






SQL server安装遇到一些列连续问题
第一个问题:
PerfLib 2.0 计数器 removal 失败,退出代码为 2。命令行: C:\Windows\system32\unlodctr.exe /m:hkengperfctr.xml
第二个问题:
无法打开注册表项 UNKNOWN\Components\ #

通常在解决了第一个问题之后再次安装会出现第二个问题
先说说怎么解决第一个问题的:
原因可能是sqlserver安装失败之后,没有删除干净本地的一些东西
下载:windows installer clean up
官网地址:https://windows-installer-cleanup-utility.en.softonic.com/
下载完成之后,安装。然后把文件里带了SQL的都remove掉
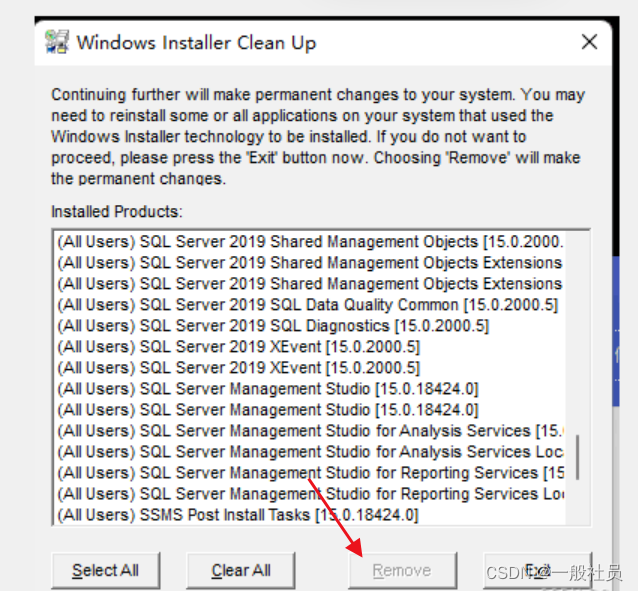
确认都remove之后,重启电脑,再次进行安装,不出意外会弹出第二个错误。继续往下看:
首先打开注册表,打开这个
