







9.3 插入排序
- 插入排序(insert sor)的基本思想是:每一次设法把一个数据元素插入已经排序的部分序列的合适位置,使得插入后的序列仍然是有序的。
- 开始时建立一个初始的有序序列,它只包含一个数据元素。然后,从这个的初始序列开始不断进行插入数据元素,直到最后一个数据元素插入有序序列后,整个排序工作就完成了。
9.3.1 直接插入排序
直接插入排序(straight insert sor)的算法基本思想是:开始时把第一个数据元素作为初始的有序序列,然后依次从第二个数据元素开始把数据元素按关键字大小插入到己排序的部分数据表的适当位置。当插入第i(1<=i<=n) 个数据元素时,前面的i-1个数据元素已经排好序,这时,用第i个数据元素的关键字与前面的i-1个数据元素的关键字顺序进行比较,找到插入位置后就将第i个数据元素插入,原来位置及其以后的数据元素都向后顺移一个位置。如此进行n-1次插入,就完成了排序。
1. 顺序表上的直接插入排序
- 在顺序表上的直接插入排序时,当插入第i(0<i<n)个数据元素时,前面的elem[0],elem[1],…,elem[i-1]已经排好序,这时,用elem[ij依次和 elem[i-1], elem[i-2], …进行比较,如果这些数据元素都大于elem[i-1],则它们都向后顺移一个位置,直到找到插入位置后就将elem[i]插入。如此进行n-1次插入,就完成了所有元素的排序。
- 代码实现
template<class ElemType> void StraightInsertSort(ElemType elem[],int n)
{
int i,j;
for(i=1;i<n;i++)//第i趟直接插入排序
{
ElemType e=elem[i];//暂存elem[i]
for(j=i-1;j>=0 && e<elem[j];j--)
elem[j+1]=elem[j];//将比e大的都往后移
elem[j+1]=e;//j+1为插入位置
}
}
- 在顺序表上直接插入排序算法的时间复杂度分析,可以分最好和最坏两种情况分别讨论。
(1)在最好情况下,即在排序前数据元素已经按关键字大小从小到大排好序了,每趟只需与前面的有序数据元素序列的最后一个数据元素的关键字比较一次,移动两次数据元素。所以,总的关键字比较次数为n-1,数据移动次数为 2(n-1),因此最好情况下的时间复杂度为 O(n)。
(2)在最坏情况下,即第i趟插入时,数据元素 elem[i]必须与前面i个数据元素都做关键字的比较,并且每做一次比较就要做一次数据元素移动,则总的关键字比较次数和数据移动次数分别为: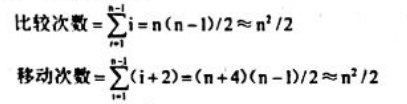
因此最坏情况下的时间复杂度为O(n2)。若数据表中出现各种可能排列的概串相同,则可取上述最好情况和最坏情况的平均值,可得在平均情况下的关键字比较次数和数据元素移动次数约为n2/4。因此直接插入排序的平均时间复杂度为O(n2)。 - 根据上述分析可以得知:初始数据表越接近有序,直接插入排序的效率越高。这个结论是后面讨论希尔排序的基础。显然,在顺序表上的直接插入排序是一种稳定的排序方法。
2.链表上的直接插入排序
- 在链表上进行直接插入排序 (link insert sort) :数据表采用链表存储结构,在每个数据元素的结点中增加一个链城next用于指向后继数据元素。
- 算法思想同顺序表类似,不同之处在于顺序表直接将表的内容进行交换修改,而链表只修改指针域,不改变其值。

- 算法实现
//静态链表节点
template<class ElemType> struct Node
{
ElemType data;
int next;
};
template<class ElemType> void LinkInsertSort(Node<ElemType> elem[])
{
int p,q,pre,r;
p=elem[0].next;
elem[0].next=-1;
while(p!=-1)
{
q=elem[0].next;
pre=0;
while(q!=-1 && elem[q].data <= elem[p].data)
{
pre=q;
q=elem[q].next;
}
r=elem[p].next;
elem[p],next=q;
elem[pre].next=p;
p=r;
}
}
- 使用链表插入排序,无需移动数据元素的位置,代之以指针的修改共2n。在插入第i个数据元素结点时,关键字比较次数最多为i次,最少为1次。因此,总的关键字比较次数最少为n,最多为:
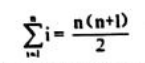
- 为了实现链表插入,在每个数据元素结点中增加了一个指针域next,并使用了elem[0]作为链表的表头结点。所以,总共用了n个附加指针域和一个附加数据元素结点。所以其空间复杂度为O(n)。
- 算法从第一个数据元素结点开始直到最后一个元素结束,每次总是从有序链表的表头开始根据指针寻找插入位置。当数据表中存在两个数据元素的关键字相等时,总是把后一个数据元素结点插在前一个数据元素结点的后面。这样就确保了关键字相同的数据元素在排序前后的相对位置不变。所以,链表插入排序方法是稳定的。
小结
| 直接插入排序 | 顺序表 | 链表 |
|---|---|---|
