







目录
前言
在一次程序测试中,无意中发现 导出Excel时,如果数据超过65536条之后会报错,因此我改为使用NPOI提供的XSSFWorkbook 用来导出超过限制数量的数据,但随之而来的问题是,我遇到了另一个问题当数据量超8万条之后,提示找不到类型或命名空间名称"SXSSFWorkbook"(是否缺少using指令或程序集引I用?),发现内存溢出,因此在网上遨游了一番,得出如下内容,以便后续翻看,同时提供给遇到这类问题的朋友参考!
一、NPOI的基本知识
碰到了导出大量数据的需求场景:从数据读取数据大约50W,然后再前端导出给用户,整个过程希望能较快的完成。如果不能较快完成,可以给与友好的提示。
大量数据的导出耗时的主要地方:
1、从数据库获取大量数据。如果一般百万级别左右的,走索引的查询,一般5秒左右可以把数据查出来。
2、把查出来的数据,通过NPOI组装成excel。这个过程一般耗时,且消耗资源,很容易出现OOM。
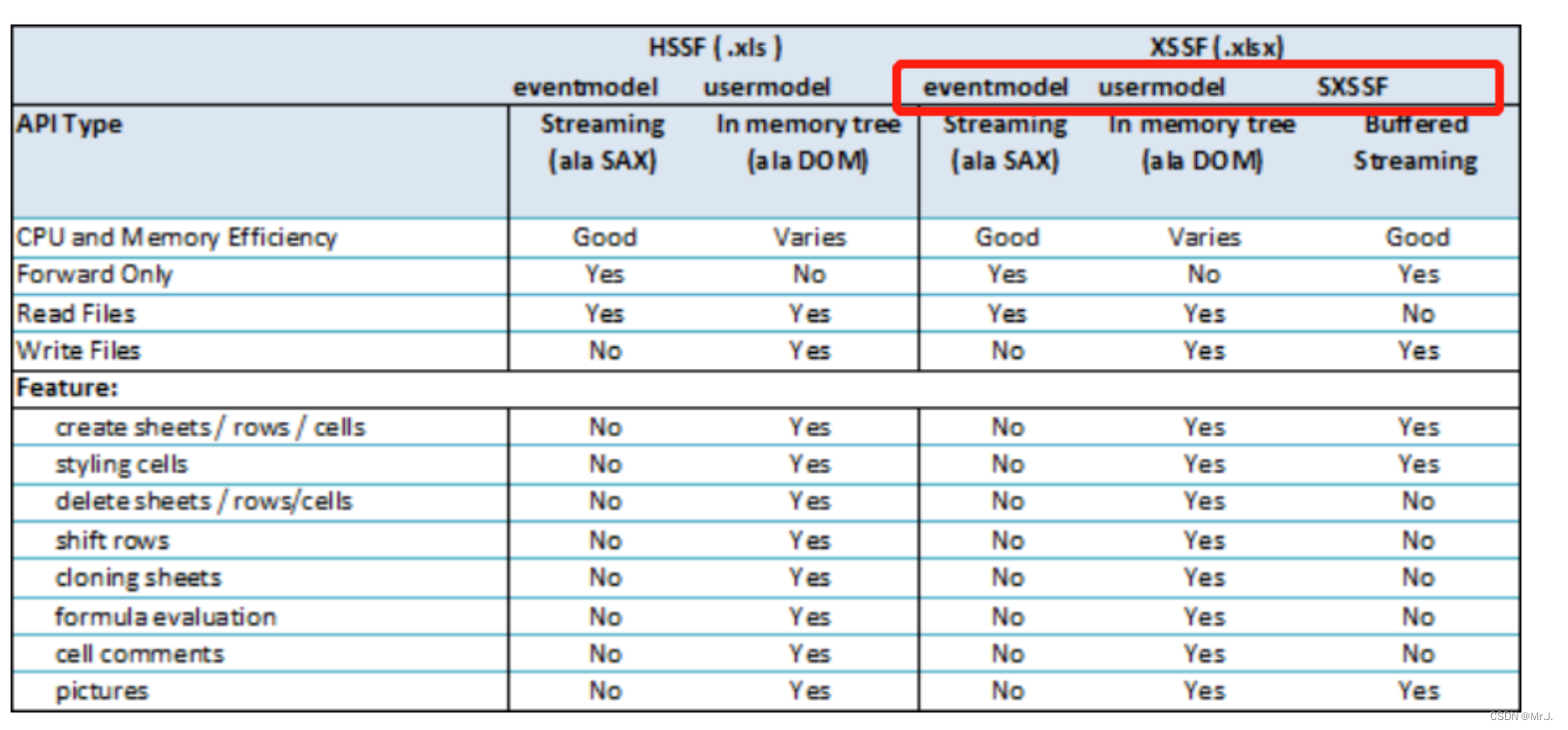
了解一下NPOI基本知识,因为NPOI是从JAVA的POI的.NET版本,所以可以看看POI的信息也是类的
1、基于事件模式的操作(eventmodel)
2、基于用户态模式的操作(usermodel)
3、基于SXSSF的操作(SXSSF)
二、基于XSSFWorkbook进行导出
01、因为是大数量毫不疑问的只能选择XSSFWorkbook,导出xlsx格式(07版及以上)
这里有一个坑点就是: wb.Write(ms);写完之后会关闭,所以一般扩展一个自定义流来代替内存流来实现
public static byte[] Export<T>(List<T> list, string filename)
{
IWorkbook wb = new XSSFWorkbook();
ISheet sheet = wb.CreateSheet(filename);
SetColumnTitle<T>(sheet, list[0]);
int index = 1;
foreach (var model in list)
{
Type type = model.GetType();
var properties = type.GetProperties();
IRow row = sheet.CreateRow(index++);
int j = 0;
for (int i = 0; i < properties.Length; i++)
{
var p = properties[i];
object[] objs = p.GetCustomAttributes(typeof(ExcelAttribute), true);
if (objs.Length > 0)
{
object obj = p.GetValue(model, null);
if (obj != null)
{
row.CreateCell(j).SetCellValue(obj.ToString());
}
else
{
row.CreateCell(j).SetCellValue("");
}
j++;
}
}
}
byte[] buffer;
using (NpoiMemoryStream ms = new NpoiMemoryStream())
{
ms.AllowClose = false;
wb.Write(ms);
ms.Flush();
buffer = new byte[ms.Length];
ms.Position = 0;
ms.Read(buffer, 0, buffer.Length);
ms.AllowClose = true;
}
wb.Close();
//强制清空占用内存,因为NPOI占用的内存,不建议手动GC。
//GcCollectHelper.ClearMemory();
return buffer;
}
并且导出完,占用的内存还一直没释放【这是和.NET 的GC机制有关,不是说使用完内存会马上释放,如果这样内存的利用率就100%了】。
用上面这种方法导出数据,很有可能导致OOM,因为在你点导出的时候,占用的内存和CPU都很高。
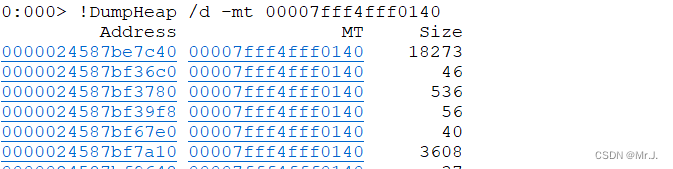
02、通过Windbg分析Dump得到下面:
1、通过!dumpheap -stat 查看clr的托管堆中的各个类型的占用情况。
