







文章目录
本笔记个人整理自黑马2022、青空霞光,仅供学习使用
mybatis 创建基础查询
一、mybatis 入门
1.创建user表,添加数据
create database mybatis;
use mybatis;
drop table if exists tb_user;
create table tb_user(
id int primary key auto_increment,
username varchar(20),
password varchar(20),
gender char(1),
addr varchar(30)
);
INSERT INTO tb_user VALUES (1, 'zhangsan', '123', '男', '北京');
INSERT INTO tb_user VALUES (2, '李四', '234', '女', '天津');
INSERT INTO tb_user VALUES (3, '王五', '11', '男', '西安');
2.pom.xml创建模块,导入坐标
<dependencies>
<!-- mybatis 依赖-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.5</version>
</dependency>
<!-- mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
<!-- juit 单元测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- 添加slf4j日志api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.20</version>
</dependency>
<!-- 添加logback-classic依赖 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
<!-- 添加logback-core依赖 -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>
3.src/main/resources创建logback.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--
CONSOLE :表示当前的日志信息是可以输出到控制台的。
-->
<appender name="Console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%level] %blue(%d{HH:mm:ss.SSS}) %cyan([%thread]) %boldGreen(%logger{15}) - %msg %n</pattern>
</encoder>
</appender>
<logger name="com.itheima" level="DEBUG" additivity="false">
<appender-ref ref="Console"/>
</logger>
<!--
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF
, 默认debug
<root>可以包含零个或多个<appender-ref>元素,标识这个输出位置将会被本日志级别控制。
-->
<root level="DEBUG">
<appender-ref ref="Console"/>
</root>
</configuration>
4.src/main/resources编写核心配置文件

<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--
environments:配置数据库连接环境信息。可以配置多个environment,通过default属性切换不同的environment
-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--数据库连接信息-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql:///mybatis?useSSL=false"/>
<property name="username" value="root"/>
<property name="password" value="1234"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--加载sql映射文件-->
<mapper resource="com/itheima/mapper/UserMapper.xml"/>
</mappers>
</configuration>
5.编写SQL映射文件

<select id="selectAll" resultType="com.itheima.pojo.User">
select *
from tb_user;
</select>
6.mybatis-config.xml加载映射文件
<!--加载sql映射文件-->
<mapper resource="UserMapper.xml"/>
7.创建POJO实体类 java/com.itheima.pojo/User.java
package com.itheima.pojo;
public class User {
private Integer id;
private String username;
private String password;
private String gender;
private String addr;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
", gender='" + gender + '\'' +
", addr='" + addr + '\'' +
'}';
}
}
8.创建测试类
package com.itheima;
import com.itheima.pojo.User;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
/**
* Mybatis 快速入门代码
*/
public class MyBatisDemo {
public static void main(String[] args) throws IOException {
//1. 加载mybatis的核心配置文件,获取 SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象,用它来执行sql
SqlSession sqlSession = sqlSessionFactory.openSession();
//3. 执行sql
List<User> users = sqlSession.selectList("test.selectAll");
System.out.println(users);
//4. 释放资源
sqlSession.close();
}
}
二、Mapper 代理开发
使用Mapper代理方式完成入门案例
1.定义与SQL映射文件同名的Mapper接口,并且将Mapper接口与SQL映射文件放置在同一目录下
2.设置SQL映射文件的namespace属性为Mapper接口全限定名
3.在Mapper接口中定义方法,方法名就是SQL映射文件中sql语句的id,并保持参数类型和返回值类型一致
4.编码
1.通过SqlSession 的 getMapper 方法获取 Mapper 接口的代理对象
2.调用对应方法完成sql的执行
如果Mapper接口名称和SQL映射文件名称相同,并在同一目录下,则可以使用包扫描的方式简化SQL映射文件的加载
1.1 创建mapper.UserMapper.java接口
package com.itheima.mapper;
public interface UserMapper {
}
1.2在resources目录下创建目录com.itheima.mapper
注意:不要用.创建目录,使用/

将UserMapper.xml 移动到该文件夹下
2.设置SQL映射文件的namespace属性为Mapper接口全限定名
User.Mapper.xml
<mapper namespace="com.itheima.mapper.UserMapper">
3.在Mapper接口中定义方法,方法名就是SQL映射文件中sql语句的id,并保持参数类型和返回值类型一致
UserMapper.java接口中定义查询方法
List<User> selectAll();
3.2 修改mybatis-config.xml的sql映射文件路径
<mappers>
<!--加载sql映射文件-->
<mapper resource="com/itheima/mapper/UserMapper.xml"/>
</mappers>
4.src/com/itheima创建MybatisDemo2
核心
//3.1 获取UserMapper接口的代理对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<User> users = userMapper.selectAll();
完整代码
/**
* Mybatis 代理开发
*/
public class MyBatisDemo2 {
public static void main(String[] args) throws IOException {
//1. 加载mybatis的核心配置文件,获取 SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象,用它来执行sql
SqlSession sqlSession = sqlSessionFactory.openSession();
//3. 执行sql
//List<User> users = sqlSession.selectList("test.selectAll");
//3.1 获取UserMapper接口的代理对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<User> users = userMapper.selectAll();
System.out.println(users);
//4. 释放资源
sqlSession.close();
}
}
5.Mapper代理更改为包扫描方式
加载sql映射文件,每个文件都要写 不方便
更改为代理方式
mapper接口与xml都放到正确的位置时,可以使用包扫描自动加载
<mappers>
<!--加载sql映射文件-->
<!-- <mapper resource="com/itheima/mapper/UserMapper.xml"/>-->
<!--Mapper代理方式-->
<package name="com.itheima.mapper"/>
</mappers>
三.核心配置文件
1 environments
environments:配置数据库连接环境信息。可以配置多个environment,通过default属性切换不同的environment
配置不同的数据源,将来可以通过<environment id="development"> 来切换
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--数据库连接信息-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql:///mybatis?useSSL=false"/>
<property name="username" value="root"/>
<property name="password" value="1234"/>
</dataSource>
</environment>
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--数据库连接信息-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql:///mybatis?useSSL=false"/>
<property name="username" value="root"/>
<property name="password" value="1234"/>
</dataSource>
</environment>
</environments>
2 导入db 配置文件
创建db.properties文件
mysql.driver=com.mysql.jdbc.Driver
mysql.url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false
mysql.username=root
mysql.password=1234
<properties resource="db.properties"/>
mybatis-config.xml 引入数据
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${mysql.driver}"/>
<property name="url" value="${mysql.url}"/>
<property name="username" value="${mysql.username}"/>
<property name="password" value="${mysql.password}"/>
</dataSource>
</environment>
</environments>
3 别名
mybatis-config.xml
<!-- 别名 -->
<typeAliases>
<package name="com.itheima.pojo"/>
<!-- 该包下的文件不区分大小写-->
</typeAliases>
起完别名之后 Mapper 映射文件下的resultType可直接写类名,且不区分大小写
4.创建utils工具类
src/main/com/itheima/utils/MyBatisUtil.java
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.InputStream;
/**
* 工具类
*/
public class MyBatisUtils {
private static SqlSessionFactory sqlSessionFactory = null;
// 初始化SqlSessionFactory对象
static {
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (Exception e) {
e.printStackTrace();
}
}
// 获取SqlSession对象的静态方法
public static SqlSessionFactory getSqlSessionFactory() {
return sqlSessionFactory;
}
}
注意:
SqlSession sqlSession = sqlSessionFactory.openSession()
不能写到工具类里面,不能让所有功能都共用一个连接,这样对管理事务不好
四、使用:Lombok
Lombok下载
用来简化get/set方法,无需担心字段名更改而更改对应的get/set方法
配置Lombok
1.下载lombok.jar
拖入到项目文件夹下–> 添加为库
或者在pom.xml添加依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.22</version>
</dependency>
2.重启IDEA
使用详解
我们通过添加@Getter和@Setter来为当前类的所有字段生成get/set方法,注意静态字段不会生成,final字段无法生成set方法。
我们还可以使用@Accessors来控制生成Getter和Setter的样式。
我们通过添加@ToString来为当前类生成预设的toString方法。
我们可以通过添加@EqualsAndHashCode来快速生成比较和哈希值方法。
我们可以通过添加@AllArgsConstructor和@NoArgsConstructor来快速生成全参构造和无参构造。
我们可以添加@RequiredArgsConstructor来快速生成参数只包含final或被标记为@NonNull的成员字段。
使用@Data能代表@Setter、@Getter、@RequiredArgsConstructor、@ToString、@EqualsAndHashCode全部注解。
一旦使用@Data就不建议此类有继承关系,因为equal方法可能不符合预期结果(尤其是仅比较子类属性)。
使用@Value与@Data类似,但是并不会生成setter并且成员属性都是final的。
使用@SneakyThrows来自动生成try-catch代码块。
使用@Cleanup作用与局部变量,在最后自动调用其close()方法(可以自由更换)
使用@Builder来快速生成建造者模式。
通过使用@Builder.Default来指定默认值。
通过使用@Builder.ObtainVia来指定默认值的获取方式。
部分常用参数解析
链式调用
@Accessors(chain = true)
public class Student {
private Integer id;
private String name;
private Integer age;
}
例:
Student student = new Student();
student.setId(1).setAge(18).setName("zs");
toString不包含字段名
@ToString(includeFieldNames = false)
省略打印字段
@ToString(exclude = {"id","name"}) // of是只包含

Include 作用在字段上 rank 排序,值越大越前 name给字段重命名输出

五、重构基础查询
(引入lombok,utils,使用db配置文件)
- 创建maven 项目,引入依赖
略… - 建立项目结构

- 在
main/resources创建以下配置文件

mybatis-config.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 导入db配置文件-->
<properties resource="db.properties"/>
<!-- 别名 -->
<typeAliases>
<package name="com.itheima.pojo"/>
</typeAliases>
<!--
environments:配置数据库连接环境信息。可以配置多个environment,通过default属性切换不同的environment
-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${mysql.driver}"/>
<property name="url" value="${mysql.url}"/>
<property name="username" value="${mysql.username}"/>
<property name="password" value="${mysql.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!--Mapper代理方式-->
<package name="com.itheima.mapper"/>
</mappers>
</configuration>
- pojo 创建实体类User
@Data
public class User {
private int uid;
private String uname;
private int uage;
}
5.mapper 创建UserMapper接口
public interface UserMapper {
List<User> selectAll();
}
6.main/resources创建目录 com/itheima/mapper ,创建UserMapper.xml映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.mapper.UserMapper">
<select id="selectAll" resultType="user">
select * from users;
</select>
</mapper>
7.utils 创建工具类 MyBatisUtils 8.在test文件夹下创建com.itheima.test.UserMapperTest.java`
public class UserMapperTest {
SqlSessionFactory sqlSessionFactory = MyBatisUtils.getSqlSessionFactory();
@Test
public void testSelectAll() {
try(SqlSession sqlSession = sqlSessionFactory.openSession()){
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.selectAll();
System.out.println(users);
}
}
}
六:resultMap映射器
主要作用:数据库字段名与实体类名不一致,需要编写映射规则
<!-- resultMap写法 -->
<resultMap id="StudentMap" type="student">
<result column="sid" property="id"/>
<result column="sname" property="name"/>
<result column="sage" property="age"/>
</resultMap>
<select id="selectAll" resultType="student" resultMap="StudentMap">
select *
from t_student;
</select>
- 注解代替resultMap写法 StudentMapper.java
@Select("select * from t_student")
@Results({
@Result(id=true,column="sid",property="id"),
@Result(column="sname",property="name"),
@Result(column="sage",property="age")
})
- 别名写法
<!-- 别名写法-->
<select id="selectAll" resultType="student">
select sid as id,sname as name,sage as age
from t_student;
</select>
- 实体类使用@Alias
@Data
@Alias("tbUser")
public class User {
private int uid;
private String uname;
private int uage;
}
<select id="selectAll" resultType="tbUser">
select * from users;
</select>
七:条件查询
1. 根据id查询
User selectById(int id);
<resultMap id="userMap" type="user">
<result column="uid" property="id"/>
<result column="uname" property="name"/>
<result column="uage" property="age"/>
</resultMap>
<select id="selectById" resultMap="userMap">
select * from users where uid = #{id}
</select>
我们通过使用#{xxx}或是${xxx}来填入我们给定的属性,实际上Mybatis本质也是通过PreparedStatement首先进行一次预编译,有效地防止SQL注入问题,但是如果使用${xxx}就不再是通过预编译,而是直接传值,因此我们一般都使用#{xxx}来进行操作
如果数据库中存在一个带下划线的字段,我们可以通过设置让其映射为以驼峰命名的字段,比如my_test映射为myTest
在mybatis-config.xml
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
2. 增
<insert id="add">
insert into users(uname, uage) values (#{name},#{age})
</insert>
3. 删
<delete id="deleteById">
delete from users where uid = #{id}
</delete>
4. 改
<update id="update">
update users
set uname = #{name},
uage = #{age}
where uid = #{id}
</update>
八:复杂查询
摘自 Ketuer
一个老师可以教授多个学生,那么能否一次性将老师的学生全部映射给此老师的对象呢,比如:
@Data
public class Teacher {
int tid;
String name;
List<Student> studentList;
}
映射为Teacher对象时,同时将其教授的所有学生一并映射为List列表,显然这是一种一对多的查询,那么这时就需要进行复杂查询了。而我们之前编写的都非常简单,直接就能完成映射,因此我们现在需要使用resultMap来自定义映射规则:
<select id="getTeacherByTid" resultMap="asTeacher">
select *, teacher.name as tname from student inner join teach on student.sid = teach.sid
inner join teacher on teach.tid = teacher.tid where teach.tid = #{tid}
</select>
<resultMap id="asTeacher" type="Teacher">
<id column="tid" property="tid"/>
<result column="tname" property="name"/>
<collection property="studentList" ofType="Student">
<id property="sid" column="sid"/>
<result column="name" property="name"/>
<result column="sex" property="sex"/>
</collection>
</resultMap>
可以看到,我们的查询结果是一个多表联查的结果,而联查的数据就是我们需要映射的数据(比如这里是一个老师有N个学生,联查的结果也是这一个老师对应N个学生的N条记录),其中<id column="tid" property="tid"/>标签用于在多条记录中辨别是否为同一个对象的数据,比如上面的查询语句得到的结果中,tid这一行始终为1,因此所有的记录都应该是tid=1的教师的数据,而不应该变为多个教师的数据,如果不加id进行约束,那么会被识别成多个教师的数据!
通过使用collection来表示将得到的所有结果合并为一个集合,比如上面的数据中每个学生都有单独的一条记录,因此tid相同的全部学生的记录就可以最后合并为一个List,得到最终的映射结果,当然,为了区分,最好也设置一个id,只不过这个例子中可以当做普通的result使用。
了解了一对多,那么多对一又该如何查询呢,比如每个学生都有一个对应的老师,现在Student新增了一个Teacher对象,那么现在又该如何去处理呢?
@Data
@Accessors(chain = true)
public class Student {
private int sid;
private String name;
private String sex;
private Teacher teacher;
}
@Data
public class Teacher {
int tid;
String name;
}
现在我们希望的是,每次查询到一个Student对象时都带上它的老师,同样的,我们也可以使用resultMap来实现(先修改一下老师的类定义,不然会很麻烦):
<resultMap id="test2" type="Student">
<id column="sid" property="sid"/>
<result column="name" property="name"/>
<result column="sex" property="sex"/>
<association property="teacher" javaType="Teacher">
<id column="tid" property="tid"/>
<result column="tname" property="name"/>
</association>
</resultMap>
<select id="selectStudent" resultMap="test2">
select *, teacher.name as tname from student left join teach on student.sid = teach.sid
left join teacher on teach.tid = teacher.tid
</select>
通过使用association进行关联,形成多对一的关系,实际上和一对多是同理的,都是对查询结果的一种处理方式罢了。
九:缓存机制
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。
n
其实缓存机制我们在之前学习IO流的时候已经提及过了,我们可以提前将一部分内容放入缓存,下次需要获取数据时,我们就可以直接从缓存中读取,这样的话相当于直接从内存中获取而不是再去向数据库索要数据,效率会更高。
因此Mybatis内置了一个缓存机制,我们查询时,如果缓存中存在数据,那么我们就可以直接从缓存中获取,而不是再去向数据库进行请求。

