







是什么
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。
核心目标,是“数据流上的有状态计算”。

有界流和无界流
- 无界数据流:
- 有定义流的开始,但没有定义流的结束;
- 无休止的产生数据;
无界流的数据必须持续处理,即数据被摄取后需要立刻处理;- 不能等到所有数据都到达再处理,因为输入是无限的。
- 有界数据流
- 有定义流的开始,也有定义流的结束;
- 有界流可以在摄取所有数据后再进行计算;
- 有界流所有数据可以被排序,所以并不需要有序摄取;
- 有界流处理通常被称为批处理。
有状态流处理
把流处理需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态。这就是所谓的“有状态的流处理”
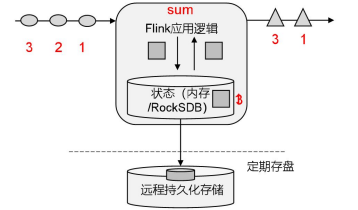

特点

应用场景

Flink 分层 API
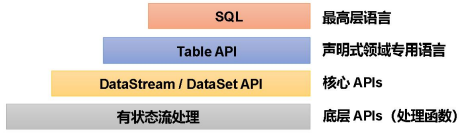
- 越顶层越抽象,表达含义越简明,使用越方便
- 越底层越具体,表达能力越丰富,使用越灵活


















 3382
3382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











