







首先简单介绍一下到2021年变化检测的常见论文,采用的方法、代码的链接:变化检测经典论文
一、预备知识
近几年,随着Transformer和attention的大火,在CV(计算机视觉)领域很多论文都开始引入Transformer和attention,取得了不错的成果。Transformer本来是应用在NLP领域,ViT成功性的将Transformer引入了CD领域,何凯明大神在ViT的基础上进行了改进,提出了MAE。本篇文章便参考了MAE的框架,采用相同的Encoder,根据要解决的问题修改了Decoder部分。建议先了解一下Transformer、阅读一下ViT和MAE这两篇论文。
关于CD、ResNet的介绍,在此处不展开说明。
二、BIT_CD网络结构
BIT_CD主要利用常见的Restnet的部分层作为特征提取器,通过编码将得到的特征图进行分块,然后送入Transformer Encoder、Transformer Decoder进行特征加强,最后进行预测。
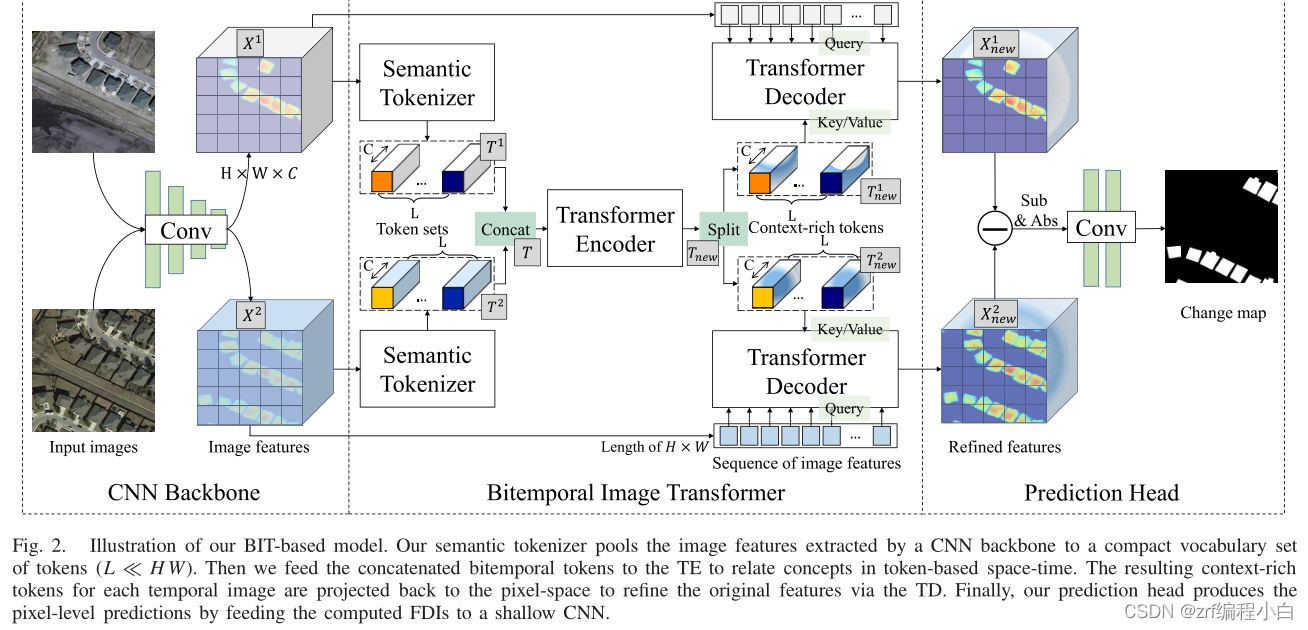
Fig2的网络结构图没有把具体细节展示出来,下面我根据自己对论文和代码的理解对CNN Backbone、Bitemporal Image Transforme、Prediction Head三个模块进行介绍。
1. CNN Backbone
通过阅读源码发现该模块使用ResNet的部分曾作为Backbone对输入的两幅图片进行特征提取得到两个特征图 X 1 X^1 X1、 X 2 X^2 X2。
2. Bitemporal Image Transformer
该模块比较复杂,主要包含Semantic Tokenizer、Transformer Encoder、Transformer Decoder这三个部分。