 发现有下面这些对象占用了很大的内存,逐个分析,看看是我们代码的锅,还是NPOI的锅
发现有下面这些对象占用了很大的内存,逐个分析,看看是我们代码的锅,还是NPOI的锅
2、!DumpHeap /d -mt 00007fff4fff0140 //查看当前方法表
3、!DumpObj /d 0000024587be7c40 //查看当前地址对应的内容
 发现这些都不是我们自己的程序代码生成的。因为NPOI生成Excel的大概原理:通过把数据加上你所设置的Excel的workbook,行,列,以及样式等等生成一个Excel,一次性的把所有数据都加载到内存中。
发现这些都不是我们自己的程序代码生成的。因为NPOI生成Excel的大概原理:通过把数据加上你所设置的Excel的workbook,行,列,以及样式等等生成一个Excel,一次性的把所有数据都加载到内存中。
Office Open XML(缩写:Open XML、OpenXML或OOXML),为由Microsoft开发的一种以XML为基础并以ZIP格式压缩的电子文件规范,支持文件、表格、备忘录、幻灯片等文件格式。
本来想基于这些对象,看看能否进行垃圾回收。
1、本来想用强制的垃圾回收,但是生产环境一般不敢这么用,因为GC啥时候进行回收,是有它自己的机制的,我们没必要去打乱。
2、那所以说不能强制垃圾回收,能不能加速垃圾回收呢,网上有很多方法说是把对象置位NULL就可以加速垃圾回收。貌似也没效果,具体原因还在分析中。
三、基于SXSSFWorkbook进行导出
他们提供了一个流式的SXSSFWorkbook版本,这种允许写入非常大的文件而不耗尽内存,因为在任何时候,只有可配置的行部分被保存在内存中,并且还可以自己定义导出的数据的模板。
用SXSSFWorkbook 就不要做太多的'Excel式'的操作,比如删除行,移动行等等,看最开始的那张图即可。
SXSSFWorkbook大致原理:借助临时存储空间生成Excel。
如下所示:这个1000的意思是:内存中只放1000行记录,如果超过1000行,就把数据写到磁盘中去(以临时文件的方式存储,不需要我们去管,这个SXSSFWorkbook导出),这样就避免内存溢出了。但是这样可能会让生成Excel的时间变长了,因为会涉及多次的IO操作。
IWorkbook wb = new SXSSFWorkbook(1000);
方法一、直接用SXSSFWorkbook(1000) ---从数据库查询所有数据出来,放到内存后
测试结果:CPU和内存相比usermodel要好很多,时间稍微的优点延长。
方法二、使用带分页SXSSFWorkbook的方式----从数据库按分页查询数据,生成临时文件,刷盘,最后生成完整的Excel。
public static byte[] ExportStreamAsPage<T>(string filename, int pageSize,Func<int,int,List<T>> action) where T : new()
{
IWorkbook wb = new SXSSFWorkbook(pageSize);
ISheet sheet = wb.CreateSheet(filename);
ItsmProvider itsmProvider = new ItsmProvider();
//设置标题
SetColumnTitle<T>(sheet, new T());
var type = typeof(T);
int pageIndex = 1;
Boolean hasNext = true;
//记录循环次数
while (hasNext)
{
var datas = action.Invoke(pageIndex,pageSize);
SetRowContent<T>(type, sheet, pageIndex, pageSize, datas);
//不包含任何数据的时候,就退出
if (!datas.Any())
{
break;
}
//说明已经到了最后一页。
if (datas.Count() < pageSize)
{
hasNext = false;
}
pageIndex++;
}
byte[] buffer;
using (NpoiMemoryStream ms = new NpoiMemoryStream())
{
ms.AllowClose = false;
wb.Write(ms);
ms.Flush();