Mybatis存在一级缓存和二级缓存,我们首先来看一下一级缓存,默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存(一级缓存无法关闭,只能调整),我们来看看下面这段代码:
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student1 = testMapper.getStudentBySid(1);
Student student2 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
我们发现,两次得到的是同一个Student对象,也就是说我们第二次查询并没有重新去构造对象,而是直接得到之前创建好的对象。如果还不是很明显,我们可以修改一下实体类:
@Data
@Accessors(chain = true)
public class Student {
public Student(){
System.out.println("我被构造了");
}
private int sid;
private String name;
private String sex;
}
我们通过前面的学习得知Mybatis在映射为对象时,在只有一个构造方法的情况下,无论你构造方法写成什么样子,都会去调用一次构造方法,如果存在多个构造方法,那么就会去找匹配的构造方法。我们可以通过查看构造方法来验证对象被创建了几次。
结果显而易见,只创建了一次,也就是说当第二次进行同样的查询时,会直接使用第一次的结果,因为第一次的结果已经被缓存了。
那么如果我修改了数据库中的内容,缓存还会生效吗:
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student1 = testMapper.getStudentBySid(1);
testMapper.addStudent(new Student().setName("小李").setSex("男"));
Student student2 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
我们发现,当我们进行了插入操作后,缓存就没有生效了,我们再次进行查询得到的是一个新创建的对象。
也就是说,一级缓存,在进行DML操作后,会使得缓存失效,也就是说Mybatis知道我们对数据库里面的数据进行了修改,所以之前缓存的内容可能就不是当前数据库里面最新的内容了。还有一种情况就是,当前会话结束后,也会清理全部的缓存,因为已经不会再用到了。但是一定注意,一级缓存只针对于单个会话,多个会话之间不相通。
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student2;
try(SqlSession sqlSession2 = MybatisUtil.getSession(true)){
TestMapper testMapper2 = sqlSession2.getMapper(TestMapper.class);
student2 = testMapper2.getStudentBySid(1);
}
Student student1 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
**注意:**一个会话DML操作只会重置当前会话的缓存,不会重置其他会话的缓存,也就是说,其他会话缓存是不会更新的!
一级缓存给我们提供了很高速的访问效率,但是它的作用范围实在是有限,如果一个会话结束,那么之前的缓存就全部失效了,但是我们希望缓存能够扩展到所有会话都能使用,因此我们可以通过二级缓存来实现,二级缓存默认是关闭状态,要开启二级缓存,我们需要在映射器XML文件中添加:
<cache/>
可见二级缓存是Mapper级别的,也就是说,当一个会话失效时,它的缓存依然会存在于二级缓存中,因此如果我们再次创建一个新的会话会直接使用之前的缓存,我们首先根据官方文档进行一些配置:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
我们来编写一个代码:
public static void main(String[] args) {
Student student;
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
student = testMapper.getStudentBySid(1);
}
try (SqlSession sqlSession2 = MybatisUtil.getSession(true)){
TestMapper testMapper2 = sqlSession2.getMapper(TestMapper.class);
Student student2 = testMapper2.getStudentBySid(1);
System.out.println(student2 == student);
}
}
我们可以看到,上面的代码中首先是第一个会话在进行读操作,完成后会结束会话,而第二个操作重新创建了一个新的会话,再次执行了同样的查询,我们发现得到的依然是缓存的结果。
那么如果我不希望某个方法开启缓存呢?我们可以添加useCache属性来关闭缓存:
<select id="getStudentBySid" resultType="Student" useCache="false">
select * from student where sid = #{sid}
</select>
我们也可以使用flushCache="false"在每次执行后都清空缓存,通过这这个我们还可以控制DML操作完成之后不清空缓存。
<select id="getStudentBySid" resultType="Student" flushCache="true">
select * from student where sid = #{sid}
</select>
添加了二级缓存之后,会先从二级缓存中查找数据,当二级缓存中没有时,才会从一级缓存中获取,当一级缓存中都还没有数据时,才会请求数据库,因此我们再来执行上面的代码:
public static void main(String[] args) {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
Student student2;
try(SqlSession sqlSession2 = MybatisUtil.getSession(true)){
TestMapper testMapper2 = sqlSession2.getMapper(TestMapper.class);
student2 = testMapper2.getStudentBySid(1);
}
Student student1 = testMapper.getStudentBySid(1);
System.out.println(student1 == student2);
}
}
得到的结果就会是同一个对象了,因为现在是优先从二级缓存中获取。
读取顺序:二级缓存 => 一级缓存 => 数据库

虽然缓存机制给我们提供了很大的性能提升,但是缓存存在一个问题,我们之前在计算机组成原理中可能学习过缓存一致性问题,也就是说当多个CPU在操作自己的缓存时,可能会出现各自的缓存内容不同步的问题,而Mybatis也会这样,我们来看看这个例子:
public static void main(String[] args) throws InterruptedException {
try (SqlSession sqlSession = MybatisUtil.getSession(true)){
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
while (true){
Thread.sleep(3000);
System.out.println(testMapper.getStudentBySid(1));
}
}
}
我们现在循环地每三秒读取一次,而在这个过程中,我们使用IDEA手动修改数据库中的数据,将1号同学的学号改成100,那么理想情况下,下一次读取将无法获取到小明,因为小明的学号已经发生变化了。
但是结果却是依然能够读取,并且sid并没有发生改变,这也证明了Mybatis的缓存在生效,因为我们是从外部进行修改,Mybatis不知道我们修改了数据,所以依然在使用缓存中的数据,但是这样很明显是不正确的,因此,如果存在多台服务器或者是多个程序都在使用Mybatis操作同一个数据库,并且都开启了缓存,需要解决这个问题,要么就得关闭Mybatis的缓存来保证一致性:
<settings>
<setting name="cacheEnabled" value="false"/>
</settings>
<select id="getStudentBySid" resultType="Student" useCache="false" flushCache="true">
select * from student where sid = #{sid}
</select>
要么就需要实现缓存共用,也就是让所有的Mybatis都使用同一个缓存进行数据存取,在后面,我们会继续学习Redis、Ehcache、Memcache等缓存框架,通过使用这些工具,就能够很好地解决缓存一致性问题。
黑马Mybatis
1,配置文件实现CRUD
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fZVENlcy-1648965526161)(F:\JavaEE\note\JavaEE\Mybatis\JavaWeb_Mybatis.assets\image-20210729111159534.png)]
如上图所示产品原型,里面包含了品牌数据的 查询 、按条件查询、添加、删除、批量删除、修改 等功能,而这些功能其实就是对数据库表中的数据进行CRUD操作。接下来我们就使用Mybatis完成品牌数据的增删改查操作。以下是我们要完成功能列表:
- 查询
- 查询所有数据
- 查询详情
- 条件查询
- 添加
- 修改
- 修改全部字段
- 修改动态字段
- 删除
- 删除一个
- 批量删除
我们先将必要的环境准备一下。
1.1 环境准备
-
数据库表(tb_brand)及数据准备
-- 删除tb_brand表 drop table if exists tb_brand; -- 创建tb_brand表 create table tb_brand ( -- id 主键 id int primary key auto_increment, -- 品牌名称 brand_name varchar(20), -- 企业名称 company_name varchar(20), -- 排序字段 ordered int, -- 描述信息 description varchar(100), -- 状态:0:禁用 1:启用 status int ); -- 添加数据 insert into tb_brand (brand_name, company_name, ordered, description, status) values ('三只松鼠', '三只松鼠股份有限公司', 5, '好吃不上火', 0), ('华为', '华为技术有限公司', 100, '华为致力于把数字世界带入每个人、每个家庭、每个组织,构建万物互联的智能世界', 1), ('小米', '小米科技有限公司', 50, 'are you ok', 1); -
实体类 Brand
在
com.itheima.pojo包下创建 Brand 实体类。public class Brand { // id 主键 private Integer id; // 品牌名称 private String brandName; // 企业名称 private String companyName; // 排序字段 private Integer ordered; // 描述信息 private String description; // 状态:0:禁用 1:启用 private Integer status; //省略 setter and getter。自己写时要补全这部分代码 } -
编写测试用例
测试代码需要在
test/java目录下创建包及测试用例。项目结构如下:
-
安装 MyBatisX 插件
-
MybatisX 是一款基于 IDEA 的快速开发插件,为效率而生。
-
主要功能
- XML映射配置文件 和 接口方法 间相互跳转
- 根据接口方法生成 statement
-
安装方式
点击
file,选择settings,就能看到如下图所示界面
注意:安装完毕后需要重启IDEA
-
插件效果
红色头绳的表示映射配置文件,蓝色头绳的表示mapper接口。在mapper接口点击红色头绳的小鸟图标会自动跳转到对应的映射配置文件,在映射配置文件中点击蓝色头绳的小鸟图标会自动跳转到对应的mapper接口。也可以在mapper接口中定义方法,自动生成映射配置文件中的
statement,如图所示
-
1.2 查询所有数据
如上图所示就页面上展示的数据,而这些数据需要从数据库进行查询。接下来我们就来讲查询所有数据功能,而实现该功能我们分以下步骤进行实现:
-
编写接口方法:Mapper接口
-
参数:无
查询所有数据功能是不需要根据任何条件进行查询的,所以此方法不需要参数。

-
结果:List
我们会将查询出来的每一条数据封装成一个
Brand对象,而多条数据封装多个Brand对象,需要将这些对象封装到List集合中返回。
-
执行方法、测试
-
1.2.1 编写接口方法
在 com.itheima.mapper 包写创建名为 BrandMapper 的接口。并在该接口中定义 List<Brand> selectAll() 方法。
public interface BrandMapper {
/**
* 查询所有
*/
List<Brand> selectAll();
}
1.2.2 编写SQL语句
在 reources 下创建 com/itheima/mapper 目录结构,并在该目录下创建名为 BrandMapper.xml 的映射配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.mapper.BrandMapper">
<select id="selectAll" resultType="brand">
select *
from tb_brand;
</select>
</mapper>
1.2.3 编写测试方法
在 MybatisTest 类中编写测试查询所有的方法
@Test
public void testSelectAll() throws IOException {
//1. 获取SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//3. 获取Mapper接口的代理对象
BrandMapper brandMapper = sqlSession.getMapper(BrandMapper.class);
//4. 执行方法
List<Brand> brands = brandMapper.selectAll();
System.out.println(brands);
//5. 释放资源
sqlSession.close();
}
注意:现在我们感觉测试这部分代码写起来特别麻烦,我们可以先忍忍。以后我们只会写上面的第3步的代码,其他的都不需要我们来完成。
执行测试方法结果如下:
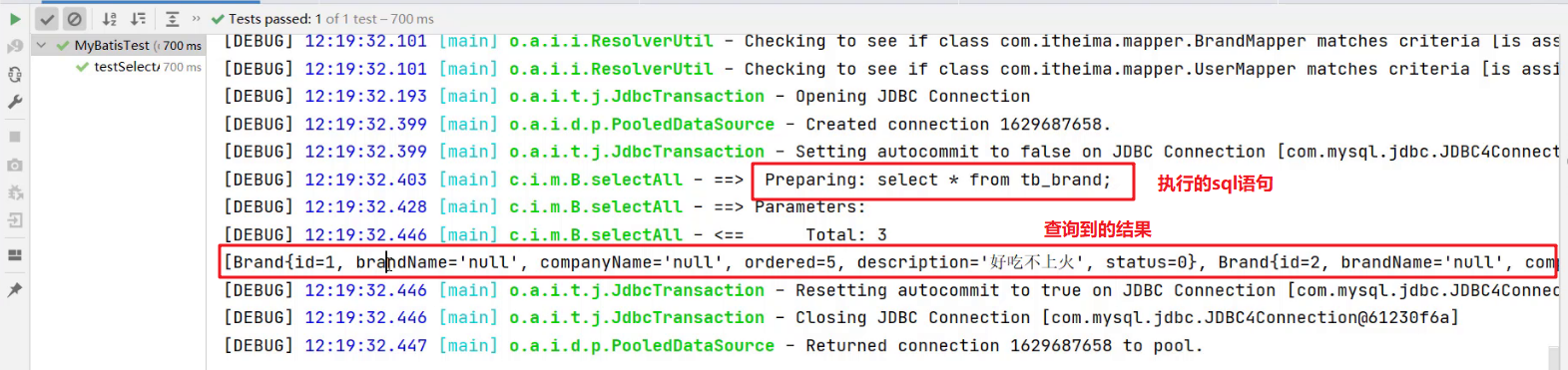
从上面结果我们看到了问题,有些数据封装成功了,而有些数据并没有封装成功。为什么这样呢?
这个问题可以通过两种方式进行解决:
- 给字段起别名
- 使用resultMap定义字段和属性的映射关系
1.2.4 起别名解决上述问题
从上面结果可以看到 brandName 和 companyName 这两个属性的数据没有封装成功,查询 实体类 和 表中的字段 发现,在实体类中属性名是 brandName 和 companyName ,而表中的字段名为 brand_name 和 company_name,如下图所示 。那么我们只需要保持这两部分的名称一致这个问题就迎刃而解。
我们可以在写sql语句时给这两个字段起别名,将别名定义成和属性名一致即可。
<select id="selectAll" resultType="brand">
select
id, brand_name as brandName, company_name as companyName, ordered, description, status
from tb_brand;
</select>
而上面的SQL语句中的字段列表书写麻烦,如果表中还有更多的字段,同时其他的功能也需要查询这些字段时就显得我们的代码不够精炼。Mybatis提供了sql 片段可以提高sql的复用性。
SQL片段:
-
将需要复用的SQL片段抽取到
sql标签中<sql id="brand_column"> id, brand_name as brandName, company_name as companyName, ordered, description, status </sql>id属性值是唯一标识,引用时也是通过该值进行引用。
-
在原sql语句中进行引用
使用
include标签引用上述的 SQL 片段,而refid指定上述 SQL 片段的id值。<select id="selectAll" resultType="brand"> select <include refid="brand_column" /> from tb_brand; </select>
1.2.5 使用resultMap解决上述问题
起别名 + sql片段的方式可以解决上述问题,但是它也存在问题。如果还有功能只需要查询部分字段,而不是查询所有字段,那么我们就需要再定义一个 SQL 片段,这就显得不是那么灵活。
那么我们也可以使用resultMap来定义字段和属性的映射关系的方式解决上述问题。
-
在映射配置文件中使用resultMap定义 字段 和 属性 的映射关系
<resultMap id="brandResultMap" type="brand"> <!-- id:完成主键字段的映射 column:表的列名 property:实体类的属性名 result:完成一般字段的映射 column:表的列名 property:实体类的属性名 --> <result column="brand_name" property="brandName"/> <result column="company_name" property="companyName"/> </resultMap>注意:在上面只需要定义 字段名 和 属性名 不一样的映射,而一样的则不需要专门定义出来。
-
SQL语句正常编写
<select id="selectAll" resultMap="brandResultMap"> select * from tb_brand; </select>
1.2.6 小结
实体类属性名 和 数据库表列名 不一致,不能自动封装数据
- ==起别名:==在SQL语句中,对不一样的列名起别名,别名和实体类属性名一样
- 可以定义 片段,提升复用性
- ==resultMap:==定义 完成不一致的属性名和列名的映射
而我们最终选择使用 resultMap的方式。查询映射配置文件中查询所有的 statement 书写如下:
<resultMap id="brandResultMap" type="brand">
<!--
id:完成主键字段的映射
column:表的列名
property:实体类的属性名
result:完成一般字段的映射
column:表的列名
property:实体类的属性名
-->
<result column="brand_name" property="brandName"/>
<result column="company_name" property="companyName"/>
</resultMap>
<select id="selectAll" resultMap="brandResultMap">
select *
from tb_brand;
</select>
1.3 查询详情
有些数据的属性比较多,在页面表格中无法全部实现,而只会显示部分,而其他属性数据的查询可以通过 查看详情 来进行查询,如上图所示。
查看详情功能实现步骤:
-
编写接口方法:Mapper接口

-
参数:id
查看详情就是查询某一行数据,所以需要根据id进行查询。而id以后是由页面传递过来。
-
结果:Brand
根据id查询出来的数据只要一条,而将一条数据封装成一个Brand对象即可
-
-
编写SQL语句:SQL映射文件