a.Semantic Tokenizer
该模块主要用来对得到的两个特征图
X
1
X^1
X1、
X
2
X^2
X2进行编码,分割得到语义tokens,以便接下来的Transformer操作。
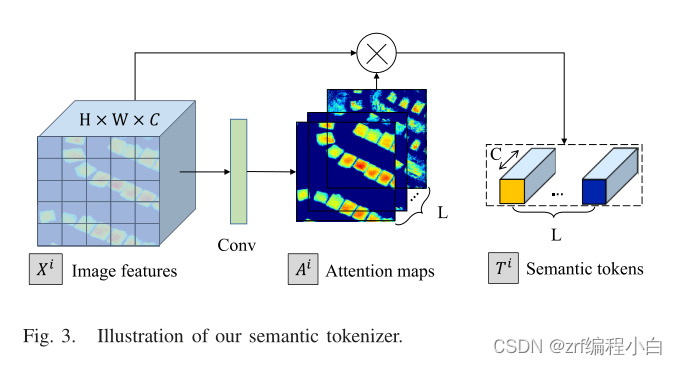
该模块将特征图
X
i
X^i
Xi送入一个1X1的卷积核,个人觉得通过该卷积一方面是为了得到Attention maps,另一方面是将特征图
X
i
X^i
Xi的通道数C改为L,以便接下来进行softmax操作得到L个通道数为C的语义tokens。至于这个softmax如何操作?代码中先将
X
i
X^i
Xi从HxWxC通过view函数变成(HxW)xC,
A
i
A^i
Ai通过view函数从HxWxL变成(HxW)xL,这样便可以进行softmax操作。
作者在论文写了一下设计该层的目的:1.输入图像中兴趣的变化可以用几个高级概念来描述;2.借鉴NLP将文本转化为一个个token。我认为为了达到这目的1就要对得到的特征图
X
i
X^i
Xi进行打分融合,便有了卷积提取更深一层的特征,softmax进行打分。
b.Transformer Encoder
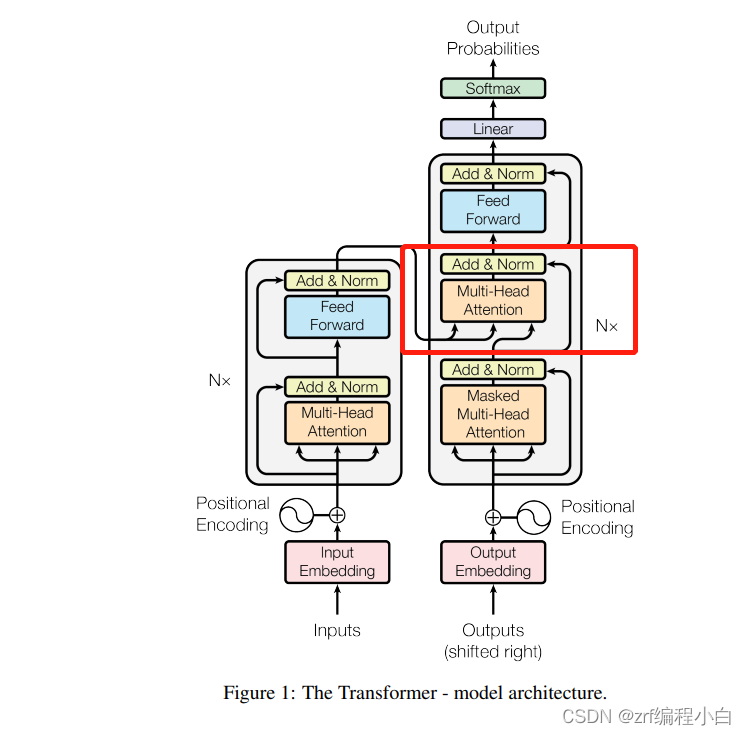
该模块完全采用了ViT提出的Encoder
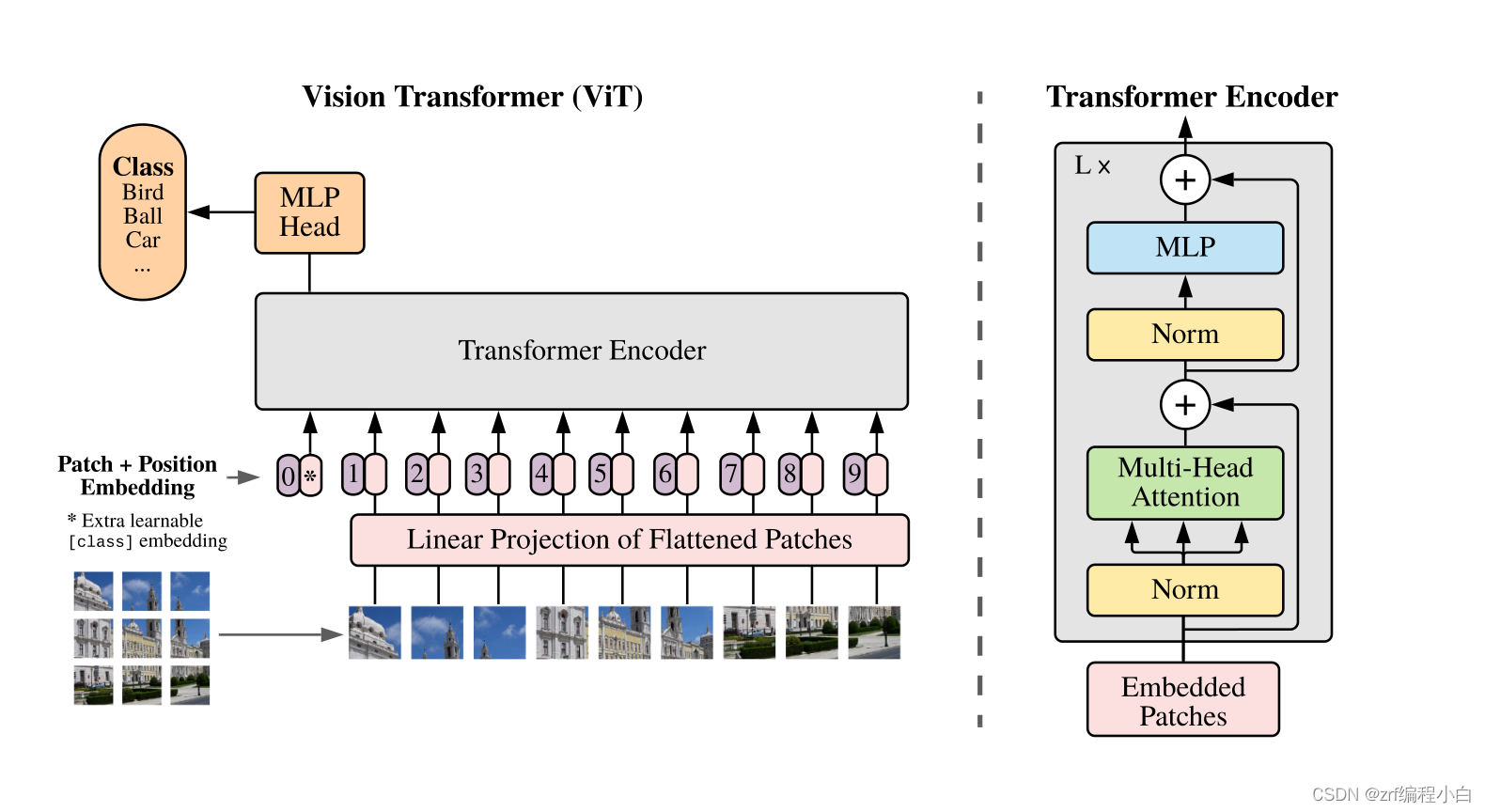
上图右半边为ViT提出的Transformer Encoder,下图左半边a为BIT_CD论文中的Transformer Encoder
该模块就是Transformer,没有啥需要详细介绍的,具体可以看一下Transformer的论文介绍。其中作者特地点明在MLP层使用GELU作为激活函数,此外使用Positional Encoding可以有助于提高模型性能。