buffer = new byte[ms.Length];
ms.Position = 0;
ms.Read(buffer, 0, buffer.Length);
ms.AllowClose = true;
}
wb.Close();
return buffer;
}
public static void SetRowContent<T>(Type type, ISheet sheet, int pageIndex, int pageSize, List<T> list)
{
int start = (pageIndex - 1) * pageSize + 1;
foreach (var model in list)
{
var properties = type.GetProperties();
IRow row = sheet.CreateRow(start);
int j = 0;
for (int i = 0; i < properties.Length; i++)
{
var p = properties[i];
object obj = p.GetValue(model, null);
if (obj != null)
{
row.CreateCell(i).SetCellValue(obj.ToString());
}
}
start++;
}
}
面这个方法,更加的省内存,不过时间上确实慢了,用时间换空间的一种做法。
四、基于分页SXSSFWorkbook的方式,多线程,多sheet
本来的想法是想着,一个sheet开多个线程来绘制excel的,但是这样实现不了,因为Sheet不是线程安全的,我强行给他加锁变成线程安全,这样就失去了多线程意义了。我们的业务场景确实用多个sheet来输出大量数据也能接受,所以最后就采用了这种方案。
public static byte[] ExportStreamByMultiSheet<T>(string filename,int recordCount, int pageSize, Func<int, int, List<T>> action) where T : new()
{
IWorkbook wb = new SXSSFWorkbook(pageSize);
var type = typeof(T);
//开启多线程(开启固定线程)方法
var excelTasks=new List<Task>();
int fixThreadCount = 10; //开启10个固定数量
for(int i=1;i< (recordCount / pageSize)+1; i++)
{
ISheet sheet = wb.CreateSheet(filename+i);
SetColumnTitle<T>(sheet, new T());
excelTasks.Add(
Task.Factory.StartNew(()=>
SetExcel(pageSize, action, sheet, type, i)
)
);
if (excelTasks.Count >= fixThreadCount)
{
Task.WaitAny(excelTasks.ToArray()); //等待任何一个完成
excelTasks = excelTasks.Where(d => d.Status != TaskStatus.RanToCompletion).ToList();
}
}
Task.WaitAll(excelTasks.ToArray());
byte[] buffer;
using (NpoiMemoryStream ms = new NpoiMemoryStream())
{
ms.AllowClose = false;
wb.Write(ms);
ms.Flush();
buffer = new byte[ms.Length];
ms.Position = 0;
ms.Read(buffer, 0, buffer.Length);
ms.AllowClose = true;
}
wb.Close();
return buffer;
}
五 、总结
大数据量导出防止OOM方法就是:SXSSFWorkbook,最理想的还是把这种大量数据导出做成独立的服务,部署到单独的机器上进行导出。
















 408
408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









