下移到p结点中,将p和p的左(或右)兄弟结点合并。
- ②修改p结点和其双亲结点关键字个数。
- ③在合并结点的过程中,双亲结点中的关键字个数减少了1。若p的双亲结点是根结点且结点关键字个数减到0,则该双亲结点应从树上删去,合并后保密的p结点成为新的根结点;若双亲结点f不是根结点,且关键字个数减到⌈m/2⌉-2,则结点f又要与它自己的兄弟结点合并。重复上而的合并步骤,最坏情况下这种结点合并处理要自下向上直到根结点。
- 例如,在图(a)所示的三阶B-树中删除关键字78,由于关键字78所在的叶结点g中关键字的个数为1,等于⌈m/2⌉-1,而此时与结点g的相邻的左、右兄弟结点的关键宁个数也都等于1,因此,在删除叶结点g中关键字78后,可以考虑从结点g的双亲结点c中下移关键字74,再把结点g和其左兄弟结点f合并为一个结点,结果如图(b)所示。当然也可以在删除叶结点g中关键字 78后,从结点g的双亲结点c中下移关键字82,再把结点g和其右兄弟结点h合并为一个结点。
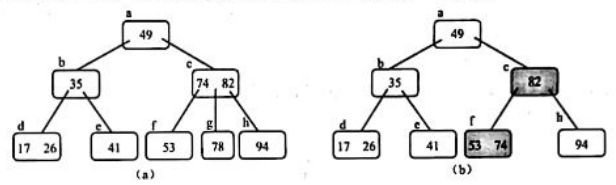
- 一个具体例子
在图(a)所示的三阶B-树中依次删除关键字78、60和41后进行关键字的替代、结点的合并和调整的过程。
删除关键字78时,将其双亲结点c中关键字74下移,再将其左兄弟结点f中的关键字60上移,结果如图(b)所示。
删除关键字60时,先将其左子树中的最大关键字53替代关键字60,然后再删除关键字53是需要进行结点的合并,结果如图(c) 所示。
删除关键字41时,先将其左子树中的最大关键字35 替代关键字41,然后再删除关键字35,这时是需要进行两次结点的合并:先将结点d、结点e及其双亲结点中关键字26合并成一个结点,再将结点b(此时结点b已经没有关键字)、结点c及其双亲结点中关键字41合并成一个结点,结果如图(d)所示。

8.6.5 B+树
B+树可以看作是B-树的一种变形,在实现文件索引结构方面比B-树使用得更普遍。
(1)B+树的定义
- 一棵m阶B+树 定义如下:
1)树中每个非叶结点最多有m棵子树。
2)根结点至少有两棵子树。除根结点外,其他的非叶结点至少有⌈m/2⌉棵子树;有n棵子树的非叶结点中含有有n个关键字,且按由小到大的顺序排列。
3)所有的叶结点都处于同一层次上,包含了全部关键字及指向相应数据元素的指针,且叶结点本身按关键字从小到大顺序链接。
4)所有的非叶结点可以看成是索引部分,结中关键字K与指向子树的指针P构成一个索引项(Ki,Pi)。其中Ki是Pi所指向的子树中最大(或最小)的关键字。
下图给出一棵四阶B+树的示例。
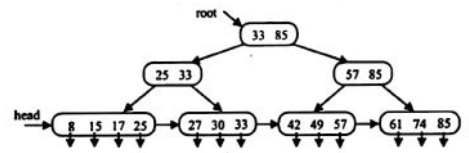
- 通常在 B+树中有两个头指针:一个指向B+树的根结点,一个指向关键字最小的叶结点。
- 因此,可以对 B+树进行两种查找操作:
(1)对叶结点之间的链表进行顺序查找;
(2)从根结点开始,进行自顶向下,直至叶结点的随机查找。 - 在B+树上进行随机查找、插入和删除的过程基本上与B-树类似。只是在查找过程中,如果非叶结点中的某个关键字等于给定值,查找并不停止,而是继续沿相应指针向下,一直查到叶结点上的这个关键字,然后才能根据相应的地址指针找到数据元素。
- 因此,在B+树中,不论查找成功与否,每次查找都是走了一条从根到叶结点的路径。
(2)B+树的插入
