









FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause.
查看yarn的日志:
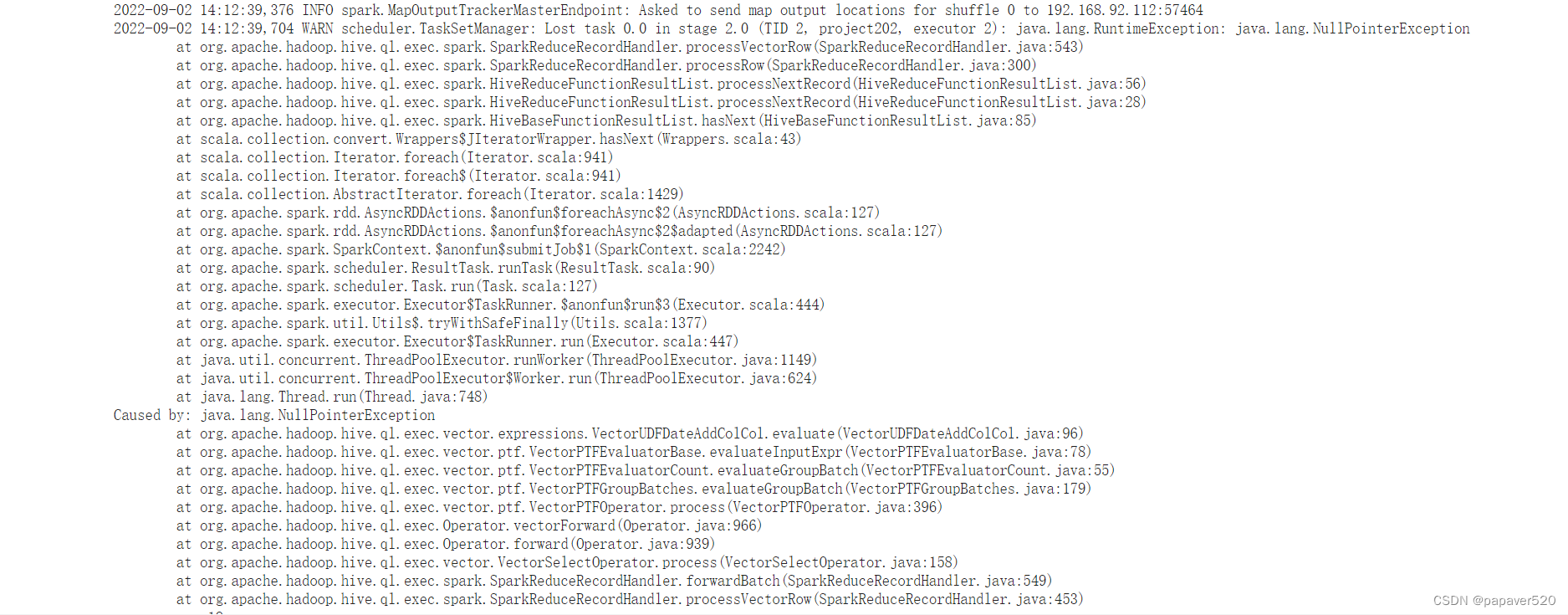
解决:
set hive.vectorized.execution.enabled = false;
此命令:你的sql在哪个客户端执行,你的命令就在 哪执行
比如:你的SQL在datagrip中执行,那么这个命令也在这执行

如果在hive客户端执行,你的命令也得在hive客户端执行

在hive端执行命令,记得切换数据库















 1355
1355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