-
执行方法、进行测试
1.3.1 编写接口方法
在 BrandMapper 接口中定义根据id查询数据的方法
/**
* 查看详情:根据Id查询
*/
Brand selectById(int id);
1.3.2 编写SQL语句
在 BrandMapper.xml 映射配置文件中编写 statement,使用 resultMap 而不是使用 resultType
<select id="selectById" resultMap="brandResultMap">
select *
from tb_brand where id = #{id};
</select>
注意:上述SQL中的 #{id}先这样写,一会我们再详细讲解
1.3.3 编写测试方法
在 test/java 下的 com.itheima.mapper 包下的 MybatisTest类中 定义测试方法
@Test
public void testSelectById() throws IOException {
//接收参数,该id以后需要传递过来
int id = 1;
//1. 获取SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//3. 获取Mapper接口的代理对象
BrandMapper brandMapper = sqlSession.getMapper(BrandMapper.class);
//4. 执行方法
Brand brand = brandMapper.selectById(id);
System.out.println(brand);
//5. 释放资源
sqlSession.close();
}
执行测试方法结果如下:
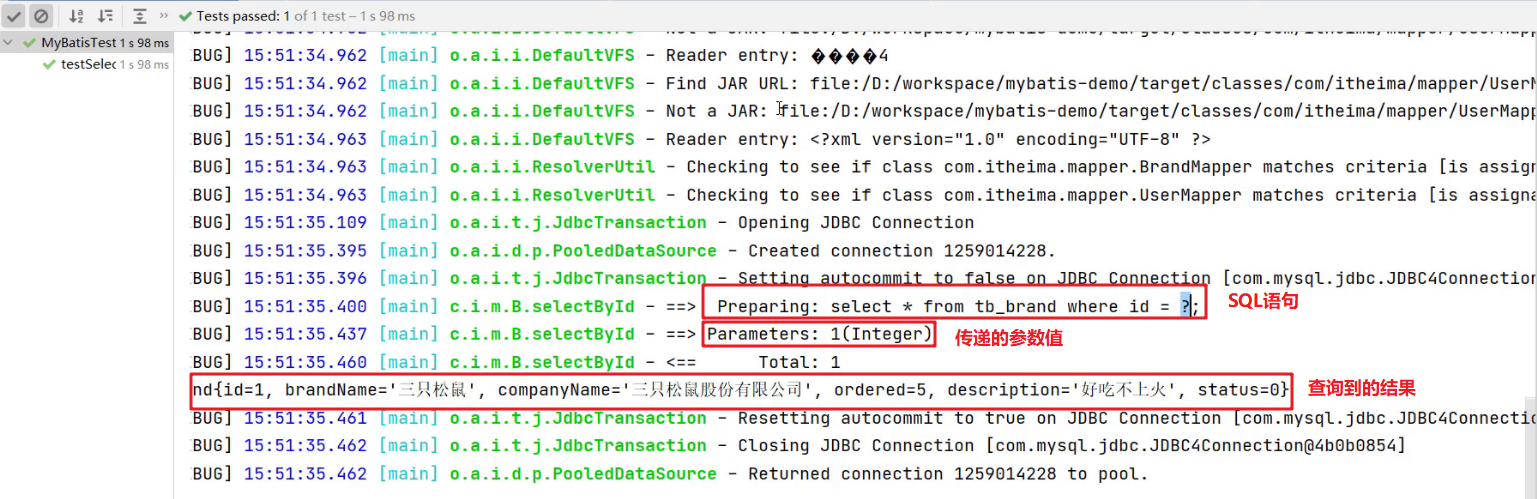
1.3.4 参数占位符
查询到的结果很好理解就是id为1的这行数据。而这里我们需要看控制台显示的SQL语句,能看到使用?进行占位。说明我们在映射配置文件中的写的 #{id} 最终会被?进行占位。接下来我们就聊聊映射配置文件中的参数占位符。
mybatis提供了两种参数占位符:
-
#{} :执行SQL时,会将 #{} 占位符替换为?,将来自动设置参数值。从上述例子可以看出使用#{} 底层使用的是
PreparedStatement -
${} :拼接SQL。底层使用的是
Statement,会存在SQL注入问题。如下图将 映射配置文件中的 #{} 替换成 ${} 来看效果<select id="selectById" resultMap="brandResultMap"> select * from tb_brand where id = ${id}; </select>重新运行查看结果如下:
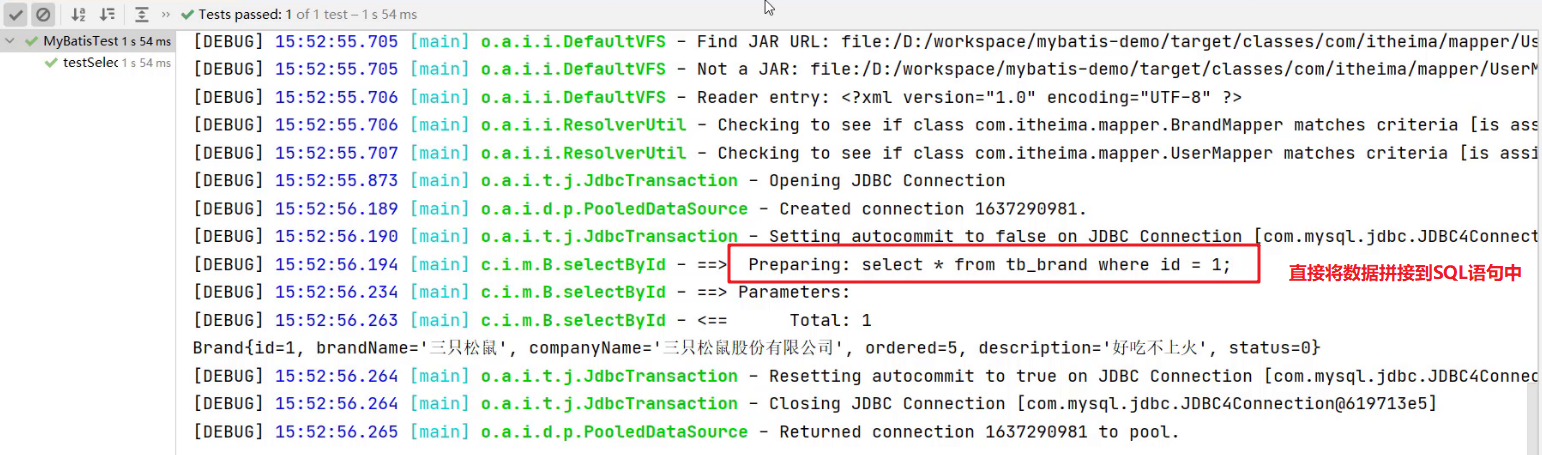
==注意:==从上面两个例子可以看出,以后开发我们使用 #{} 参数占位符。
1.3.5 parameterType使用
对于有参数的mapper接口方法,我们在映射配置文件中应该配置 ParameterType 来指定参数类型。只不过该属性都可以省略。如下图:
<select id="selectById" parameterType="int" resultMap="brandResultMap">
select *
from tb_brand where id = ${id};
</select>
1.3.6 SQL语句中特殊字段处理
以后肯定会在SQL语句中写一下特殊字符,比如某一个字段大于某个值,如下图

可以看出报错了,因为映射配置文件是xml类型的问题,而 > < 等这些字符在xml中有特殊含义,所以此时我们需要将这些符号进行转义,可以使用以下两种方式进行转义
-
转义字符
下图的
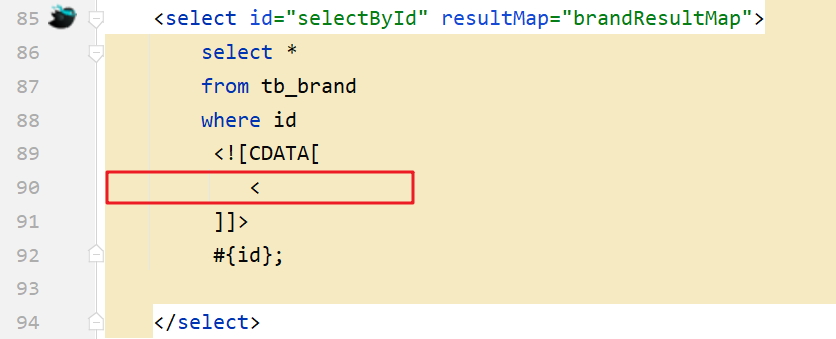
<就是<的转义字符。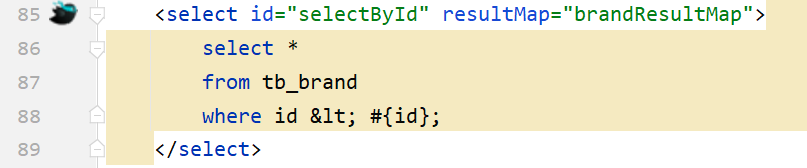
- <![CDATA[内容]]>
1.4 多条件查询

我们经常会遇到如上图所示的多条件查询,将多条件查询的结果展示在下方的数据列表中。而我们做这个功能需要分析最终的SQL语句应该是什么样,思考两个问题
- 条件表达式
- 如何连接
条件字段 企业名称 和 品牌名称 需要进行模糊查询,所以条件应该是:
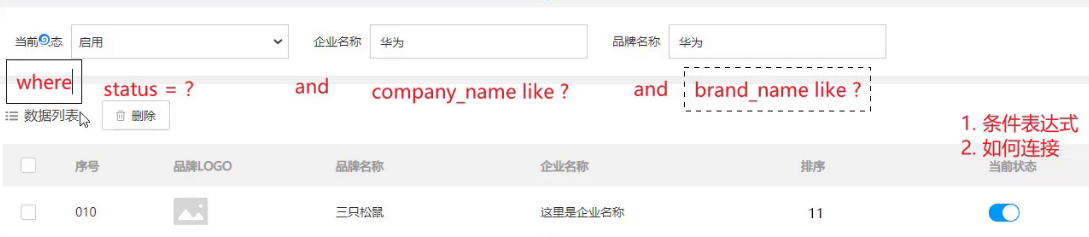
简单的分析后,我们来看功能实现的步骤:
-
编写接口方法
- 参数:所有查询条件
- 结果:List
-
在映射配置文件中编写SQL语句
-
编写测试方法并执行
1.4.1 编写接口方法
在 BrandMapper 接口中定义多条件查询的方法。
而该功能有三个参数,我们就需要考虑定义接口时,参数应该如何定义。Mybatis针对多参数有多种实现
-
使用
@Param("参数名称")标记每一个参数,在映射配置文件中就需要使用#{参数名称}进行占位List<Brand> selectByCondition(@Param("status") int status, @Param("companyName") String companyName,@Param("brandName") String brandName); -
将多个参数封装成一个 实体对象 ,将该实体对象作为接口的方法参数。该方式要求在映射配置文件的SQL中使用
#{内容}时,里面的内容必须和实体类属性名保持一致。List<Brand> selectByCondition(Brand brand); -
将多个参数封装到map集合中,将map集合作为接口的方法参数。该方式要求在映射配置文件的SQL中使用
#{内容}时,里面的内容必须和map集合中键的名称一致。List<Brand> selectByCondition(Map map);
1.4.2 编写SQL语句
在 BrandMapper.xml 映射配置文件中编写 statement,使用 resultMap 而不是使用 resultType
<select id="selectByCondition" resultMap="brandResultMap">
select *
from tb_brand
where status = #{status}
and company_name like #{companyName}
and brand_name like #{brandName}
</select>
1.4.3 编写测试方法
在 test/java 下的 com.itheima.mapper 包下的 MybatisTest类中 定义测试方法
@Test
public void testSelectByCondition() throws IOException {
//接收参数
int status = 1;
String companyName = "华为";
String brandName = "华为";
// 处理参数
companyName = "%" + companyName + "%";
brandName = "%" + brandName + "%";
//1. 获取SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//3. 获取Mapper接口的代理对象
BrandMapper brandMapper = sqlSession.getMapper(BrandMapper.class);
//4. 执行方法
//方式一 :接口方法参数使用 @Param 方式调用的方法
//List<Brand> brands = brandMapper.selectByCondition(status, companyName, brandName);
//方式二 :接口方法参数是 实体类对象 方式调用的方法
//封装对象
/* Brand brand = new Brand();
brand.setStatus(status);
brand.setCompanyName(companyName);
brand.setBrandName(brandName);*/
//List<Brand> brands = brandMapper.selectByCondition(brand);
//方式三 :接口方法参数是 map集合对象 方式调用的方法
Map map = new HashMap();
map.put("status" , status);
map.put("companyName", companyName);
map.put("brandName" , brandName);
List<Brand> brands = brandMapper.selectByCondition(map);
System.out.println(brands);
//5. 释放资源
sqlSession.close();
}
1.4.4 动态SQL
上述功能实现存在很大的问题。用户在输入条件时,肯定不会所有的条件都填写,这个时候我们的SQL语句就不能那样写的
例如用户只输入 当前状态 时,SQL语句就是
select * from tb_brand where status = #{status}
而用户如果只输入企业名称时,SQL语句就是
select * from tb_brand where company_name like #{companName}
而用户如果输入了 当前状态 和 企业名称 时,SQL语句又不一样
select * from tb_brand where status = #{status} and company_name like #{companName}
针对上述的需要,Mybatis对动态SQL有很强大的支撑:
if
choose (when, otherwise)
trim (where, set)
foreach
我们先学习 if 标签和 where 标签:
-
if 标签:条件判断
- test 属性:逻辑表达式
<select id="selectByCondition" resultMap="brandResultMap"> select * from tb_brand where <if test="status != null"> and status = #{status} </if> <if test="companyName != null and companyName != '' "> and company_name like #{companyName} </if> <if test="brandName != null and brandName != '' "> and brand_name like #{brandName} </if> </select>如上的这种SQL语句就会根据传递的参数值进行动态的拼接。如果此时status和companyName有值那么就会值拼接这两个条件。
执行结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AwWyOrZ1-1648965526163)(F:\JavaEE\note\JavaEE\Mybatis\JavaWeb_Mybatis.assets\image-20210729212510291.png)]
但是它也存在问题,如果此时给的参数值是
Map map = new HashMap(); // map.put("status" , status); map.put("companyName", companyName); map.put("brandName" , brandName);拼接的SQL语句就变成了
select * from tb_brand where and company_name like ? and brand_name like ?而上面的语句中 where 关键后直接跟 and 关键字,这就是一条错误的SQL语句。这个就可以使用 where 标签解决
-
where 标签
- 作用:
- 替换where关键字
- 会动态的去掉第一个条件前的 and
- 如果所有的参数没有值则不加where关键字
<select id="selectByCondition" resultMap="brandResultMap"> select * from tb_brand <where> <if test="status != null"> and status = #{status} </if> <if test="companyName != null and companyName != '' "> and company_name like #{companyName} </if> <if test="brandName != null and brandName != '' "> and brand_name like #{brandName} </if> </where> </select>注意:需要给每个条件前都加上 and 关键字。
- 作用:
1.5 单个条件(动态SQL)
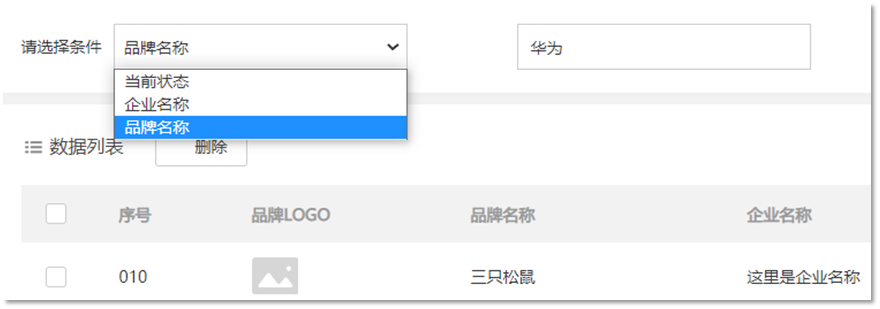
如上图所示,在查询时只能选择 品牌名称、当前状态、企业名称 这三个条件中的一个,但是用户到底选择哪儿一个,我们并不能确定。这种就属于单个条件的动态SQL语句。
这种需求需要使用到 choose(when,otherwise)标签 实现, 而 choose 标签类似于Java 中的switch语句。
通过一个案例来使用这些标签
1.5.1 编写接口方法
在 BrandMapper 接口中定义单条件查询的方法。
/**
* 单条件动态查询
* @param brand
* @return
*/
List<Brand> selectByConditionSingle(Brand brand);
1.5.2 编写SQL语句
在 BrandMapper.xml 映射配置文件中编写 statement,使用 resultMap 而不是使用 resultType
<select id="selectByConditionSingle" resultMap="brandResultMap">
select *
from tb_brand
<where>
<choose><!--相当于switch-->
<when test="status != null"><!--相当于case-->
status = #{status}
</when>
<when test="companyName != null and companyName != '' "><!--相当于case-->
company_name like #{companyName}
</when>
<when test="brandName != null and brandName != ''"><!--相当于case-->
brand_name like #{brandName}
</when>
</choose>
</where>
</select>
1.5.3 编写测试方法
在 test/java 下的 com.itheima.mapper 包下的 MybatisTest类中 定义测试方法
@Test
public void testSelectByConditionSingle() throws IOException {
//接收参数
int status = 1;
String companyName = "华为";
String brandName = "华为";
// 处理参数
companyName = "%" + companyName + "%";
brandName = "%" + brandName + "%";
//封装对象
Brand brand = new Brand();
//brand.setStatus(status);
brand.setCompanyName(companyName);
//brand.setBrandName(brandName);
//1. 获取SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//3. 获取Mapper接口的代理对象
BrandMapper brandMapper = sqlSession.getMapper(BrandMapper.class);
//4. 执行方法
List<Brand> brands = brandMapper.selectByConditionSingle(brand);
System.out.println(brands);
//5. 释放资源
sqlSession.close();
}
执行测试方法结果如下:
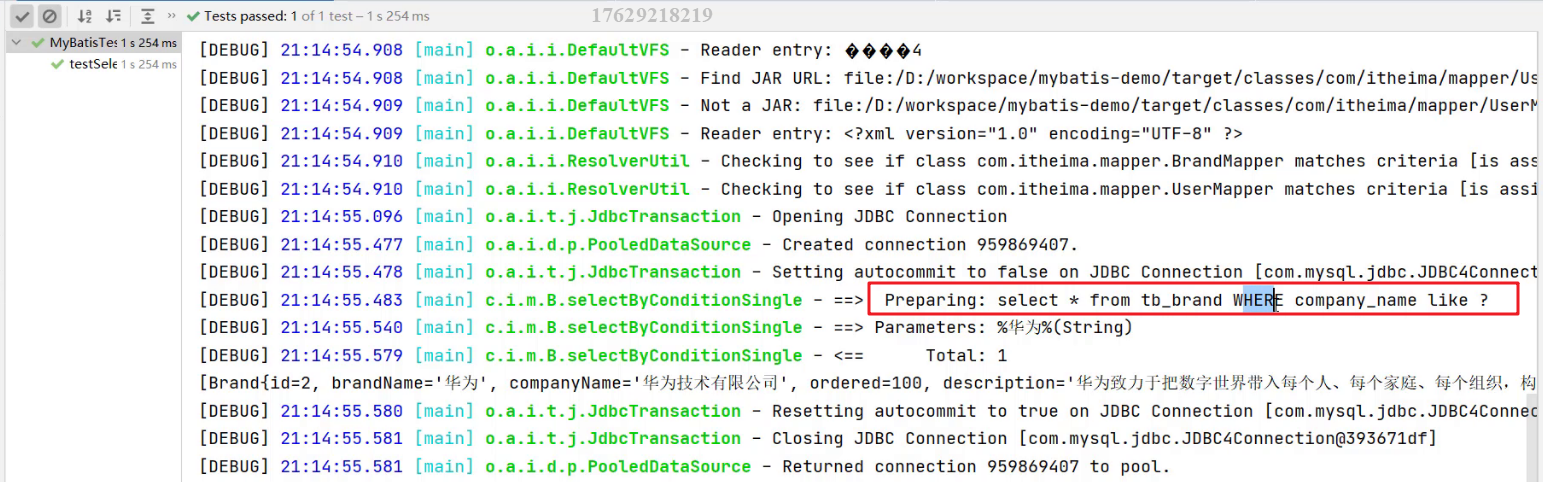
1.6 添加数据
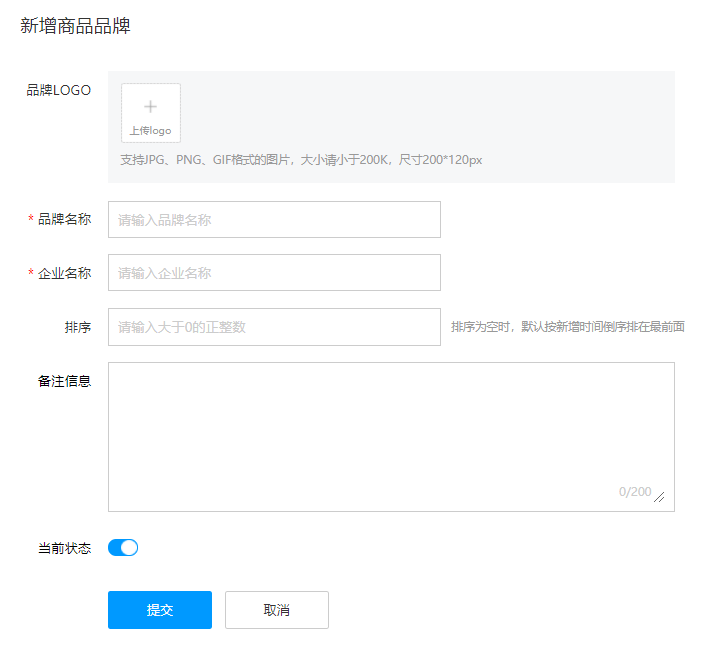
如上图是我们平时在添加数据时展示的页面,而我们在该页面输入想要的数据后添加 提交 按钮,就会将这些数据添加到数据库中。接下来我们就来实现添加数据的操作。
-
编写接口方法