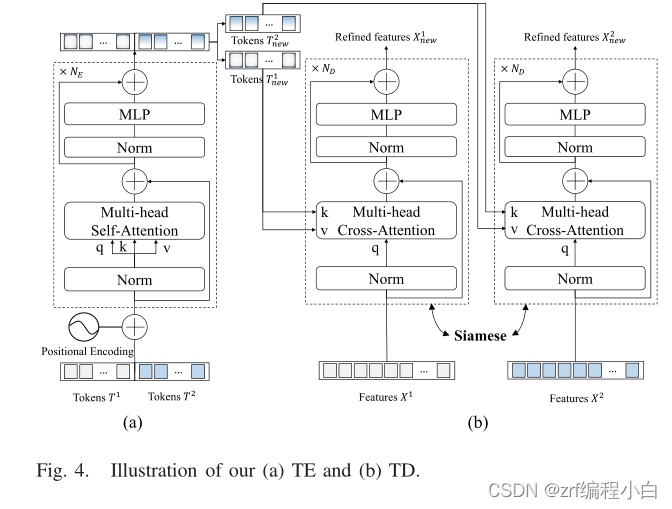
c.Transformer Decoder
该模块大部分结构和Transformer Encoder相似,不同点在于将Multi-head Self-Attention修改为Multi-head Cross-Attention。也就是原来Attention部分的Q、K、V均是由输入乘以
W
q
W_q
Wq、
W
k
W_k
Wk、
W
v
W_v
Wv(代码中可以通过线性层实现),而TD部分的输入是特征图
X
i
X^i
Xi,将
X
i
X^i
Xi乘以
W
q
W_q
Wq、之前获得的语义Token乘以
W
k
W_k
Wk、
W
v
W_v
Wv。为什么要设计Multi-head Cross-Attention,我觉得是借鉴Attention is all you need这篇论文提出的针对NLP的Decoder部分。
3.Prediction Head
这个部分就比较简单了,首先通过一个上采样将得到的
X
n
e
w
i
X^{i}_{new}
Xnewi还原为输入图片的尺寸并做差得到FDI,接着通过两个卷积层和BN层等进行提取,最后通过Softmax层。具体公式如下,其中g为两个卷积层和BN层,P为预测出来的差异图。
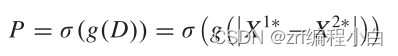
三、损失函数
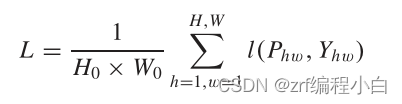
损失函数采用的是交叉熵损失。
四、实验结果
实验结果后续更新。















 4692
4692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