计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Installer\UserData
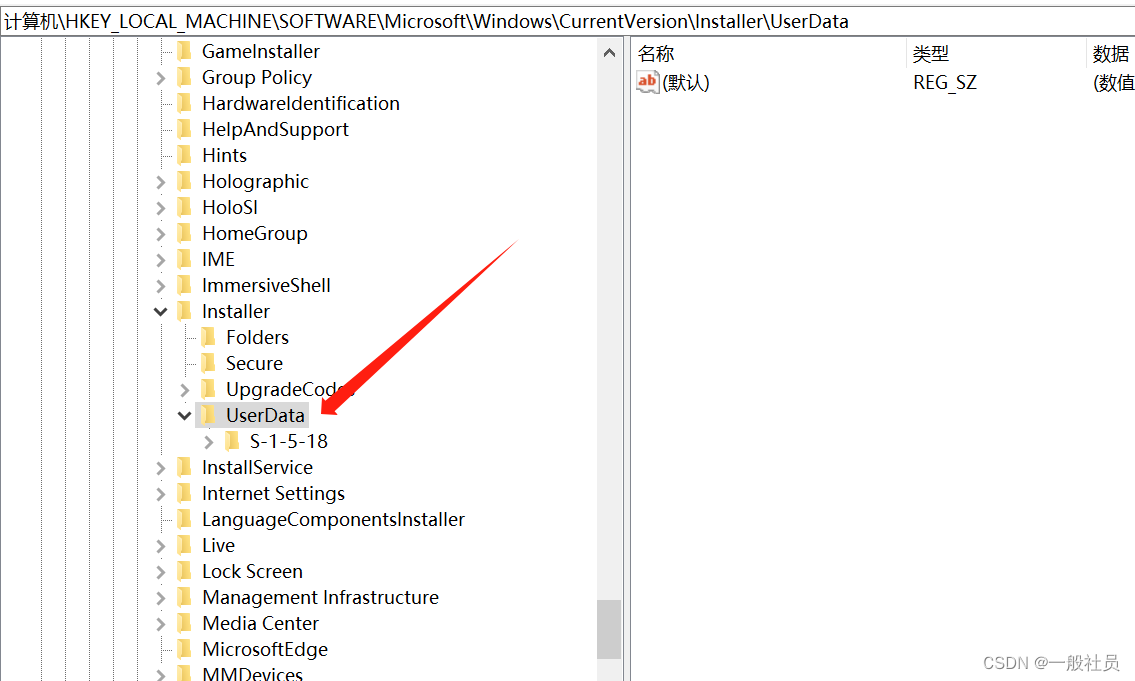
右键,点击权限
选择高级
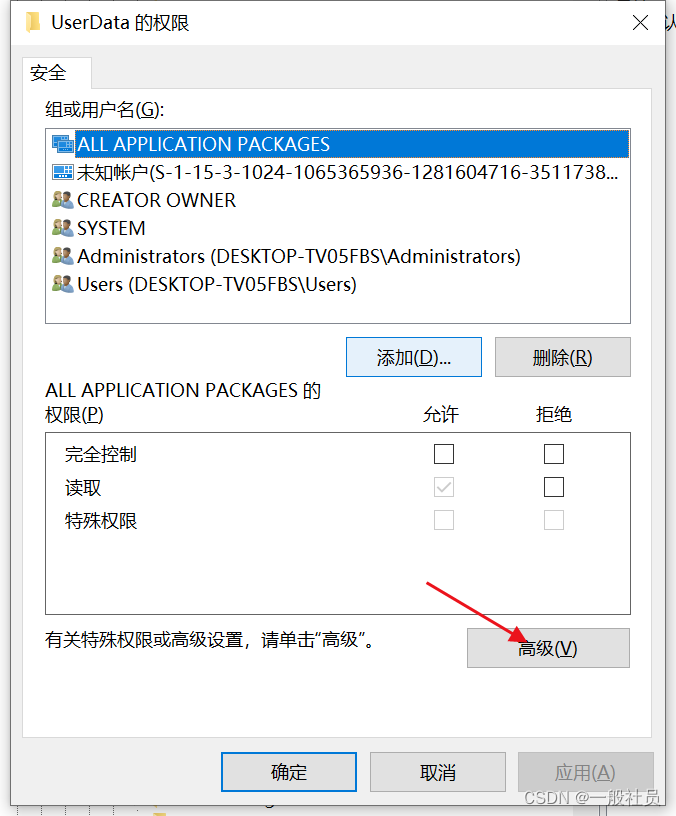
选择用户Administrators用户
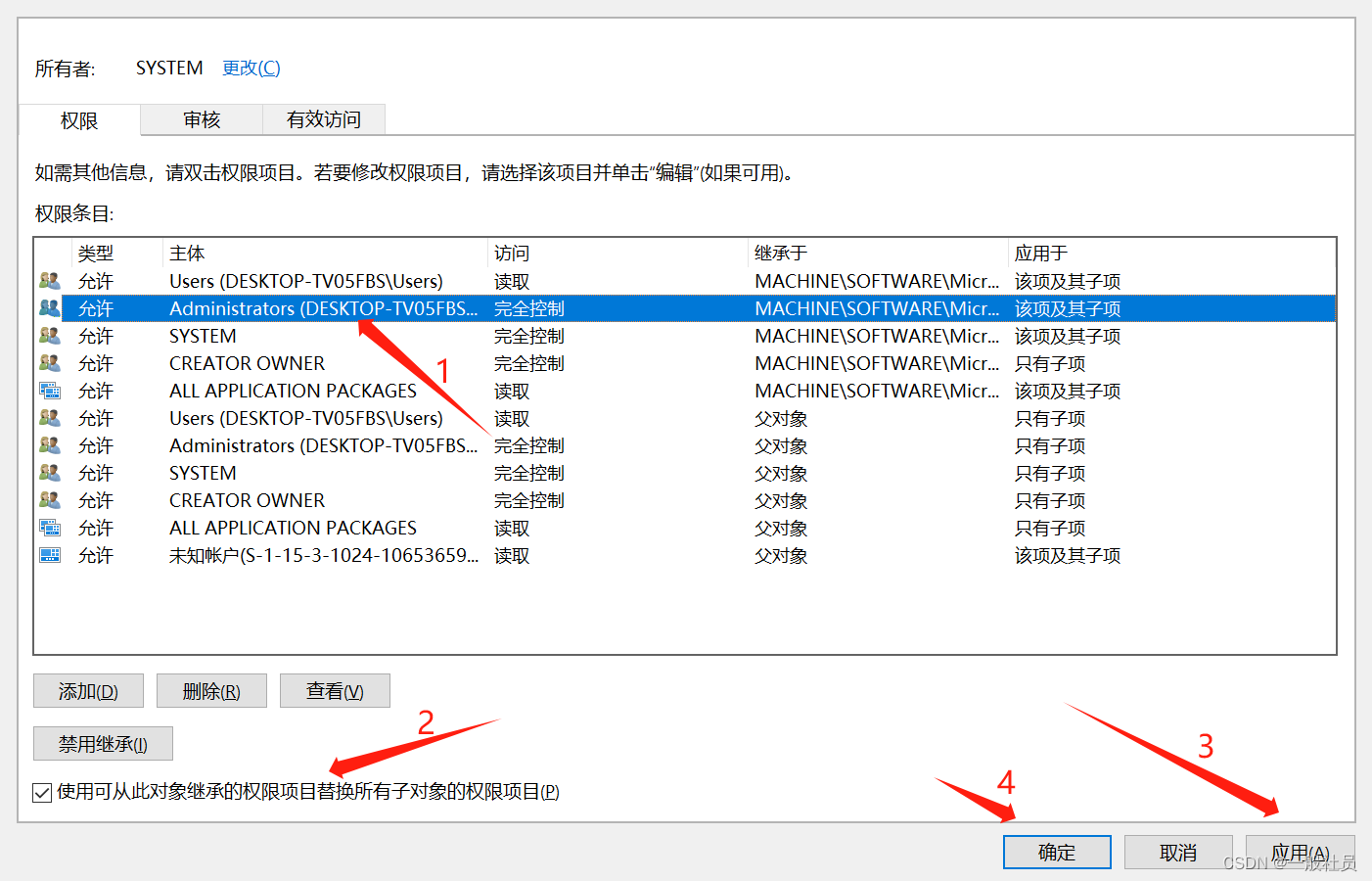
正常来说会弹出这个提示:
注册表编辑器无法在当前所选的项及其部分子项上设置安全性