| 最好情况 | 初始排列已经从小到大有序 | 初始排列已经从小到大有序 |
| 比较次数 | 每趟比较1次,总共n-1 | 每趟比较1次,总共n次 |
| 移动次数 | 每趟移动2次元素,,总共2(n-1) | 无需移动,修改指针2n次 |
| 最坏情况 | 初始排列从大到小(逆序) | 初始排列从大到小(逆序) |
| 比较次数 | 第i趟进行n-i次比较~n2/2 | 第i趟进行i次比较,最多n(n+1)/2 |
| 移动次数 | n-1趟;每次比较需要移动~n2/2 | 无需移动,修改指针2n次 |
| 时间复杂度T(n) | 最好情况O(n);最坏情况=平均=O(n2) | |
| 空间复杂度S(n) | O(1) | O(n) |
| 稳定性 | 稳定 | 稳定 |
9.3.2 折半插入排序
- 折半插入排序(binary insert sort) 的算法基本思想是:设在数据表中有n个数据元素elem[0],elem[1],…,elem[i-1],其中,elem[0],elem[1],…,elem[i-1]是已经排好序的部分数据元素序列,在插入 elem[i]时,先利用折半查找方法寻找elem[i]的插入位置,然后把插入位置后面的元素依次后移一个元素空间,最后把elem[ij插入相应位置。
- 折半插入排序的算法只能在顺序表存储结构下实现。就平均性能而言,因为折半查找优于顺序查找,所以折半插入排序也优于直接插入排序。
- 它所需要的关键字比较次数与数据表的初始排列有关,在插入第i个数据元素时,最多需要经过⌊log2i⌋+1次关键字比较,才能确定它应插入的位置。因此,将n个数据元素(为推导方便,设为n=2k)。用折半插入排序所进行的关键字比较次数最多为:n*log2n。
- 当n较大时,总的关键字比较次数比直接插入排序的最坏情况要少得多,但比其最好情况要多。在数据元素的初始排列已经技关键字排好序或接近有序时,直接插入排序比折半插入排执行的关键字比较次数要少。折半插入排的数据元素移动次数与直接插入排序相同,也依赖于数据元素的初始排列,其不同点仅是变分散移动为集中移动。折半插入排序是一个稳定的排序方法。
- 代码实现
在基础的折半查找之上还有改进方法,如斐波那契插入、插值(拉格朗日)插入、二路插入等。
//折半插入排序
template<class ElemType> bool SeqList<ElemType>::HalfSort(const ElemType x)
{
cout<<"insert "<<x<<"---"<<endl;
if(length==maxLength)
{
cout<<"已满,无法插入"<<x<<endl;
return false;
}
else if(length==0)
{
elems[length]=x;
length++;
return true;
}
int low,high,mid;
mid=-1;
low=0;
high=length-1;
while(low<=high)
{
mid=(low+high)/2;
if(elems[mid]==x)
{
break;
}
else if(elems[mid]<x)
low=mid+1;
else if(elems[mid]>x)
high=mid-1;
}
if(x < elems[mid])
{
for(int i=length-1; i>=mid; i--)
elems[i+1]=elems[i];
elems[mid]=x;
length++;
return true;
}
else if(x > elems[mid])
{
for(int i=length-1; i>mid; i--)
elems[i+1]=elems[i];
elems[mid+1]=x;
length++;
return true;
}
}
//斐波那契插入
template<class ElemType> bool SeqList<ElemType>::FSort(const ElemType x)
{
cout<<"insert "<<x<<"---"<<endl;
if(length==maxLength)
{
cout<<"已满,无法插入"<<x<<endl;
return false;
}
else if(length==0)
{
elems[length]=x;
length++;
return true;
}
vector<int> F;
int a,b;
a=1;
b=1;
F.push_back(1);
F.push_back(1);
while(length-1>a-1)
{
a=F[b]+F[b-1];
F.push_back(a);
b++;
}
int low,high,mid;
low=0;
high=length-1;
for(int i=length; i<=F[b]-1; i++)
{
elems[i]=elems[high];
}
while(low<=high)
{
mid=low+F[b-1]-1;
if(elems[mid]==x)
{
if(mid<=length-1)
{
break;
}
}
else if(elems[mid]<x)
{
low=mid+1;
b=b-2;
}
else if(elems[mid]>x)
{
high=mid-1;
b=b-1;
}
}
if(x < elems[mid])
{
for(int i=length-1; i>=mid; i--)