参数:除了id之外的所有的数据。id对应的是表中主键值,而主键我们是 自动增长 生成的。
-
编写SQL语句
-
编写测试方法并执行
明确了该功能实现的步骤后,接下来我们进行具体的操作。
1.6.1 编写接口方法
在 BrandMapper 接口中定义添加方法。
/**
* 添加
*/
void add(Brand brand);
1.6.2 编写SQL语句
在 BrandMapper.xml 映射配置文件中编写添加数据的 statement
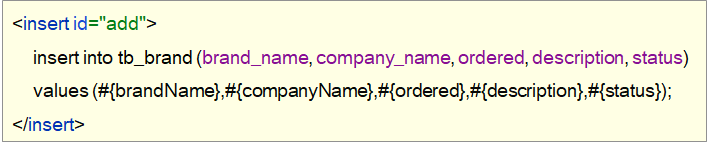
<insert id="add">
insert into tb_brand (brand_name, company_name, ordered, description, status)
values (#{brandName}, #{companyName}, #{ordered}, #{description}, #{status});
</insert>
1.6.3 编写测试方法
在 test/java 下的 com.itheima.mapper 包下的 MybatisTest类中 定义测试方法
@Test
public void testAdd() throws IOException {
//接收参数
int status = 1;
String companyName = "波导手机";
String brandName = "波导";
String description = "手机中的战斗机";
int ordered = 100;
//封装对象
Brand brand = new Brand();
brand.setStatus(status);
brand.setCompanyName(companyName);
brand.setBrandName(brandName);
brand.setDescription(description);
brand.setOrdered(ordered);
//1. 获取SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//SqlSession sqlSession = sqlSessionFactory.openSession(true); //设置自动提交事务,这种情况不需要手动提交事务了
//3. 获取Mapper接口的代理对象
BrandMapper brandMapper = sqlSession.getMapper(BrandMapper.class);
//4. 执行方法
brandMapper.add(brand);
//提交事务
sqlSession.commit();
//5. 释放资源
sqlSession.close();
}
执行结果如下:

1.6.4 添加-主键返回
在数据添加成功后,有时候需要获取插入数据库数据的主键(主键是自增长)。
比如:添加订单和订单项,如下图就是京东上的订单
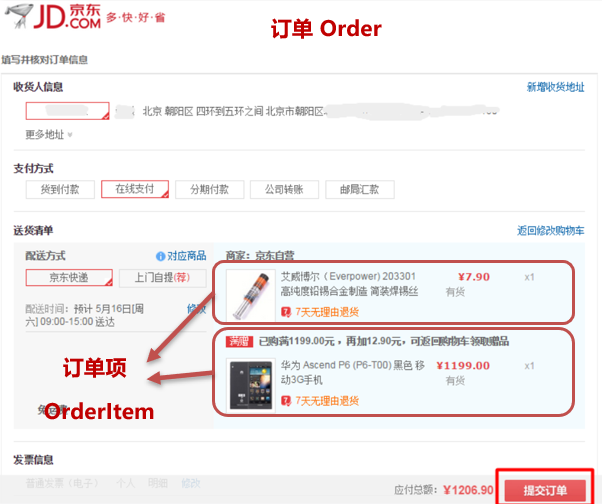
订单数据存储在订单表中,订单项存储在订单项表中。
-
添加订单数据
-
添加订单项数据,订单项中需要设置所属订单的id
明白了什么时候 主键返回 。接下来我们简单模拟一下,在添加完数据后打印id属性值,能打印出来说明已经获取到了。
我们将上面添加品牌数据的案例中映射配置文件里 statement 进行修改,如下
<insert id="add" useGeneratedKeys="true" keyProperty="id">
insert into tb_brand (brand_name, company_name, ordered, description, status)
values (#{brandName}, #{companyName}, #{ordered}, #{description}, #{status});
</insert>
在 insert 标签上添加如下属性:
- useGeneratedKeys:是够获取自动增长的主键值。true表示获取
- keyProperty :指定将获取到的主键值封装到哪儿个属性里
1.7 修改
如图所示是修改页面,用户在该页面书写需要修改的数据,点击 提交 按钮,就会将数据库中对应的数据进行修改。注意一点,如果哪儿个输入框没有输入内容,我们是将表中数据对应字段值替换为空白还是保留字段之前的值?答案肯定是保留之前的数据。
接下来我们就具体来实现
1.7.1 编写接口方法
在 BrandMapper 接口中定义修改方法。
/**
* 修改
*/
void update(Brand brand);
上述方法参数 Brand 就是封装了需要修改的数据,而id肯定是有数据的,这也是和添加方法的区别。
1.7.2 编写SQL语句
在 BrandMapper.xml 映射配置文件中编写修改数据的 statement。
<update id="update">
update tb_brand
<set>
<if test="brandName != null and brandName != ''">
brand_name = #{brandName},
</if>
<if test="companyName != null and companyName != ''">
company_name = #{companyName},
</if>
<if test="ordered != null">
ordered = #{ordered},
</if>
<if test="description != null and description != ''">
description = #{description},
</if>
<if test="status != null">
status = #{status}
</if>
</set>
where id = #{id};
</update>
set 标签可以用于动态包含需要更新的列,忽略其它不更新的列。
1.7.3 编写测试方法
在 test/java 下的 com.itheima.mapper 包下的 MybatisTest类中 定义测试方法
@Test
public void testUpdate() throws IOException {
//接收参数
int status = 0;
String companyName = "波导手机";
String brandName = "波导";
String description = "波导手机,手机中的战斗机";
int ordered = 200;
int id = 6;
//封装对象
Brand brand = new Brand();
brand.setStatus(status);
// brand.setCompanyName(companyName);
// brand.setBrandName(brandName);
// brand.setDescription(description);
// brand.setOrdered(ordered);
brand.setId(id);
//1. 获取SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//SqlSession sqlSession = sqlSessionFactory.openSession(true);
//3. 获取Mapper接口的代理对象
BrandMapper brandMapper = sqlSession.getMapper(BrandMapper.class);
//4. 执行方法
int count = brandMapper.update(brand);
System.out.println(count);
//提交事务
sqlSession.commit();
//5. 释放资源
sqlSession.close();
}
执行测试方法结果如下:

从结果中SQL语句可以看出,只修改了 status 字段值,因为我们给的数据中只给Brand实体对象的 status 属性设置值了。这就是 set 标签的作用。
1.8 删除一行数据

如上图所示,每行数据后面都有一个 删除 按钮,当用户点击了该按钮,就会将改行数据删除掉。那我们就需要思考,这种删除是根据什么进行删除呢?是通过主键id删除,因为id是表中数据的唯一标识。
接下来就来实现该功能。
1.8.1 编写接口方法
在 BrandMapper 接口中定义根据id删除方法。
/**
* 根据id删除
*/
void deleteById(int id);
1.8.2 编写SQL语句
在 BrandMapper.xml 映射配置文件中编写删除一行数据的 statement
<delete id="deleteById">
delete from tb_brand where id = #{id};
</delete>
1.8.3 编写测试方法
在 test/java 下的 com.itheima.mapper 包下的 MybatisTest类中 定义测试方法
@Test
public void testDeleteById() throws IOException {
//接收参数
int id = 6;
//1. 获取SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//SqlSession sqlSession = sqlSessionFactory.openSession(true);
//3. 获取Mapper接口的代理对象
BrandMapper brandMapper = sqlSession.getMapper(BrandMapper.class);
//4. 执行方法
brandMapper.deleteById(id);
//提交事务
sqlSession.commit();
//5. 释放资源
sqlSession.close();
}
运行过程只要没报错,直接到数据库查询数据是否还存在。
1.9 批量删除
如上图所示,用户可以选择多条数据,然后点击上面的 删除 按钮,就会删除数据库中对应的多行数据。
1.9.1 编写接口方法
在 BrandMapper 接口中定义删除多行数据的方法。
/**
* 批量删除
*/
void deleteByIds(int[] ids);
参数是一个数组,数组中存储的是多条数据的id
1.9.2 编写SQL语句
在 BrandMapper.xml 映射配置文件中编写删除多条数据的 statement。
编写SQL时需要遍历数组来拼接SQL语句。Mybatis 提供了 foreach 标签供我们使用
foreach 标签
用来迭代任何可迭代的对象(如数组,集合)。
- collection 属性:
- mybatis会将数组参数,封装为一个Map集合。
- 默认:array = 数组
- 使用@Param注解改变map集合的默认key的名称
- mybatis会将数组参数,封装为一个Map集合。
- item 属性:本次迭代获取到的元素。
- separator 属性:集合项迭代之间的分隔符。
foreach标签不会错误地添加多余的分隔符。也就是最后一次迭代不会加分隔符。 - open 属性:该属性值是在拼接SQL语句之前拼接的语句,只会拼接一次
- close 属性:该属性值是在拼接SQL语句拼接后拼接的语句,只会拼接一次
<delete id="deleteByIds">
delete from tb_brand where id
in
<foreach collection="array" item="id" separator="," open="(" close=")">
#{id}
</foreach>
;
</delete>
假如数组中的id数据是{1,2,3},那么拼接后的sql语句就是:
delete from tb_brand where id in (1,2,3);
1.9.3 编写测试方法
在 test/java 下的 com.itheima.mapper 包下的 MybatisTest类中 定义测试方法
@Test
public void testDeleteByIds() throws IOException {
//接收参数
int[] ids = {5,7,8};
//1. 获取SqlSessionFactory
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//2. 获取SqlSession对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//SqlSession sqlSession = sqlSessionFactory.openSession(true);
//3. 获取Mapper接口的代理对象
BrandMapper brandMapper = sqlSession.getMapper(BrandMapper.class);
//4. 执行方法
brandMapper.deleteByIds(ids);
//提交事务
sqlSession.commit();
//5. 释放资源
sqlSession.close();
}
1.10 Mybatis参数传递
Mybatis 接口方法中可以接收各种各样的参数,如下:
- 多个参数
- 单个参数:单个参数又可以是如下类型
- POJO 类型
- Map 集合类型
- Collection 集合类型
- List 集合类型
- Array 类型
- 其他类型
1.10.1 多个参数
如下面的代码,就是接收两个参数,而接收多个参数需要使用 @Param 注解,那么为什么要加该注解呢?这个问题要弄明白就必须来研究Mybatis 底层对于这些参数是如何处理的。
User select(@Param("username") String username,@Param("password") String password);
<select id="select" resultType="user">
select *
from tb_user
where
username=#{username}
and password=#{password}
</select>
我们在接口方法中定义多个参数,Mybatis 会将这些参数封装成 Map 集合对象,值就是参数值,而键在没有使用 @Param 注解时有以下命名规则:
-
以 arg 开头 :第一个参数就叫 arg0,第二个参数就叫 arg1,以此类推。如:
map.put(“arg0”,参数值1);
map.put(“arg1”,参数值2);
-
以 param 开头 : 第一个参数就叫 param1,第二个参数就叫 param2,依次类推。如:
map.put(“param1”,参数值1);
map.put(“param2”,参数值2);
代码验证:
-
在
UserMapper接口中定义如下方法User select(String username,String password); -
在
UserMapper.xml映射配置文件中定义SQL<select id="select" resultType="user"> select * from tb_user where username=#{arg0} and password=#{arg1} </select>或者
<select id="select" resultType="user"> select * from tb_user where username=#{param1} and password=#{param2} </select> -
运行代码结果如下
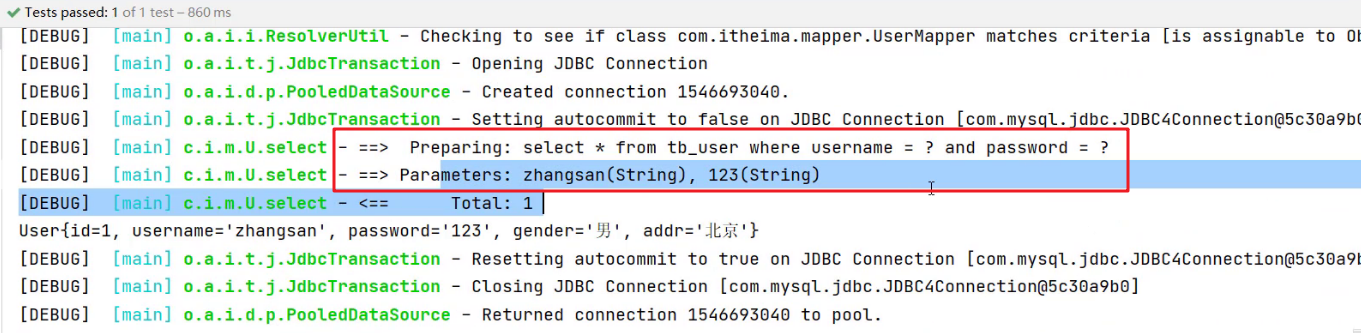
在映射配合文件的SQL语句中使用用
arg开头的和param书写,代码的可读性会变的特别差,此时可以使用@Param注解。
在接口方法参数上使用 @Param 注解,Mybatis 会将 arg 开头的键名替换为对应注解的属性值。
代码验证:
-
在
UserMapper接口中定义如下方法,在username参数前加上@Param注解User select(@Param("username") String username, String password);Mybatis 在封装 Map 集合时,键名就会变成如下:
map.put(“username”,参数值1);
map.put(“arg1”,参数值2);
map.put(“param1”,参数值1);
map.put(“param2”,参数值2);
-
在
UserMapper.xml映射配置文件中定义SQL<select id="select" resultType="user"> select * from tb_user where username=#{username} and password=#{param2} </select> -
运行程序结果没有报错。而如果将
#{}中的username还是写成arg0<select id="select" resultType="user"> select * from tb_user where username=#{arg0} and password=#{param2} </select> -
运行程序则可以看到错误
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZvTCyMlr-1648965526165)(F:\JavaEE\note\JavaEE\Mybatis\JavaWeb_Mybatis.assets\image-20210805231727206.png)]
结论:以后接口参数是多个时,在每个参数上都使用 @Param 注解。这样代码的可读性更高。
1.10.2 单个参数
-
POJO 类型
直接使用。要求
属性名和参数占位符名称一致 -
Map 集合类型
直接使用。要求
map集合的键名和参数占位符名称一致 -
Collection 集合类型
Mybatis 会将集合封装到 map 集合中,如下:
map.put(“arg0”,collection集合);
map.put(“collection”,collection集合;
可以使用
@Param注解替换map集合中默认的 arg 键名。 -
List 集合类型
Mybatis 会将集合封装到 map 集合中,如下:
map.put(“arg0”,list集合);
map.put(“collection”,list集合);
map.put(“list”,list集合);
可以使用
@Param注解替换map集合中默认的 arg 键名。 -
Array 类型
Mybatis 会将集合封装到 map 集合中,如下:
map.put(“arg0”,数组);
map.put(“array”,数组);
可以使用
@Param注解替换map集合中默认的 arg 键名。 -
其他类型
比如int类型,
参数占位符名称叫什么都可以。尽量做到见名知意
2,注解实现CRUD
使用注解开发会比配置文件开发更加方便。如下就是使用注解进行开发
@Select(value = "select * from tb_user where id = #{id}")
public User select(int id);
注意:
- 注解是用来替换映射配置文件方式配置的,所以使用了注解,就不需要再映射配置文件中书写对应的
statement
Mybatis 针对 CURD 操作都提供了对应的注解,已经做到见名知意。如下:
- 查询 :@Select
- 添加 :@Insert
- 修改 :@Update
- 删除 :@Delete
接下来我们做一个案例来使用 Mybatis 的注解开发
代码实现:
-
将之前案例中
UserMapper.xml中的 根据id查询数据 的statement注释掉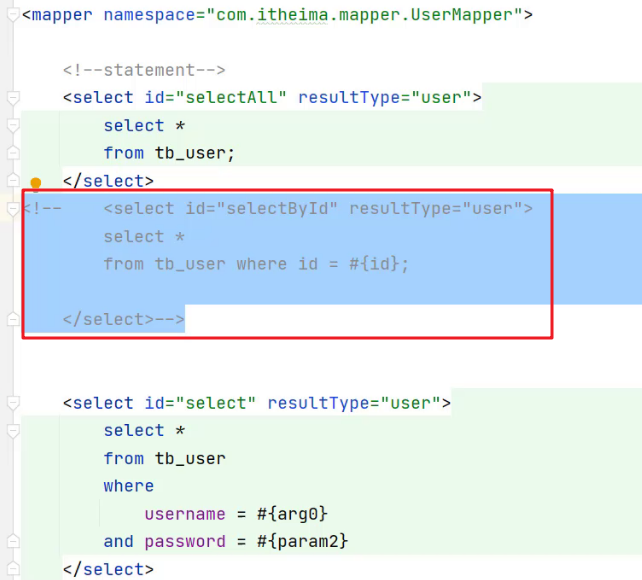
-
在
UserMapper接口的selectById方法上添加注解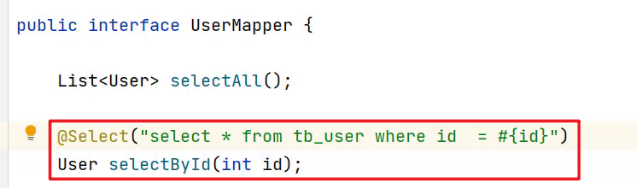
-
运行测试程序也能正常查询到数据
我们课程上只演示这一个查询的注解开发,其他的同学们下来可以自己实现,都是比较简单。
==注意:==在官方文档中 入门 中有这样的一段话:

所以,注解完成简单功能,配置文件完成复杂功能。
而我们之前写的动态 SQL 就是复杂的功能,如果用注解使用的话,就需要使用到 Mybatis 提供的SQL构建器来完成,而对应的代码如下:

上述代码将java代码和SQL语句融到了一块,使得代码的可读性大幅度降低。
Maven
简介
Maven本质上是一个项目管理工具,将项目开发和管理过程抽象成一个项目对象模型
POM:项目对象模型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DBTTm70Z-1648965526166)(F:\JavaEE\note\images\1a4cb448c6ef96c572a673c43f5e711f285ad99436e039f9a47745e1bfc1e9e1.png)]
作用
- 提供一套标准化的项目结构
- 提供了一套标准化的构建流程
- 提供了一套依赖管理机制
基本概念
仓库
仓库:用于存储资源,包含各种jar包
仓库分类:
- 本地仓库:自己电脑上存储的仓库
- 远程仓库:非本机电脑上的仓库
- 中央仓库:Maven团队维护的仓库
- 私服:公司范围内存储资源的仓库
- 私服的作用:
- 保存具有版权的资源
- 一定范围内共享资源
- 私服的作用:
中央仓库
jar包查找顺序:本地仓库→ 远程仓库→ 中央仓库
坐标
坐标是资源的唯一标识
使用坐标来定义项目或引入项目中需要的依赖
Maven坐标组成
- groupId: 定义当前项目隶属组织名称
- artifactId: 定义当前项目名称
- version: 定义当前项目版本号
配置本地仓库
conf/settings.xml
<localRepository>D:\dev\apache-maven-3.8.4\mvn_resp</localRepository>
配置阿里源
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
<blocked></blocked>
</mirror>
IDEA创建Maven项目
1.不使用原型创建
创建空项目,之后配置下SDK
设置配置Maven setting路径

创建新模块


[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cYctLFiU-1648965526169)(https://s2.loli.net/2022/04/03/Z65LVS1OYjWowGk.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8r2qBa52-1648965526169)(https://s2.loli.net/2022/04/03/BqhfNYlszv9myjo.png)]
在pom.xml 按住alt+Ins

添加单元测试依赖

2.原型创建Java项目

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LsOc78g2-1648965526171)(https://s2.loli.net/2022/04/03/STKnOE2ztFgXsyl.png)]
3.原型创建web项目



添加Tomcat插件
<build>
<plugins>
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
<configuration>
<port>80</port>
<path>/</path>
</configuration>
</plugin>
</plugins>
</build>
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<!-- 指定pom的模型版本-->
<modelVersion>4.0.0</modelVersion>
<!-- 打包方式-->
<packaging>war</packaging>
<!-- 组织id-->
<groupId>com.itheima</groupId>
<!-- 项目id-->
<artifactId>java03</artifactId>
<!-- 版本号-->
<version>1.0-SNAPSHOT</version>
<name>java03</name>
<build>
<plugins>
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
<configuration>
<port>80</port>
<path>/</path>
</configuration>
</plugin>
</plugins>
</build>
</project>
依赖管理
-
依赖配置
-
依赖是指当前项目运行所需的jar,一个项目可以设置多个依赖
<!-- 设置当前项目所依赖的所有jar--> <dependencies> <!-- 设置具体的依赖--> <dependency> <!-- 依赖所属的群组id--> <groupId>junit</groupId> <!-- 依赖所属项目id--> <artifactId>junit</artifactId> <!-- 依赖版本号--> <version>4.13.2</version> <!-- 只在开发阶段生效--> <scope>test</scope> </dependency> </dependencies>
-
-
依赖传递
- 依赖具有传递性
- 直接依赖:在当前项目中通过依赖配置建立的依赖关系
- 简介依赖:被依赖的资源如果依赖其他资源,当前项目简介依赖其他资源
- 解决传递冲突的问题
- 路径优先:当依赖中出现相同的资源,层级越深,优先级越低,层次越浅,优先级越高
- 声明优先:当资源在相同层级被依赖时,配置顺序靠前的覆盖配置顺序靠后的
- 特殊优先:当同级配置了相同资源的不同版本,后配置的覆盖先配置的
- 依赖具有传递性
-
可选依赖
-
可选依赖是指对外隐藏当前所依赖的资源 — 不透明
<optional>true</optional> -
<dependency> <!-- 依赖所属的群组id--> <groupId>junit</groupId> <!-- 依赖所属项目id--> <artifactId>junit</artifactId> <!-- 依赖版本号--> <version>4.13.2</version> <optional>true</optional> <!-- 只在开发阶段生效--> <scope>test</scope> </dependency>
-
-
排除依赖
-
主动断开依赖的资源,被排除的资源无需指定版本
<dependency> <!-- 组织id--> <groupId>com.itheima</groupId> <!-- 项目id--> <artifactId>java03</artifactId> <!-- 版本号--> <version>1.0-SNAPSHOT</version> <exclusions> <exclusion> <!-- 依赖所属的群组id--> <groupId>junit</groupId> <!-- 依赖所属项目id--> <artifactId>junit</artifactId> </exclusion> </exclusions> </dependency>
-
-
依赖范围
- 依赖的jar默认情况在任何地方使用,可以通过scope标签设定其作用范围
- 作用范围
- 主程序范围有效(main文件夹范围内)
- 测试程序范围有效
- 是否参与打包(package指令范围内)
scope 主代码 测试代码 打包 范例 compile(默认) Y Y Y log4j test Y junit provided Y Y servlet-api runtime Y jdbc - 依赖范围传递性
- 带有依赖范围的资源在进行传递时,作用范围会受到影响
| complle | test | provided | runtime | 直接依赖 | |
|---|---|---|---|---|---|
| compile | compile | test | provided | runtime | |
| test | |||||
| provided | |||||
| runtime | runtime | test | provided | runtime | |
| 间接依赖 |
生命周期与插件
Maven构建生命周期描述的是一次构建过程经历了多少个事件
- clear 清理工作
- default 核心工作,编译测试打包部署等
- site 产生报告,发布站点



生命周期与插件
- 插件与生命周期内的阶段绑定,在执行到对应生命周期时执行对应的插件功能
- 默认maven 在各个生命周期上绑定有预设的功能
- 通过插件可以自定义其他功能

Maven继承关系
将dependencies全部放入dependencyManagement节点,这样父项目就完全作为依赖统一管理。
<dependencyManagement>
<dependencies>
</dependencies>
</dependencyManagement>
Maven常用命令
clean命令,执行后会清理整个target文件夹,在之后编写Springboot项目时可以解决一些缓存没更新的问题。validate命令可以验证项目的可用性。compile命令可以将项目编译为.class文件。install命令可以将当前项目安装到本地仓库,以供其他项目导入作为依赖使用verify命令可以按顺序执行每个默认生命周期阶段(validate,compile,package等)
Maven测试项目
通过使用test命令,可以一键测试所有位于test目录下的测试案例,请注意有以下要求:
- 测试类的名称必须是以
Test结尾,比如MainTest - 测试方法上必须标注
@Test注解,实测@RepeatedTest无效
Maven测试项目
通过使用test命令,可以一键测试所有位于test目录下的测试案例,请注意有以下要求:
- 测试类的名称必须是以
Test结尾,比如MainTest - 测试方法上必须标注
@Test注解,实测@RepeatedTest无效
这是由于JUnit5比较新,我们需要重新配置插件升级到高版本,才能完美的兼容Junit5:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<!-- JUnit 5 requires Surefire version 2.22.0 or higher -->
<version>2.22.0</version>
</plugin>
</plugins>
</build>
现在@RepeatedTest、@BeforeAll也能使用了。
Junit5
https://junit.org/junit5/docs/current/user-guide/#writing-tests-annotations
-
常用注解
@Test:标识只是一个测试用例
@BeforeEach:一次性开启所有测试案例每个案例开始之前都会执行一次
@AfterEach:在每个测试方法执行之后,总会调用这个方法,一般用于释放资源
@Disabled:忽略测试用例,让相应的测试用例不运行,用在方法上或者类上
@BeforeAll 和@AfterAll : 和上面的@BeforeEach和@AfterEach非常类似,区别在于,这两个方法必须标注在静态方法上面,且只会执行一次 -
高级注解
@Nested:内嵌测试注解,用于把一组测试归纳起来;
@RepeatedTest:重复多次测试注解
@ParameterizedTest:带参数的注解 -
断言Assertions
assert关键字:可以用来断定一些简单的逻辑
assertEquals:断言结果相等,如果不等,则不通过,有很多对的重载方法;
assertNotNull:断言不为空,
assertThrows:断言抛出异常
assertTimeout:断言超时,如果方法运行的时间超过了指定的时间,就无法通过
assertAll:进行一组断言,如果前一个失败了,后续不再执行。
- 假设Assumptions
Assumptions用来做条件测试的,都在org.junit.jupiter.api.Assumptions包下面,主要有以下几个方法:
assumeTrue:假设某个事情是正确的,[返回某个字符串]
assumeFalse:假设某个情况是错误的,[返回某个字符串]
assumingThat:假设某个表达式是正确时候,执行某个操作
JUL日志系统
JUL日志讲解
日志分为7个级别,详细信息我们可以在Level类中查看:
- SEVERE(最高值)- 一般用于代表严重错误
- WARNING - 一般用于表示某些警告,但是不足以判断为错误
- INFO (默认级别) - 常规消息
- CONFIG
- FINE
- FINER
- FINEST(最低值)
我们之前通过info方法直接输出的结果就是使用的默认级别的日志,我们可以通过log方法来设定该条日志的输出级别:
public static void main(String[] args) {
Logger logger = Logger.getLogger(Main.class.getName());
logger.log(Level.SEVERE, "严重的错误", new IOException("我就是错误"));
logger.log(Level.WARNING, "警告的内容");
logger.log(Level.INFO, "普通的信息");
logger.log(Level.CONFIG, "级别低于普通信息");
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DD9aIBkF-1648965526174)(F:\JavaEE\note\JavaEE\JavaWeb整合\JavaWeb整合.assets\image-20220331091949005.png)]
我们发现,级别低于默认级别的日志信息,无法输出到控制台,我们可以通过设置来修改日志的打印级别:
public static void main(String[] args) {
Logger logger = Logger.getLogger(Main.class.getName());
//修改日志级别
logger.setLevel(Level.CONFIG);
//不使用父日志处理器
logger.setUseParentHandlers(false);
//使用自定义日志处理器
ConsoleHandler handler = new ConsoleHandler();
handler.setLevel(Level.CONFIG);
logger.addHandler(handler);
logger.log(Level.SEVERE, "严重的错误", new IOException("我就是错误"));
logger.log(Level.WARNING, "警告的内容");
logger.log(Level.INFO, "普通的信息");
logger.log(Level.CONFIG, "级别低于普通信息");
}
每个Logger都有一个父日志打印器,我们可以通过getParent()来获取:
public static void main(String[] args) throws IOException {
Logger logger = Logger.getLogger(Main.class.getName());
System.out.println(logger.getParent().getClass());
}
我们发现,得到的是java.util.logging.LogManager$RootLogger这个类,它默认使用的是ConsoleHandler,且日志级别为INFO,由于每一个日志打印器都会直接使用父类的处理器,因此我们之前需要关闭父类然后使用我们自己的处理器。
我们通过使用自己日志处理器来自定义级别的信息打印到控制台,当然,日志处理器不仅仅只有控制台打印,我们也可以使用文件处理器来处理日志信息,我们继续添加一个处理器:
//添加输出到本地文件
FileHandler fileHandler = new FileHandler("test.log");
fileHandler.setLevel(Level.WARNING);
logger.addHandler(fileHandler);
注意,这个时候就有两个日志处理器了,因此控制台和文件的都会生效。如果日志的打印格式我们不喜欢,我们还可以自定义打印格式,比如我们控制台处理器就默认使用的是SimpleFormatter,而文件处理器则是使用的XMLFormatter,我们可以自定义:
//使用自定义日志处理器(控制台)
ConsoleHandler handler = new ConsoleHandler();
handler.setLevel(Level.CONFIG);
handler.setFormatter(new XMLFormatter());
logger.addHandler(handler);
我们可以直接配置为想要的打印格式,如果这些格式还不能满足你,那么我们也可以自行实现:
public static void main(String[] args) throws IOException {
Logger logger = Logger.getLogger(Main.class.getName());
logger.setUseParentHandlers(false);
//为了让颜色变回普通的颜色,通过代码块在初始化时将输出流设定为System.out
ConsoleHandler handler = new ConsoleHandler(){{
setOutputStream(System.out);
}};
//创建匿名内部类实现自定义的格式
handler.setFormatter(new Formatter() {
@Override
public String format(LogRecord record) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String time = format.format(new Date(record.getMillis())); //格式化日志时间
String level = record.getLevel().getName(); // 获取日志级别名称
// String level = record.getLevel().getLocalizedName(); // 获取本地化名称(语言跟随系统)
String thread = String.format("%10s", Thread.currentThread().getName()); //线程名称(做了格式化处理,留出10格空间)
long threadID = record.getThreadID(); //线程ID
String className = String.format("%-20s", record.getSourceClassName()); //发送日志的类名
String msg = record.getMessage(); //日志消息
//\033[33m作为颜色代码,30~37都有对应的颜色,38是没有颜色,IDEA能显示,但是某些地方可能不支持
return "\033[38m" + time + " \033[33m" + level + " \033[35m" + threadID
+ "\033[38m --- [" + thread + "] \033[36m" + className + "\033[38m : " + msg + "\n";
}
});
logger.addHandler(handler);
logger.info("我是测试消息1...");
logger.log(Level.INFO, "我是测试消息2...");
logger.log(Level.WARNING, "我是测试消息3...");
}
日志可以设置过滤器,如果我们不希望某些日志信息被输出,我们可以配置过滤规则:
public static void main(String[] args) throws IOException {
Logger logger = Logger.getLogger(Main.class.getName());
//自定义过滤规则
logger.setFilter(record -> !record.getMessage().contains("普通"));
logger.log(Level.SEVERE, "严重的错误", new IOException("我就是错误"));
logger.log(Level.WARNING, "警告的内容");
logger.log(Level.INFO, "普通的信息");
}
实际上,整个日志的输出流程如下:

Properties配置文件
Properties文件是Java的一种配置文件,我们之前学习了XML,但是我们发现XML配置文件读取实在是太麻烦,那么能否有一种简单一点的配置文件呢?我们可以使用Properties文件:
name=Test
desc=Description
该文件配置很简单,格式为配置项=配置值,我们可以直接通过Properties类来将其读取为一个类似于Map一样的对象:
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
properties.load(new FileInputStream("test.properties"));
System.out.println(properties);
}
我们发现,Properties类是继承自Hashtable,而Hashtable是实现的Map接口,也就是说,Properties本质上就是一个Map一样的结构,它会把所有的配置项映射为一个Map,这样我们就可以快速地读取对应配置的值了。
我们也可以将已经存在的Properties对象放入输出流进行保存,我们这里就不保存文件了,而是直接打印到控制台,我们只需要提供输出流即可:
public static void main(String[] args) throws IOException {
Properties properties = new Properties();
// properties.setProperty("test", "lbwnb"); //和put效果一样
properties.put("test", "lbwnb");
properties.store(System.out, "????");
//properties.storeToXML(System.out, "????"); 保存为XML格式
}
我们可以通过System.getProperties()获取系统的参数,我们来看看:
public static void main(String[] args) throws IOException {
System.getProperties().store(System.out, "系统信息:");
}
编写日志配置文件
我们可以通过进行配置文件来规定日志打印器的一些默认值:
# RootLogger 的默认处理器为
handlers= java.util.logging.ConsoleHandler
# RootLogger 的默认的日志级别
.level= CONFIG
我们来尝试使用配置文件来进行配置:
public static void main(String[] args) throws IOException {
//获取日志管理器
LogManager manager = LogManager.getLogManager();
//读取我们自己的配置文件
manager.readConfiguration(new FileInputStream("logging.properties"));
//再获取日志打印器
Logger logger = Logger.getLogger(Main.class.getName());
logger.log(Level.CONFIG, "我是一条日志信息"); //通过自定义配置文件,我们发现默认级别不再是INFO了
}
我们也可以去修改ConsoleHandler的默认配置:
# 指定默认日志级别
java.util.logging.ConsoleHandler.level = ALL
# 指定默认日志消息格式
java.util.logging.ConsoleHandler.formatter = java.util.logging.SimpleFormatter
# 指定默认的字符集
java.util.logging.ConsoleHandler.encoding = UTF-8
其实,我们阅读ConsoleHandler的源码就会发现,它就是通过读取配置文件来进行某些参数设置:
// Private method to configure a ConsoleHandler from LogManager
// properties and/or default values as specified in the class
// javadoc.
private void configure() {
LogManager manager = LogManager.getLogManager();
String cname = getClass().getName();
setLevel(manager.getLevelProperty(cname +".level", Level.INFO));
setFilter(manager.getFilterProperty(cname +".filter", null));
setFormatter(manager.getFormatterProperty(cname +".formatter", new SimpleFormatter()));
try {
setEncoding(manager.getStringProperty(cname +".encoding", null));
} catch (Exception ex) {
try {
setEncoding(null);
} catch (Exception ex2) {
// doing a setEncoding with null should always work.
// assert false;
}
}
}
使用Lombok快速开启日志
我们发现,如果我们现在需要全面使用日志系统,而不是传统的直接打印,那么就需要在每个类都去编写获取Logger的代码,这样显然是很冗余的,能否简化一下这个流程呢?
前面我们学习了Lombok,我们也体会到Lombok给我们带来的便捷,我们可以通过一个注解快速生成构造方法、Getter和Setter,同样的,Logger也是可以使用Lombok快速生成的。
@Log
public class Main {
public static void main(String[] args) {
System.out.println("自动生成的Logger名称:"+log.getName());
log.info("我是日志信息");
}
}
只需要添加一个@Log注解即可,添加后,我们可以直接使用一个静态变量log,而它就是自动生成的Logger。我们也可以手动指定名称:
@Log(topic = "打工是不可能打工的")
public class Main {
public static void main(String[] args) {
System.out.println("自动生成的Logger名称:"+log.getName());
log.info("我是日志信息");
}
}
Mybatis日志系统
Mybatis也有日志系统,它详细记录了所有的数据库操作等,但是我们在前面的学习中没有开启它,现在我们学习了日志之后,我们就可以尝试开启Mybatis的日志系统,来监控所有的数据库操作,要开启日志系统,我们需要进行配置:
<setting name="logImpl" value="STDOUT_LOGGING" />
logImpl包括很多种配置项,包括 SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING,而默认情况下是未配置,也就是说不打印。我们这里将其设定为STDOUT_LOGGING表示直接使用标准输出将日志信息打印到控制台,我们编写一个测试案例来看看效果:
public class TestMain {
private SqlSessionFactory sqlSessionFactory;
@Before
public void before(){
try {
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(new FileInputStream("mybatis-config.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
@Test
public void test(){
try(SqlSession sqlSession = sqlSessionFactory.openSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
System.out.println(mapper.getStudentBySidAndSex(1, "男"));
System.out.println(mapper.getStudentBySidAndSex(1, "男"));
}
}
}
我们发现,两次获取学生信息,只有第一次打开了数据库连接,而第二次并没有。
现在我们学习了日志系统,那么我们来尝试使用日志系统输出Mybatis的日志信息:
<setting name="logImpl" value="JDK_LOGGING" />
将其配置为JDK_LOGGING表示使用JUL进行日志打印,因为Mybatis的日志级别都比较低,因此我们需要设置一下logging.properties默认的日志级别:
handlers= java.util.logging.ConsoleHandler
.level= ALL
java.util.logging.ConsoleHandler.level = ALL
代码编写如下:
@Log
public class TestMain {
private SqlSessionFactory sqlSessionFactory;
@Before
public void before(){
try {
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(new FileInputStream("mybatis-config.xml"));
LogManager manager = LogManager.getLogManager();
manager.readConfiguration(new FileInputStream("logging.properties"));
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void test(){
try(SqlSession sqlSession = sqlSessionFactory.openSession(true)){
TestMapper mapper = sqlSession.getMapper(TestMapper.class);
log.info(mapper.getStudentBySidAndSex(1, "男").toString());
log.info(mapper.getStudentBySidAndSex(1, "男").toString());
}
}
}
但是我们发现,这样的日志信息根本没法看,因此我们需要修改一下日志的打印格式,我们自己创建一个格式化类:
public class TestFormatter extends Formatter {
@Override
public String format(LogRecord record) {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String time = format.format(new Date(record.getMillis())); //格式化日志时间
return time + " : " + record.getMessage() + "\n";
}
}
现在再来修改一下默认的格式化实现:
handlers= java.util.logging.ConsoleHandler
.level= ALL
java.util.logging.ConsoleHandler.level = ALL
java.util.logging.ConsoleHandler.formatter = com.test.TestFormatter
现在就好看多了,当然,我们还可以继续为Mybatis添加文件日志,这里就不做演示了。
Tomcat
https://tomcat.apache.org/download-10.cgi
配置JRE_HOME 环境变量
更改编码:在conf文件夹下,找到logging.properties文件
java.util.logging.ConsoleHandler.encoding = GBK
Tomcat目录
- lib目录:Tomcat服务端运行的一些依赖,不用关心。
- logs目录:所有的日志信息都在这里。
- temp目录:存放运行时产生的一些临时文件,不用关心。
- work目录:工作目录,Tomcat会将jsp文件转换为java文件(我们后面会讲到,这里暂时不提及)
- webapp目录:所有的Web项目都在这里,每个文件夹都是一个Web应用程序:
我们发现,官方已经给我们预设了一些项目了,访问后默认使用的项目为ROOT项目,也就是我们默认打开的网站。
Tomcat还自带管理页面,我们打开:http://localhost:8080/manager,提示需要用户名和密码
conf/tomcat-users.xml
<role rolename="manager-gui"/>
<user username="admin" password="admin" roles="manager-gui"/>
IDEA 创建Web项目

由于Tomcat10以上的版本比较新,Servlet API包名发生了一些变化,因此我们需要修改一下依赖:
<dependency>
<groupId>jakarta.servlet</groupId>
<artifactId>jakarta.servlet-api</artifactId>
<version>5.0.0</version>
<scope>provided</scope>
</dependency>
Servlet
Servlet是JavaWeb最为核心的内容,它是Java提供的一门动态web资源开发技术。
使用Servlet就可以实现,根据不同的登录用户在页面上动态显示不同内容。
Servlet是JavaEE规范之一,其实就是一个接口,将来我们需要定义Servlet类实现Servlet接口,并由web服务器运行Servlet
创建Servlet
实现Servlet类即可,并添加注解@WebServlet来进行注册。
@WebServlet("/test")
public class TestServlet implements Servlet {
...实现接口方法
}
修改tomcat应用名称