B+树的插入仅在叶结点上进行。每插入一个关键字后都要判断结点中的子树棵数是否超出范围。当插入后结点中的子树棵数n>m时,需要将叶结点分裂为两个结点,它们所包含的关键字个数分别为 ⌈(ml+1)/2⌉ 和 ⌊(ml+1)/2⌋。 并且它们的双亲结点中应同时包含这两个结点的最大关键字和指向这两个结点指针。当根结点分裂时,因为它没有双亲结点,就必须创建新的双亲结点,作为树的新根。这样树的高度就增加一层了。B+树的建立可以从空树开始,通过不断插入关键字完成。
(3)B+树的删除
- B+树的删除也仅在叶结点中进行。
- 若在叶结点中删除一个关键字后,其关键字的个数仍然不少于⌈m/2⌉,这属于简单删除,其上层索引可以不改变。
- 例如,在上图所示的4阶B+树中删除关键字为25,它是该结点的最大关键字,因在其上层的关键字25只是起了一个引导查找的“分界关键字”的作用,所以即使树的叶子中已经删除了关键字25,但是其上层结点中的关键字25仍然可以保留。
- 如果在叶结点中删除一个关键字后,其关键字的个数小于结点关键字的个数的下限⌈m/2⌉,则必须做结点的调整或合并工作。
- 例如,在上图所示的四阶B+树中从叶结点中删除关键字42和49后,该结点中的关键字个数为1,小于结点关键字的个数的下限2,这时看它的右兄弟结点,发现右兄弟结点中的关键字的个数为3,大于结点关键字的个数的下限2,因此可从其右兄弟结点中移最左关键字到这个被删关键字所在的结点中,使得两个结点中关键字的个数都符合要求。
- 由于将其右兄弟结点中最左关键字移到这个被删关键字所在的结点后,该关键字成为该结点中最大关键字,所以其上层结点中的“分界关键字”必须用此最大关键字替换原来的“分界关键字”。
如果右兄弟结点的子树棵数也已达到下限⌈m/2⌉,即没有多余的关键字可以移入被删关键字所在的结点,在这种情况下,必须进行两个结点的合并。将右兄弟结点中的所有关键字和指针索引项移入被删关键字所在结点,再将右兄弟结点删去。 - 这种结点合并将导致双亲结点中“分界关键字”的减少,有可能引起非叶结点的调整或合并。如果根结点仅有的两个孩子结点需要合并,则树的层数就会减少一层。
总结
| 动态m路查找树 | m阶B-树 | m阶B+树 | |
|---|---|---|---|
| 本质 | 多路查找树 | 平衡多路查找树 | 不为空的平衡多路查找树 |
| 根结点 | 空树/最多m棵子树 | 空树/至少2棵子树【可以是叶子结点】 | 至少有2棵子树【不能为空树,也不能为叶子结点】 |
| 非根节点&非终端的结点 | (n,p0,k1,p1,k2,p2,…,kn,pn) | 至少有⌈m/2⌉棵子树;(n,A0,K1,A1,K2,A2,…,Kn,An)[同m路查找树] | 至少有⌈m/2⌉棵子树【有n棵子树的结点中含有n个关键字,由小到大排列】;(含根)非叶节点可以看成索引项(Ki,Pi) |
| 终端节点(叶子节点) | 出现在同一层次,并且不带信息 | 处于同一层子,包含全部关键字及指向相应数据元素的指针&叶节点按关键字从小到大链接 | |
| 关键字 | m-1个关键字;含m个关键字有m+1阶;关键字在每个结点上,不集中,路径不重复 | m个关键字;含m个关键字有m阶;关键字集中在叶节点,路径关键字重复 | |
| 特点 | ①查找效率:与B-树的阶数m进而高度h直接有关;②插入:3阶B树关键字个数N,h<=log2((N+1)/2)+1;完成一次插入,最多需要读写磁盘次数=2h | 磁盘读写代价更低、查询效率更加稳定、更有利于对数据库的扫描 |














 1314
1314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