按照如下方法可以成功修改:
下载Windows工具:psexec(注意,在安装此工具之前,要把刚刚打开的注册表编辑器关闭)
官网地址:https://learn.microsoft.com/zh-cn/sysinternals/downloads/psexec
下载完成,直接解压到本地即可,解压目录需要记录一下,需要配置环境变量,我解压在了D:/psexec
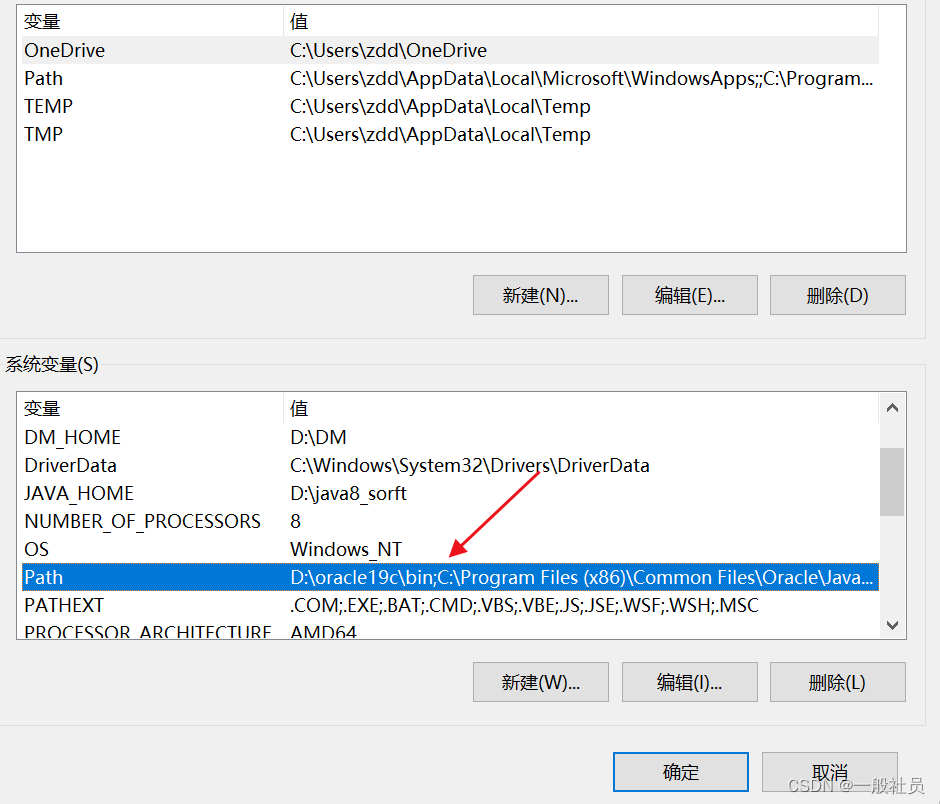