除了直接编写一个类,我们也可以在web.xml中进行注册,现将类上@WebServlet的注解去掉:
<servlet>
<servlet-name>test</servlet-name>
<servlet-class>com.example.webtest.TestServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>test</servlet-name>
<url-pattern>/test</url-pattern>
</servlet-mapping>
这样的方式也能注册Servlet,但是显然直接使用注解更加方便,因此之后我们一律使用注解进行开发。只有比较新的版本才支持此注解,老的版本是不支持的
实际上,Tomcat服务器会为我们提供一些默认的Servlet,也就是说在服务器启动后,即使我们什么都不编写,Tomcat也自带了几个默认的Servlet,他们编写在conf目录下的web.xml中:
探究Servlet的生命周期
public class TestServlet implements Servlet {
public TestServlet(){
System.out.println("我是构造方法!");
}
@Override
public void init(ServletConfig servletConfig) throws ServletException {
System.out.println("我是init");
}
@Override
public ServletConfig getServletConfig() {
System.out.println("我是getServletConfig");
return null;
}
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
System.out.println("我是service");
}
@Override
public String getServletInfo() {
System.out.println("我是getServletInfo");
return null;
}
@Override
public void destroy() {
System.out.println("我是destroy");
}
}
我们首先启动一次服务器,然后访问我们定义的页面,然后再关闭服务器,得到如下的顺序:
我是构造方法!
我是init
我是service
我是service(出现两次是因为浏览器请求了2次,是因为有一次是请求favicon.ico,浏览器通病)我是destroy
我们可以多次尝试去访问此页面,但是init和构造方法只会执行一次,而每次访问都会执行的是service方法,因此,一个Servlet的生命周期为:
- 首先执行构造方法完成 Servlet 初始化
- Servlet 初始化后调用 init () 方法。
- Servlet 调用 service() 方法来处理客户端的请求。
- Servlet 销毁前调用 destroy() 方法。
- 最后,Servlet 是由 JVM 的垃圾回收器进行垃圾回收的。
现在我们发现,实际上在Web应用程序运行时,每当浏览器向服务器发起一个请求时,都会创建一个线程执行一次service方法,来让我们处理用户的请求,并将结果响应给用户。
我们发现service方法中,还有两个参数,ServletRequest和ServletResponse,实际上,用户发起的HTTP请求,就被Tomcat服务器封装为了一个ServletRequest对象,我们得到是其实是Tomcat服务器帮助我们创建的一个实现类,HTTP请求报文中的所有内容,都可以从ServletRequest对象中获取,同理,ServletResponse就是我们需要返回给浏览器的HTTP响应报文实体类封装。
那么我们来看看ServletRequest中有哪些内容,我们可以获取请求的一些信息:
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
//首先将其转换为HttpServletRequest(继承自ServletRequest,一般是此接口实现)
HttpServletRequest request = (HttpServletRequest) servletRequest;
System.out.println(request.getProtocol()); //获取协议版本
System.out.println(request.getRemoteAddr()); //获取访问者的IP地址
System.out.println(request.getMethod()); //获取请求方法
//获取头部信息
Enumeration<String> enumeration = request.getHeaderNames();
while (enumeration.hasMoreElements()){
String name = enumeration.nextElement();
System.out.println(name + ": " + request.getHeader(name));
}
}
我们发现,整个HTTP请求报文中的所有内容,都可以通过HttpServletRequest对象来获取,当然,它的作用肯定不仅仅是获取头部信息,我们还可以使用它来完成更多操作,后面会一一讲解。
那么我们再来看看ServletResponse,这个是服务端的响应内容,我们可以在这里填写我们想要发送给浏览器显示的内容:
//转换为HttpServletResponse(同上)
HttpServletResponse response = (HttpServletResponse) servletResponse;
//设定内容类型以及编码格式(普通HTML文本使用text/html,之后会讲解文件传输)
response.setHeader("Content-type", "text/html;charset=UTF-8");
//获取Writer直接写入内容
response.getWriter().write("我是响应内容!");
//所有内容写入完成之后,再发送给浏览器
现在我们在浏览器中打开此页面,就能够收到服务器发来的响应内容了。其中,响应头部分,是由Tomcat帮助我们生成的一个默认响应头。
解读和使用HttpServlet
前面我们已经学习了如何创建、注册和使用Servlet,那么我们继续来深入学习Servlet接口的一些实现类。
首先Servlet有一个直接实现抽象类GenericServlet,那么我们来看看此类做了什么事情。
我们发现,这个类完善了配置文件读取和Servlet信息相关的的操作,但是依然没有去实现service方法,因此此类仅仅是用于完善一个Servlet的基本操作,那么我们接着来看HttpServlet,它是遵循HTTP协议的一种Servlet,继承自GenericServlet,它根据HTTP协议的规则,完善了service方法。
在阅读了HttpServlet源码之后,我们发现,其实我们只需要继承HttpServlet来编写我们的Servlet就可以了,并且它已经帮助我们提前实现了一些操作,这样就会给我们省去很多的时间。
@Log
@WebServlet("/test")
public class TestServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write("<h1>恭喜你解锁了全新玩法</h1>");
}
}
现在,我们只需要重写对应的请求方式,就可以快速完成Servlet的编写。
@WebServlet注解详解
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6pWyIksd-1648965526177)(F:\JavaEE\note\JavaEE\JavaWeb整合\JavaWeb整合.assets\image-20220402202953183.png)]
首先name属性就是Servlet名称,而urlPatterns和value实际上是同样功能,就是代表当前Servlet的访问路径,它不仅仅可以是一个固定值,还可以进行通配符匹配:
@WebServlet("/test/*")
上面的路径表示,所有匹配/test/随便什么的路径名称,都可以访问此Servlet,我们可以在浏览器中尝试一下。
也可以进行某个扩展名称的匹配:
@WebServlet("*.js")
这样的话,获取任何以js结尾的文件,都会由我们自己定义的Servlet处理。
那么如果我们的路径为/呢?
@WebServlet("/")
此路径和Tomcat默认为我们提供的Servlet冲突,会直接替换掉默认的,而使用我们的,此路径的意思为,如果没有找到匹配当前访问路径的Servlet,那么久会使用此Servlet进行处理。
我们还可以为一个Servlet配置多个访问路径:
@WebServlet({"/test1", "/test2"})
我们接着来看loadOnStartup属性,此属性决定了是否在Tomcat启动时就加载此Servlet,默认情况下,Servlet只有在被访问时才会加载,它的默认值为-1,表示不在启动时加载,我们可以将其修改为大于等于0的数,来开启启动时加载。并且数字的大小决定了此Servlet的启动优先级。
@Log
@WebServlet(value = "/test", loadOnStartup = 1)
public class TestServlet extends HttpServlet {
@Override
public void init() throws ServletException {
super.init();
log.info("我被初始化了!");
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write("<h1>恭喜你解锁了全新玩法</h1>");
}
}
使用POST请求完成登陆
我们前面已经了解了如何使用Servlet来处理HTTP请求,那么现在,我们就结合前端,来实现一下登陆操作。
我们需要修改一下我们的Servlet,现在我们要让其能够接收一个POST请求:
@Log
@WebServlet("/login")
public class LoginServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.getParameterMap().forEach((k, v) -> {
System.out.println(k + ": " + Arrays.toString(v));
});
}
}
ParameterMap存储了我们发送的POST请求所携带的表单数据,我们可以直接将其遍历查看,浏览器发送了什么数据。
现在我们再来修改一下前端:
<body>
<h1>登录到系统</h1>
<form method="post" action="login">
<hr>
<div>
<label>
<input type="text" placeholder="用户名" name="username">
</label>
</div>
<div>
<label>
<input type="password" placeholder="密码" name="password">
</label>
</div>
<div>
<button>登录</button>
</div>
</form>
</body>
通过修改form标签的属性,现在我们点击登录按钮,会自动向后台发送一个POST请求,请求地址为当前地址+/login(注意不同路径的写法),也就是我们上面编写的Servlet路径。
运行服务器,测试后发现,在点击按钮后,确实向服务器发起了一个POST请求,并且携带了表单中文本框的数据。
现在,我们根据已有的基础,将其与数据库打通,我们进行一个真正的用户登录操作,首先修改一下Servlet的逻辑:
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//首先设置一下响应类型
resp.setContentType("text/html;charset=UTF-8");
//获取POST请求携带的表单数据
Map<String, String[]> map = req.getParameterMap();
//判断表单是否完整
if(map.containsKey("username") && map.containsKey("password")) {
String username = req.getParameter("username");
String password = req.getParameter("password");
//权限校验(待完善)
}else {
resp.getWriter().write("错误,您的表单数据不完整!");
}
}
连接数据库校验用户登录
接下来我们再去编写Mybatis的依赖和配置文件,创建一个表,用于存放我们用户的账号和密码。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/study"/>
<property name="username" value="root"/>
<property name="password" value="1234"/>
</dataSource>
</environment>
</environments>
</configuration>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
配置完成后,在我们的Servlet的init方法中编写Mybatis初始化代码,因为它只需要初始化一次。
SqlSessionFactory factory;
@SneakyThrows
@Override
public void init() throws ServletException {
factory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader("mybatis-config.xml"));
}
现在我们创建一个实体类以及Mapper来进行用户信息查询:
@Data
public class User {
String username;
String password;
}
public interface UserMapper {
@Select("select * from users where username = #{username} and password = #{password}")
User getUser(@Param("username") String username, @Param("password") String password);
}
<mappers>
<mapper class="com.example.dao.UserMapper"/>
</mappers>
好了,现在完事具备,只欠东风了,我们来完善一下登陆验证逻辑:
//登陆校验(待完善)
try (SqlSession sqlSession = factory.openSession(true)){
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUser(username, password);
//判断用户是否登陆成功,若查询到信息则表示存在此用户
if(user != null){
resp.getWriter().write("登陆成功!");
}else {
resp.getWriter().write("登陆失败,请验证您的用户名或密码!");
}
}
上传和下载文件
首先我们来看看比较简单的下载文件,首先将我们的icon.png放入到resource文件夹中,接着我们编写一个Servlet用于处理文件下载:
@WebServlet("/file")
public class FileServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
resp.setContentType("image/png");
OutputStream outputStream = resp.getOutputStream();
InputStream inputStream = Resources.getResourceAsStream("icon.png");
}
}
为了更加快速地编写IO代码,我们可以引入一个工具库:
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
使用此类库可以快速完成IO操作:
resp.setContentType("image/png");
OutputStream outputStream = resp.getOutputStream();
InputStream inputStream = Resources.getResourceAsStream("icon.png");
//直接使用copy方法完成转换
IOUtils.copy(inputStream, outputStream);
现在我们在前端页面添加一个链接,用于下载此文件:
<hr>
<a href="file" download="icon.png">点我下载高清资源</a>
下载文件搞定,那么如何上传一个文件呢?
首先我们编写前端部分:
<form method="post" action="file" enctype="multipart/form-data">
<div>
<input type="file" name="test-file">
</div>
<div>
<button>上传文件</button>
</div>
</form>
注意必须添加enctype="multipart/form-data",来表示此表单用于文件传输。
现在我们来修改一下Servlet代码:
@MultipartConfig
@WebServlet("/file")
public class FileServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
try(FileOutputStream stream = new FileOutputStream("/Users/nagocoler/Documents/IdeaProjects/WebTest/test.png")){
Part part = req.getPart("test-file");
IOUtils.copy(part.getInputStream(), stream);
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write("文件上传成功!");
}
}
}
注意,必须添加@MultipartConfig注解来表示此Servlet用于处理文件上传请求。
现在我们再运行服务器,并将我们刚才下载的文件又上传给服务端。
使用XHR请求数据
现在我们希望,网页中的部分内容,可以动态显示,比如网页上有一个时间,旁边有一个按钮,点击按钮就可以刷新当前时间。
这个时候就需要我们在网页展示时向后端发起请求了,并根据后端响应的结果,动态地更新页面中的内容,要实现此功能,就需要用到JavaScript来帮助我们,首先在js中编写我们的XHR请求,并在请求中完成动态更新:
function updateTime() {
let xhr = new XMLHttpRequest();
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
document.getElementById("time").innerText = xhr.responseText
}
};
xhr.open('GET', 'time', true);
xhr.send();
}
接着修改一下前端页面,添加一个时间显示区域:
<hr>
<div id="time"></div>
<br>
<button onclick="updateTime()">更新数据</button>
<script>
updateTime()
</script>
最后创建一个Servlet用于处理时间更新请求:
@WebServlet("/time")
public class TimeServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
String date = dateFormat.format(new Date());
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write(date);
}
}
现在点击按钮就可以更新了。
重定向与请求转发
当我们希望用户登录完成之后,直接跳转到网站的首页,那么这个时候,我们就可以使用重定向来完成。当浏览器收到一个重定向的响应时,会按照重定向响应给出的地址,再次向此地址发出请求。
实现重定向很简单,只需要调用一个方法即可,我们修改一下登陆成功后执行的代码:
resp.sendRedirect("time");
调用后,响应的状态码会被设置为302,并且响应头中添加了一个Location属性,此属性表示,需要重定向到哪一个网址。
现在,如果我们成功登陆,那么服务器会发送给我们一个重定向响应,这时,我们的浏览器会去重新请求另一个网址。这样,我们在登陆成功之后,就可以直接帮助用户跳转到用户首页了。
那么我们接着来看请求转发,请求转发其实是一种服务器内部的跳转机制,我们知道,重定向会使得浏览器去重新请求一个页面,而请求转发则是服务器内部进行跳转,它的目的是,直接将本次请求转发给其他Servlet进行处理,并由其他Servlet来返回结果,因此它是在进行内部的转发。
req.getRequestDispatcher("/time").forward(req, resp);
现在,在登陆成功的时候,我们将请求转发给处理时间的Servlet,注意这里的路径规则和之前的不同,我们需要填写Servlet上指明的路径,并且请求转发只能转发到此应用程序内部的Servlet,不能转发给其他站点或是其他Web应用程序。
现在再次进行登陆操作,我们发现,返回结果为一个405页面,证明了,我们的请求现在是被另一个Servlet进行处理,并且请求的信息全部被转交给另一个Servlet,由于此Servlet不支持POST请求,因此返回405状态码。
那么也就是说,该请求包括请求参数也一起被传递了,那么我们可以尝试获取以下POST请求的参数。
现在我们给此Servlet添加POST请求处理,直接转交给Get请求处理:
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
this.doGet(req, resp);
}
再次访问,成功得到结果,但是我们发现,浏览器只发起了一次请求,并没有再次请求新的URL,也就是说,这一次请求直接返回了请求转发后的处理结果。
那么,请求转发有什么好处呢?它可以携带数据!
req.setAttribute("user", user);
req.getRequestDispatcher("/time").forward(req, resp);
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
User user = (User) req.getAttribute("user");
resp.setContentType("text/html;charset=UTF-8");
resp.getWriter().write(user.getUsername() + "登录成功");
}
通过setAttribute方法来给当前请求添加一个附加数据,在请求转发后,我们可以直接获取到该数据。
重定向属于2次请求,因此无法使用这种方式来传递数据,那么,如何在重定向之间传递数据呢?我们可以使用即将要介绍的ServletContext对象。
最后总结,两者的区别为:
- 请求转发是一次请求,重定向是两次请求
- 请求转发地址栏不会发生改变, 重定向地址栏会发生改变
- 请求转发可以共享请求参数 ,重定向之后,就获取不了共享参数了
- 请求转发只能转发给内部的Servlet
了解ServletContext对象
ServletContext全局唯一,它是属于整个Web应用程序的,我们可以通过getServletContext()来获取到此对象。
此对象也能设置附加值:
ServletContext context = getServletContext();
context.setAttribute("test", "我是重定向之前的数据");
resp.sendRedirect("time");
System.out.println(getServletContext().getAttribute("test"));
因为无论在哪里,无论什么时间,获取到的ServletContext始终是同一个对象,因此我们可以随时随地获取我们添加的属性。
它不仅仅可以用来进行数据传递,还可以做一些其他的事情,比如请求转发:
context.getRequestDispatcher("/time").forward(req, resp);
获取文件
System.out.println(IOUtils.toString(context.getResourceAsStream("index.html"),StandardCharsets.UTF_8););
它还可以获取根目录下的资源文件(注意是webapp根目录下的,不是resource中的资源)
初始化参数
初始化参数类似于初始化配置需要的一些值,比如我们的数据库连接相关信息,就可以通过初始化参数来给予Servlet,或是一些其他的配置项,也可以使用初始化参数来实现。
我们可以给一个Servlet添加一些初始化参数:
@WebServlet(value = "/login", initParams = {
@WebInitParam(name = "test", value = "我是一个默认的初始化参数")
})
它也是以键值对形式保存的,我们可以直接通过Servlet的getInitParameter方法获取:
System.out.println(getInitParameter("test"));
但是,这里的初始化参数仅仅是针对于此Servlet,我们也可以定义全局初始化参数,只需要在web.xml编写即可:
<context-param>
<param-name>lbwnb</param-name>
<param-value>我是全局初始化参数</param-value>
</context-param>
我们需要使用ServletContext来读取全局初始化参数:
ServletContext context = getServletContext();
System.out.println(context.getInitParameter("lbwnb"));
有关ServletContext其他的内容,我们需要完成后面内容的学习,才能理解。
会话
Cookie
什么是Cookie?它可以在浏览器中保存一些信息,并且在下次请求时,请求头中会携带这些信息。
我们可以编写一个测试用例来看看:
Cookie cookie = new Cookie("test", "yyds");
resp.addCookie(cookie);
resp.sendRedirect("time");
if (req.getCookies() != null) {
for (Cookie cookie : req.getCookies()) {
System.out.println(cookie.getName() + ": " + cookie.getValue());
}
}
我们可以观察一下,在HttpServletResponse中添加Cookie之后,浏览器的响应头中会包含一个Set-Cookie属性,同时,在重定向之后,我们的请求头中,会携带此Cookie作为一个属性,同时,我们可以直接通过HttpServletRequest来快速获取有哪些Cookie信息。
一个Cookie包含哪些信息:
- name - Cookie的名称,Cookie一旦创建,名称便不可更改
- value - Cookie的值,如果值为Unicode字符,需要为字符编码。如果为二进制数据,则需要使用BASE64编码
- maxAge - Cookie失效的时间,单位秒。如果为正数,则该Cookie在maxAge秒后失效。如果为负数,该Cookie为临时Cookie,关闭浏览器即失效,浏览器也不会以任何形式保存该Cookie。如果为0,表示删除该Cookie。默认为-1。
- secure - 该Cookie是否仅被使用安全协议传输。安全协议。安全协议有HTTPS,SSL等,在网络上传输数据之前先将数据加密。默认为false。
- path - Cookie的使用路径。如果设置为“/sessionWeb/”,则只有contextPath为“/sessionWeb”的程序可以访问该Cookie。如果设置为“/”,则本域名下contextPath都可以访问该Cookie。注意最后一个字符必须为“/”。
- domain - 可以访问该Cookie的域名。如果设置为“.google.com”,则所有以“google.com”结尾的域名都可以访问该Cookie。注意第一个字符必须为“
.”。 - comment - 该Cookie的用处说明,浏览器显示Cookie信息的时候显示该说明。
- version - Cookie使用的版本号。0表示遵循Netscape的Cookie规范,1表示遵循W3C的RFC 2109规范
我们发现,最关键的其实是name、value、maxAge、domain属性。
那么我们来尝试修改一下maxAge来看看失效时间:
cookie.setMaxAge(20);
设定为20秒,我们可以直接看到,响应头为我们设定了20秒的过期时间。20秒内访问都会携带此Cookie,而超过20秒,Cookie消失。
既然了解了Cookie的作用,我们就可以通过使用Cookie来实现记住我功能,我们可以将用户名和密码全部保存在Cookie中,如果访问我们的首页时携带了这些Cookie,那么我们就可以直接为用户进行登陆,如果登陆成功则直接跳转到首页,如果登陆失败,则清理浏览器中的Cookie。
那么首先,我们先在前端页面的表单中添加一个勾选框:
<div>
<label>
<input type="checkbox" placeholder="记住我" name="remember-me">
记住我
</label>
</div>
接着,我们在登陆成功时进行判断,如果用户勾选了记住我,那么就讲Cookie存储到本地:
if(map.containsKey("remember-me")){ //若勾选了勾选框,那么会此表单信息
Cookie cookie_username = new Cookie("username", username);
cookie_username.setMaxAge(30);
Cookie cookie_password = new Cookie("password", password);
cookie_password.setMaxAge(30);
resp.addCookie(cookie_username);
resp.addCookie(cookie_password);
}
然后,我们修改一下默认的请求地址,现在一律通过http://localhost:8080/yyds/login进行登陆,那么我们需要添加GET请求的相关处理:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Cookie[] cookies = req.getCookies();
if(cookies != null){
String username = null;
String password = null;
for (Cookie cookie : cookies) {
if(cookie.getName().equals("username")) username = cookie.getValue();
if(cookie.getName().equals("password")) password = cookie.getValue();
}
if(username != null && password != null){
//登陆校验
try (SqlSession sqlSession = factory.openSession(true)){
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUser(username, password);
if(user != null){
resp.sendRedirect("time");
return; //直接返回
}
}
}
}
req.getRequestDispatcher("/").forward(req, resp); //正常情况还是转发给默认的Servlet帮我们返回静态页面
}
现在,30秒内都不需要登陆,访问登陆页面后,会直接跳转到time页面。
现在已经离我们理想的页面越来越接近了,但是仍然有一个问题,就是我们的首页,无论是否登陆,所有人都可以访问,那么,如何才可以实现只有登陆之后才能访问呢?这就需要用到Session了。
Session
由于HTTP是无连接的,那么如何能够辨别当前的请求是来自哪个用户发起的呢?Session就是用来处理这种问题的,每个用户的会话都会有一个自己的Session对象,来自同一个浏览器的所有请求,就属于同一个会话。
但是HTTP协议是无连接的呀,那Session是如何做到辨别是否来自同一个浏览器呢?Session实际上是基于Cookie实现的,前面我们了解了Cookie,我们知道,服务端可以将Cookie保存到浏览器,当浏览器下次访问时,就会附带这些Cookie信息。
Session也利用了这一点,它会给浏览器设定一个叫做JSESSIONID的Cookie,值是一个随机的排列组合,而此Cookie就对应了你属于哪一个对话,只要我们的浏览器携带此Cookie访问服务器,服务器就会通过Cookie的值进行辨别,得到对应的Session对象,因此,这样就可以追踪到底是哪一个浏览器在访问服务器。

那么现在,我们在用户登录成功之后,将用户对象添加到Session中,只要是此用户发起的请求,我们都可以从HttpSession中读取到存储在会话中的数据:
HttpSession session = req.getSession();
session.setAttribute("user", user);
同时,如果用户没有登录就去访问首页,那么我们将发送一个重定向请求,告诉用户,需要先进行登录才可以访问:
HttpSession session = req.getSession();
User user = (User) session.getAttribute("user");
if(user == null) {
resp.sendRedirect("login");
return;
}
在访问的过程中,注意观察Cookie变化。
Session并不是永远都存在的,它有着自己的过期时间,默认时间为30分钟,若超过此时间,Session将丢失,我们可以在配置文件中修改过期时间:
<session-config>
<session-timeout>1</session-timeout>
</session-config>
我们也可以在代码中使用invalidate方法来使Session立即失效:
session.invalidate();
现在,通过Session,我们就可以更好地控制用户对于资源的访问,只有完成登陆的用户才有资格访问首页。
Filter
有了Session之后,我们就可以很好地控制用户的登陆验证了,只有授权的用户,才可以访问一些页面,但是我们需要一个一个去进行配置,还是太过复杂,能否一次性地过滤掉没有登录验证的用户呢?
过滤器相当于在所有访问前加了一堵墙,来自浏览器的所有访问请求都会首先经过过滤器,只有过滤器允许通过的请求,才可以顺利地到达对应的Servlet,而过滤器不允许的通过的请求,我们可以自由地进行控制是否进行重定向或是请求转发。并且过滤器可以添加很多个,就相当于添加了很多堵墙,我们的请求只有穿过层层阻碍,才能与Servlet相拥,像极了爱情。

添加一个过滤器非常简单,只需要实现Filter接口,并添加@WebFilter注解即可:
@WebFilter("/*") //路径的匹配规则和Servlet一致,这里表示匹配所有请求
public class TestFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
}
}
这样我们就成功地添加了一个过滤器,那么添加一句打印语句看看,是否所有的请求都会经过此过滤器:
HttpServletRequest request = (HttpServletRequest) servletRequest;
System.out.println(request.getRequestURL());
我们发现,现在我们发起的所有请求,一律需要经过此过滤器,并且所有的请求都没有任何的响应内容。
那么如何让请求可以顺利地到达对应的Servlet,也就是说怎么让这个请求顺利通过呢?我们只需要在最后添加一句:
filterChain.doFilter(servletRequest, servletResponse);
那么这行代码是什么意思呢?
由于我们整个应用程序可能存在多个过滤器,那么这行代码的意思实际上是将此请求继续传递给下一个过滤器,当没有下一个过滤器时,才会到达对应的Servlet进行处理,我们可以再来创建一个过滤器看看效果:
@WebFilter("/*")
public class TestFilter2 implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("我是2号过滤器");
filterChain.doFilter(servletRequest, servletResponse);
}
}
由于过滤器的过滤顺序是按照类名的自然排序进行的,因此我们将第一个过滤器命名进行调整。
我们发现,在经过第一个过滤器之后,会继续前往第二个过滤器,只有两个过滤器全部经过之后,才会到达我们的Servlet中。