elems[i+1]=elems[i];
elems[mid]=x;
length++;
return true;
}
else if(x > elems[mid])
{
for(int i=length-1; i>mid; i--)
elems[i+1]=elems[i];
elems[mid+1]=x;
length++;
return true;
}
}
//二路插入
template<class ElemType>
void SeqList<ElemType>::TwoInsertSort()
{
int n=length;
ElemType d[n];
int first,final,high,low,mid,i,j,k;
d[0]=elems[0];
first=0;
final=n-1;
for(i=1; i<n; i++)
{
if(elems[i]>d[0])
{
low=0;
high=final;
while(low<=high)
{
mid=(low+high)/2;
if(elems[i]<d[mid]) high=mid-1;
else low=mid+1;
}
for(j=final; j>=low; j--)
d[j+1]=d[j];
d[low]=elems[i];
final++;
}
else
{
if(first==n-1)
d[n-1]=elems[i];
else
{
low=first;
high=n-1;
while(low<=high)
{
mid=(low+high)/2;
if(elems[i]<d[mid]) high=mid-1;
else low =mid+1;
}
for(int j=first; j<=high; j++)
d[j-1]=d[j];
d[high]=elems[i];
first--;
}
}
}
for(i=0,j=first; i<n; i++,j=(first+i)%n)
elems[i]=d[j];
}
9.3.3 希尔排序
- 希尔排序(Shell sort)又称为缩小增量排序。
- 它的算法基本思想是:设数据表中有n个数据元素,首先取一个整数d<n作为间隔,将全部数据元素分为d个子表,所有相距为d的数据元素放在同一个子表中,在每一个子表中分别进行直接插入排序,然后缩小间隔d(如取 d=⌈d/2⌉),重复上述的子表划分和排序工作。如此循环,直到最后d=1,将所有数据元素放在同一个序列中进行直接插入排序。
- 由于开始时d的取值较大,每个子表中的数据元素较少(每个子表元素数为n/d)。因此,在子表中的直接插入排序速度较快;到排序的后期,d取值逐渐变小,子表中数据元素个数逐渐变多,但由于前面工作的基础,大多数数据元素已基本有序,所以直接插入排序速度仍然比较快。
- 举例:六个数据元素的数据表进行希尔排序的过程。间隔d={3,2,1}。
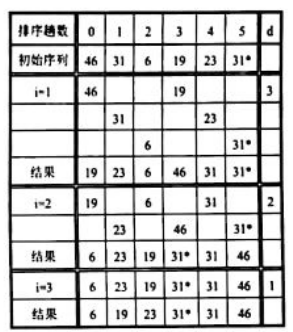
- 代码实现
template<class ElemType> void ShellSort(ElemType elem[],int n)
{
int i,j,d=n/2;
ElemType e;
while(d>0)
{
for(i=d;i<n;i++)//步长为d时的插入排序
{
e=elem[i];//取下标为i的元素
j=i-d;
while(j>=0 && e<elem[j])//将子序列中比e大的元素都后移
{
elem[j+d]=elem[j];
j-=d;
}
elem[j+d]=e;//将下标为i的元素插入子序列的适当位置
}
d=d/2;//缩短步长
}
}
- d 的取值是一个递减的序列,并最终取1,使得最后一趟排序是对已基本有序的整个数据表的数据元素进行直接插入排序。
- 在希尔排序排序过程中,逆序的数据元素不是一步一步地移动,而是跳跃式地(按间隔 d)向正序方向移动。这就意味着数据元素的移动次数和关键字的比较次数将会减少,所以希尔排序的效率应该是比较高的。对希尔排序的时间复杂度分析是很困难。虽然,在特定情况下可以准确地估算出关键字的比较次数和数据元素移动次数,但是目前还没有人能够弄清:关键字比较次数和数据元素移动次数与间隔选择之向的依赖关系,并给出完整的数学分析。在 Knuth 所茗的《计算机程序设计技巧》第三卷中,利用大量的实验统计资料得出,当n很大时,关键字平均比较次数相数据元素平均移动次数大约在n1.25到1.6n1.25范围内,这是在利用直接插入排序作为子表排序方法的情况下得到的。
- 在希尔排序中,由于数据元素是跳跃式移动的,所以希尔排序是不稳定的排序方法。
总结
| 排序方法 | 存储结构 | 特点 | 适用 | 稳定性 |
|---|---|---|---|---|
| 直接插入排序 | 顺序/链表 | 折半插入排序所进行的关键字比较次数最多为:n*log2n | 适用 | 稳定 |
| 折半插入排序 | 只能顺序存储 | 时间复杂度O(n2);空间复杂度O(n2) | n比较大并且数据无序程度大 | 稳定 |
| 希尔排序 | 存储结构 | 数据元素是跳跃式移动 | 适用 | 不稳定 |
折半插入排序优于直接插入排序















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