环境变量配置,如果不配置环境变量后面会识别不到命令
在系统变量里找到path,把刚刚psexec的解压目录配置上
执行命令,建议以管理员身份使用windows powershell
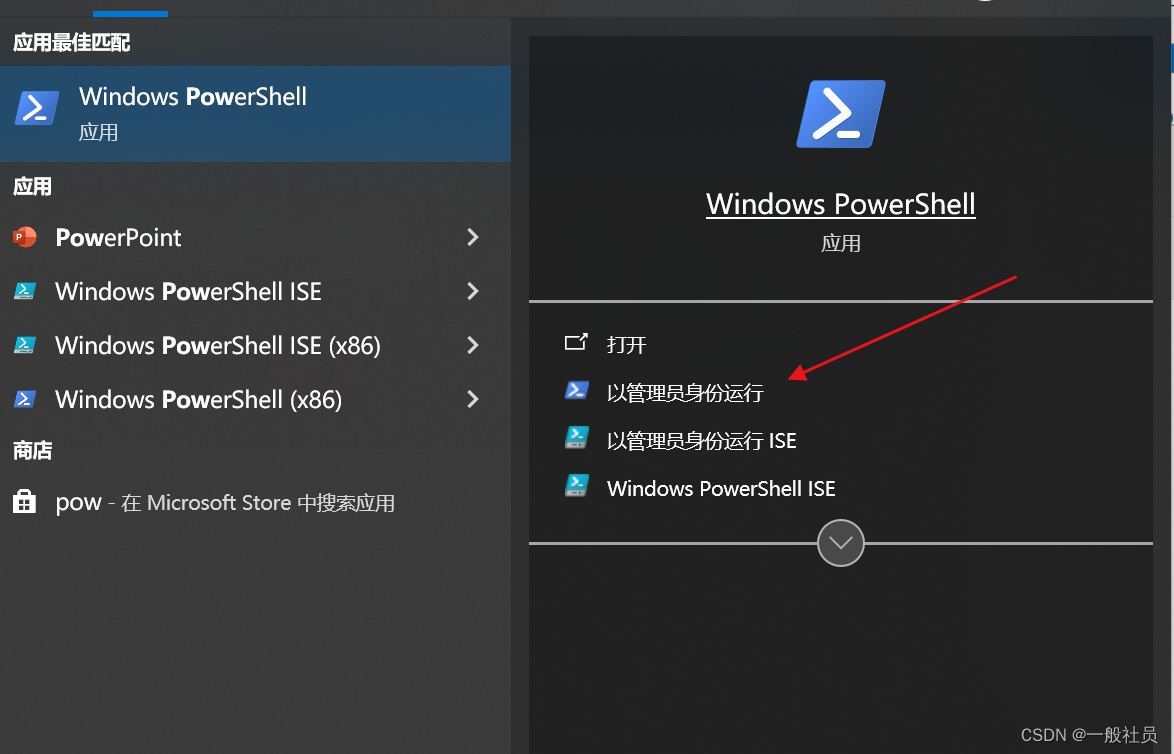
然后用cd命令进入刚刚psexec的解压目录,执行如下命令
psexec -i -d -s regedit
命令执行完之后,会自己弹出一个注册表编辑器,还是找到如下目录
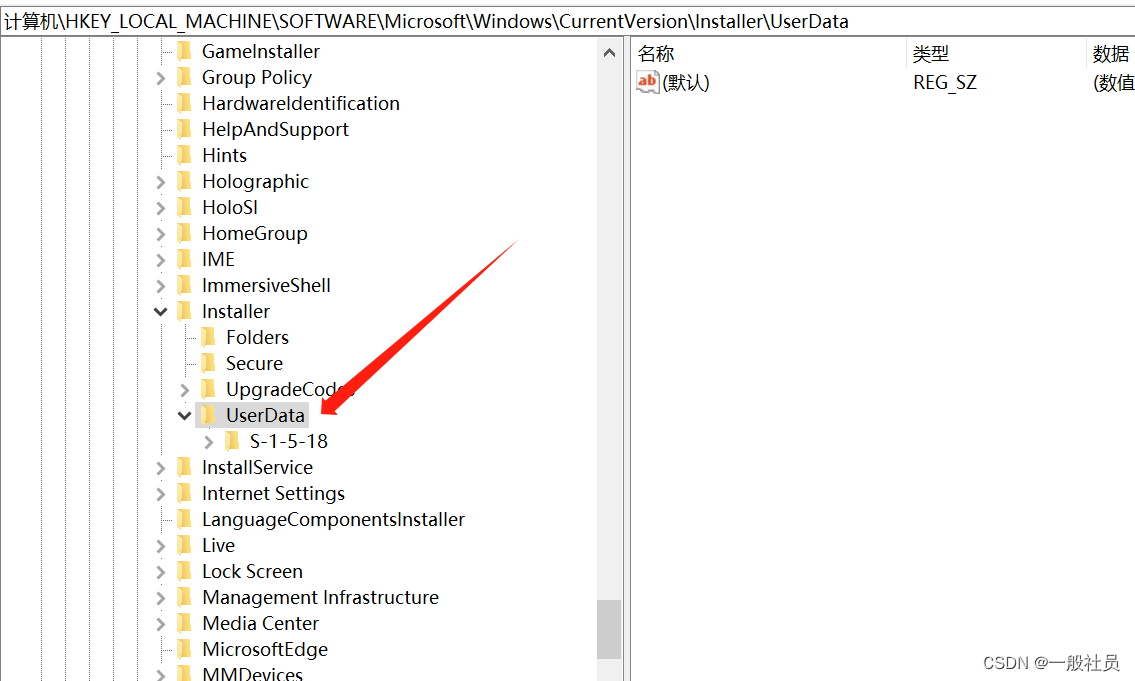