实际上,当doFilter方法调用时,就会一直向下直到Servlet,在Servlet处理完成之后,又依次返回到最前面的Filter,类似于递归的结构,我们添加几个输出语句来判断一下:
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("我是2号过滤器");
filterChain.doFilter(servletRequest, servletResponse);
System.out.println("我是2号过滤器,处理后");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("我是1号过滤器");
filterChain.doFilter(servletRequest, servletResponse);
System.out.println("我是1号过滤器,处理后");
}
最后验证我们的结论。
同Servlet一样,Filter也有对应的HttpFilter专用类,它针对HTTP请求进行了专门处理,因此我们可以直接使用HttpFilter来编写:
public abstract class HttpFilter extends GenericFilter {
private static final long serialVersionUID = 7478463438252262094L;
public HttpFilter() {
}
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException {
if (req instanceof HttpServletRequest && res instanceof HttpServletResponse) {
this.doFilter((HttpServletRequest)req, (HttpServletResponse)res, chain);
} else {
throw new ServletException("non-HTTP request or response");
}
}
protected void doFilter(HttpServletRequest req, HttpServletResponse res, FilterChain chain) throws IOException, ServletException {
chain.doFilter(req, res);
}
}
那么现在,我们就可以给我们的应用程序添加一个过滤器,用户在未登录情况下,只允许静态资源和登陆页面请求通过,登陆之后畅行无阻:
@WebFilter("/*")
public class MainFilter extends HttpFilter {
@Override
protected void doFilter(HttpServletRequest req, HttpServletResponse res, FilterChain chain) throws IOException, ServletException {
String url = req.getRequestURL().toString();
//判断是否为静态资源
if(!url.endsWith(".js") && !url.endsWith(".css") && !url.endsWith(".png")){
HttpSession session = req.getSession();
User user = (User) session.getAttribute("user");
//判断是否未登陆
if(user == null && !url.endsWith("login")){
res.sendRedirect("login");
return;
}
}
//交给过滤链处理
chain.doFilter(req, res);
}
}
现在,我们的页面已经基本完善为我们想要的样子了。
当然,可能跟着教程编写的项目比较乱,大家可以自己花费一点时间来重新编写一个Web应用程序,加深对之前讲解知识的理解。我们也会在之后安排一个编程实战进行深化练习。
Listener
监听器并不是我们学习的重点内容,那么什么是监听器呢?
如果我们希望,在应用程序加载的时候,或是Session创建的时候,亦或是在Request对象创建的时候进行一些操作,那么这个时候,我们就可以使用监听器来实现。

默认为我们提供了很多类型的监听器,我们这里就演示一下监听Session的创建即可:
@WebListener
public class TestListener implements HttpSessionListener {
@Override
public void sessionCreated(HttpSessionEvent se) {
System.out.println("有一个Session被创建了");
}
}
有关监听器相关内容,了解即可。
使用Thymeleaf模板引擎
虽然JSP为我们带来了便捷,但是其缺点也是显而易见的,那么有没有一种既能实现模板,又能兼顾前后端分离的模板引擎呢?
Thymeleaf(百里香叶)是一个适用于Web和独立环境的现代化服务器端Java模板引擎,官方文档:https://www.thymeleaf.org/documentation.html。
那么它和JSP相比,好在哪里呢,我们来看官网给出的例子:
<table>
<thead>
<tr>
<th th:text="#{msgs.headers.name}">Name</th>
<th th:text="#{msgs.headers.price}">Price</th>
</tr>
</thead>
<tbody>
<tr th:each="prod: ${allProducts}">
<td th:text="${prod.name}">Oranges</td>
<td th:text="${#numbers.formatDecimal(prod.price, 1, 2)}">0.99</td>
</tr>
</tbody>
</table>
我们可以在前端页面中填写占位符,而这些占位符的实际值则由后端进行提供,这样,我们就不用再像JSP那样前后端都写在一起了。
那么我们来创建一个例子感受一下,首先还是新建一个项目,注意,在创建时,勾选Thymeleaf依赖。
首先编写一个前端页面,名称为test.html,注意,是放在resource目录下,在html标签内部添加xmlns:th="http://www.thymeleaf.org"引入Thymeleaf定义的标签属性:
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div th:text="${title}"></div>
</body>
</html>
接着我们编写一个Servlet作为默认页面:
@WebServlet("/index")
public class HelloServlet extends HttpServlet {
TemplateEngine engine;
@Override
public void init() throws ServletException {
engine = new TemplateEngine();
ClassLoaderTemplateResolver r = new ClassLoaderTemplateResolver();
engine.setTemplateResolver(r);
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
context.setVariable("title", "我是标题");
engine.process("test.html", context, resp.getWriter());
}
}
我们发现,浏览器得到的页面,就是已经经过模板引擎解析好的页面,而我们的代码依然是后端处理数据,前端展示数据,因此使用Thymeleaf就能够使得当前Web应用程序的前后端划分更加清晰。
虽然Thymeleaf在一定程度上分离了前后端,但是其依然是在后台渲染HTML页面并发送给前端,并不是真正意义上的前后端分离。
Thymeleaf语法基础
那么,如何使用Thymeleaf呢?
首先我们看看后端部分,我们需要通过TemplateEngine对象来将模板文件渲染为最终的HTML页面:
TemplateEngine engine;
@Override
public void init() throws ServletException {
engine = new TemplateEngine();
//设定模板解析器决定了从哪里获取模板文件,这里直接使用ClassLoaderTemplateResolver表示加载内部资源文件
ClassLoaderTemplateResolver r = new ClassLoaderTemplateResolver();
engine.setTemplateResolver(r);
}
由于此对象只需要创建一次,之后就可以一直使用了。接着我们来看如何使用模板引擎进行解析:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//创建上下文,上下文中包含了所有需要替换到模板中的内容
Context context = new Context();
context.setVariable("title", "<h1>我是标题</h1>");
//通过此方法就可以直接解析模板并返回响应
engine.process("test.html", context, resp.getWriter());
}
操作非常简单,只需要简单几步配置就可以实现模板的解析。接下来我们就可以在前端页面中通过上下文提供的内容,来将Java代码中的数据解析到前端页面。
接着我们来了解Thymeleaf如何为普通的标签添加内容,比如我们示例中编写的:
<div th:text="${title}"></div>
我们使用了th:text来为当前标签指定内部文本,注意任何内容都会变成普通文本,即使传入了一个HTML代码,如果我希望向内部添加一个HTML文本呢?我们可以使用th:utext属性:
<div th:utext="${title}"></div>
并且,传入的title属性,不仅仅只是一个字符串的值,而是一个字符串的引用,我们可以直接通过此引用调用相关的方法:
<div th:text="${title.toLowerCase()}"></div>
这样看来,Thymeleaf既能保持JSP为我们带来的便捷,也能兼顾前后端代码的界限划分。
除了替换文本,它还支持替换一个元素的任意属性,我们发现,th:能够拼接几乎所有的属性,一旦使用th:属性名称,那么属性的值就可以通过后端提供了,比如我们现在想替换一个图片的链接:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
context.setVariable("url", "http://n.sinaimg.cn/sinakd20121/600/w1920h1080/20210727/a700-adf8480ff24057e04527bdfea789e788.jpg");
context.setVariable("alt", "图片就是加载不出来啊");
engine.process("test.html", context, resp.getWriter());
}
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<img width="700" th:src="${url}" th:alt="${alt}">
</body>
</html>
现在访问我们的页面,就可以看到替换后的结果了。
Thymeleaf还可以进行一些算术运算,几乎Java中的运算它都可以支持:
<div th:text="${value % 2}"></div>
同样的,它还支持三元运算:
<div th:text="${value % 2 == 0 ? 'yyds' : 'lbwnb'}"></div>
多个属性也可以通过+进行拼接,就像Java中的字符串拼接一样,这里要注意一下,字符串不能直接写,要添加单引号:
<div th:text="${name}+' 我是文本 '+${value}"></div>
Thymeleaf流程控制语法
除了一些基本的操作,我们还可以使用Thymeleaf来处理流程控制语句,当然,不是直接编写Java代码的形式,而是添加一个属性即可。
首先我们来看if判断语句,如果if条件满足,则此标签留下,若if条件不满足,则此标签自动被移除:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
context.setVariable("eval", true);
engine.process("test.html", context, resp.getWriter());
}
<div th:if="${eval}">我是判断条件标签</div>
th:if会根据其中传入的值或是条件表达式的结果进行判断,只有满足的情况下,才会显示此标签,具体的判断规则如下:
- 如果值不是空的:
- 如果值是布尔值并且为
true。 - 如果值是一个数字,并且是非零
- 如果值是一个字符,并且是非零
- 如果值是一个字符串,而不是“错误”、“关闭”或“否”
- 如果值不是布尔值、数字、字符或字符串。
- 如果值是布尔值并且为
- 如果值为空,th:if将计算为false
th:if还有一个相反的属性th:unless,效果完全相反,这里就不演示了。
我们接着来看多分支条件判断,我们可以使用th:switch属性来实现:
<div th:switch="${eval}">
<div th:case="1">我是1</div>
<div th:case="2">我是2</div>
<div th:case="3">我是3</div>
</div>
只不过没有default属性,但是我们可以使用th:case="*"来代替:
<div th:case="*">我是Default</div>
最后我们再来看看,它如何实现遍历,假如我们有一个存放书籍信息的List需要显示,那么如何快速生成一个列表呢?我们可以使用th:each来进行遍历操作:
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
context.setVariable("list", Arrays.asList("伞兵一号的故事", "倒一杯卡布奇诺", "玩游戏要啸着玩", "十七张牌前的电脑屏幕"));
engine.process("test.html", context, resp.getWriter());
}
<ul>
<li th:each="title : ${list}" th:text="'《'+${title}+'》'"></li>
</ul>
th:each中需要填写 “单个元素名称 : ${列表}”,这样,所有的列表项都可以使用遍历的单个元素,只要使用了th:each,都会被循环添加。因此最后生成的结果为:
<ul>
<li>《伞兵一号的故事》</li>
<li>《倒一杯卡布奇诺》</li>
<li>《玩游戏要啸着玩》</li>
<li>《十七张牌前的电脑屏幕》</li>
</ul>
我们还可以获取当前循环的迭代状态,只需要在最后添加iterStat即可,从中可以获取很多信息,比如当前的顺序:
<ul>
<li th:each="title, iterStat : ${list}" th:text="${iterStat.index}+'.《'+${title}+'》'"></li>
</ul>
状态变量在th:each属性中定义,并包含以下数据:
- 当前迭代索引,以0开头。这是
index属性。 - 当前迭代索引,以1开头。这是
count属性。 - 迭代变量中的元素总量。这是
size属性。 - 每个迭代的迭代变量。这是
current属性。 - 当前迭代是偶数还是奇数。这些是
even/odd布尔属性。 - 当前迭代是否是第一个迭代。这是
first布尔属性。 - 当前迭代是否是最后一个迭代。这是
last布尔属性。
通过了解了流程控制语法,现在我们就可以很轻松地使用Thymeleaf来快速替换页面中的内容了。
Thymeleaf模板布局
在某些网页中,我们会发现,整个网站的页面,除了中间部分的内容会随着我们的页面跳转而变化外,有些部分是一直保持一个状态的,比如打开小破站,我们翻动评论或是切换视频分P的时候,变化的仅仅是对应区域的内容,实际上,其他地方的内容会无论内部页面如何跳转,都不会改变。
Thymeleaf就可以轻松实现这样的操作,我们只需要将不会改变的地方设定为模板布局,并在不同的页面中插入这些模板布局,就无需每个页面都去编写同样的内容了。现在我们来创建两个页面:
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div class="head">
<div>
<h1>我是标题内容,每个页面都有</h1>
</div>
<hr>
</div>
<div class="body">
<ul>
<li th:each="title, iterStat : ${list}" th:text="${iterStat.index}+'.《'+${title}+'》'"></li>
</ul>
</div>
</body>
</html>
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div class="head">
<div>
<h1>我是标题内容,每个页面都有</h1>
</div>
<hr>
</div>
<div class="body">
<div>这个页面的样子是这样的</div>
</div>
</body>
</html>
接着将模板引擎写成工具类的形式:
public class ThymeleafUtil {
private static final TemplateEngine engine;
static {
engine = new TemplateEngine();
ClassLoaderTemplateResolver r = new ClassLoaderTemplateResolver();
engine.setTemplateResolver(r);
}
public static TemplateEngine getEngine() {
return engine;
}
}
@WebServlet("/index2")
public class HelloServlet2 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Context context = new Context();
ThymeleafUtil.getEngine().process("test2.html", context, resp.getWriter());
}
}
现在就有两个Servlet分别对应两个页面了,但是这两个页面实际上是存在重复内容的,我们要做的就是将这些重复内容提取出来。
我们单独编写一个head.html来存放重复部分:
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org" lang="en">
<body>
<div class="head" th:fragment="head-title">
<div>
<h1>我是标题内容,每个页面都有</h1>
</div>
<hr>
</div>
</body>
</html>
现在,我们就可以直接将页面中的内容快速替换:
<div th:include="head.html::head-title"></div>
<div class="body">
<ul>
<li th:each="title, iterStat : ${list}" th:text="${iterStat.index}+'.《'+${title}+'》'"></li>
</ul>
</div>
我们可以使用th:insert和th:replace和th:include这三种方法来进行页面内容替换,那么th:insert和th:replace(和th:include,自3.0年以来不推荐)有什么区别?
th:insert最简单:它只会插入指定的片段作为标签的主体。th:replace实际上将标签直接替换为指定的片段。th:include和th:insert相似,但它没有插入片段,而是只插入此片段的内容。
你以为这样就完了吗?它还支持参数传递,比如我们现在希望插入二级标题,并且由我们的子页面决定:
<div class="head" th:fragment="head-title">
<div>
<h1>我是标题内容,每个页面都有</h1>
<h2>我是二级标题</h2>
</div>
<hr>
</div>
稍加修改,就像JS那样添加一个参数名称:
<div class="head" th:fragment="head-title(sub)">
<div>
<h1>我是标题内容,每个页面都有</h1>
<h2 th:text="${sub}"></h2>
</div>
<hr>
</div>
现在直接在替换位置添加一个参数即可:
<div th:include="head.html::head-title('这个是第1个页面的二级标题')"></div>
<div class="body">
<ul>
<li th:each="title, iterStat : ${list}" th:text="${iterStat.index}+'.《'+${title}+'》'"></li>
</ul>
</div>
这样,不同的页面还有着各自的二级标题。
探讨Tomcat类加载机制
有关JavaWeb的内容,我们就聊到这里,在最后,我们还是来看一下Tomcat到底是如何加载和运行我们的Web应用程序的。
Tomcat服务器既然要同时运行多个Web应用程序,那么就必须要实现不同应用程序之间的隔离,也就是说,Tomcat需要分别去加载不同应用程序的类以及依赖,还必须保证应用程序之间的类无法相互访问,而传统的类加载机制无法做到这一点,同时每个应用程序都有自己的依赖,如果两个应用程序使用了同一个版本的同一个依赖,那么还有必要去重新加载吗,带着诸多问题,Tomcat服务器编写了一套自己的类加载机制。

首先我们要知道,Tomcat本身也是一个Java程序,它要做的是去动态加载我们编写的Web应用程序中的类,而要解决以上提到的一些问题,就出现了几个新的类加载器,我们来看看各个加载器的不同之处:
- Common ClassLoader:Tomcat最基本的类加载器,加载路径中的class可以被Tomcat容器本身以及各个Web应用程序访问。
- Catalina ClassLoader:Tomcat容器私有的类加载器,加载路径中的class对于Web应用程序不可见。
- Shared ClassLoader:各个Web应用程序共享的类加载器,加载路径中的class对于所有Web应用程序可见,但是对于Tomcat容器不可见。
- Webapp ClassLoader:各个Web应用程序私有的类加载器,加载路径中的class只对当前Web应用程序可见,每个Web应用程序都有一个自己的类加载器,此加载器可能存在多个实例。
- JasperLoader:JSP类加载器,每个JSP文件都有一个自己的类加载器,也就是说,此加载器可能会存在多个实例。
通过这样进行划分,就很好地解决了我们上面所提到的问题,但是我们发现,这样的类加载机制,破坏了JDK的双亲委派机制(在JavaSE阶段讲解过),比如Webapp ClassLoader,它只加载自己的class文件,它没有将类交给父类加载器进行加载,也就是说,我们可以随意创建和JDK同包同名的类,岂不是就出问题了?
难道Tomcat的开发团队没有考虑到这个问题吗?
实际上,WebAppClassLoader的加载机制是这样的:WebAppClassLoader 加载类的时候,绕开了 AppClassLoader,直接先使用 ExtClassLoader 来加载类。这样的话,如果定义了同包同名的类,就不会被加载,而如果是自己定义 的类,由于该类并不是JDK内部或是扩展类,所有不会被加载,而是再次回到WebAppClassLoader进行加载,如果还失败,再使用AppClassloader进行加载。
















 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