按照这个顺序再点一遍设置
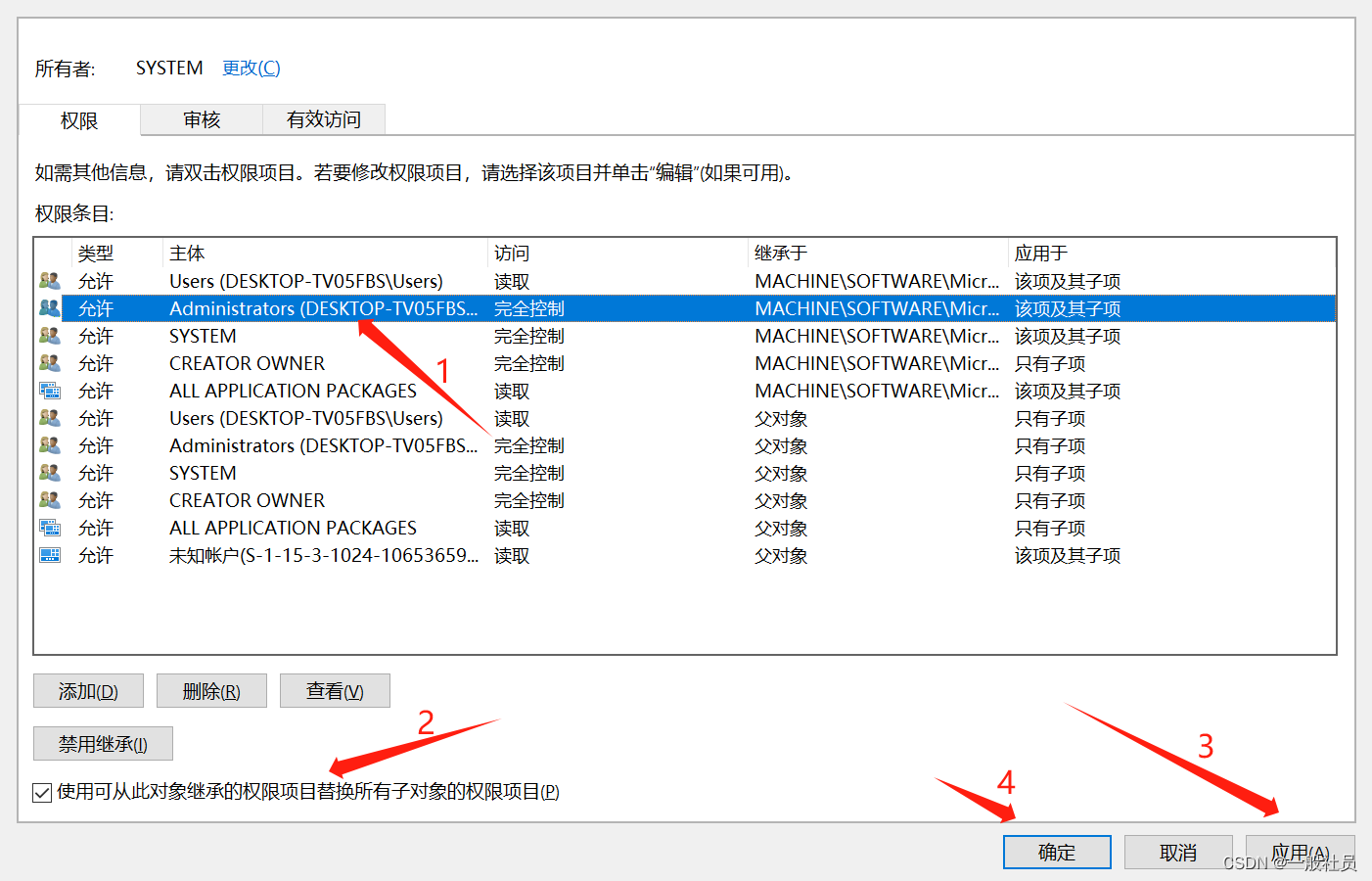
确保在设置的过程中没有弹出该提示

然后重新安装一下SQL server,即可成功
本人按照如上方法,亲测成功安装上了,可以作为参考,不一定百分百解决你的问题。如有疑问可以私信我















 1188
1188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









