







一、实验目的及要求
1、掌握MapReduce并行编程方法
2、掌握自定义数据类型
3、掌握自定义分区类和自定义排序类的使用
4、掌握最值求解并行化方法
二、实验原理与内容
假设有一个服务器每天都记录同一个网站的访问量数据,主要是该网站下所有页面中的最大访问量和最小访问量,数据存储在下面三个文件中。



数据格式如下(记录时不具体到天):

说明:第一列为某年某月的时间信息,第二列为该月内某天观测到的最大访问量,第三列为该月内同一天观测到的最小访问量。
程序设计要求如下:
最后输出网站每个月内的最大值、最小值,一个月一行数据。
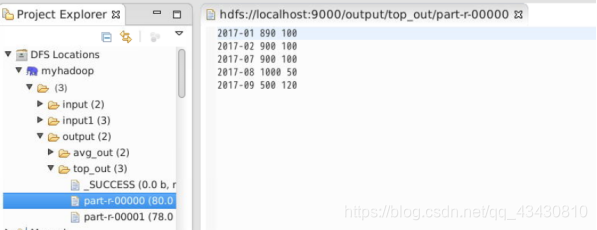
如图中2017-07最大值为900,最小值为100;2017-08最大值为560,最小值为200
输出格式如下
2017-08 560 200
2017-07 900 100
必须自定义一个数据类型,包含某天观测到的最大最小访问量。
说明:第一列为某年某月的时间信息,第二列为该月内某天观测到的最大访问量,第三列为该月内同一天观测到的最小访问量。
程序设计要求如下:
最后输出网站每个月内的最大值、最小值,一个月一行数据。
如图中2017-07最大值为900,最小值为100;2017-08最大值为560,最小值为200
输出格式如下
2017-08 560 200
2017-07 900 100
三、实验软硬件环境
Hadoop集群
四、实验过程(实验步骤、记录、数据、分析)
注:给出所有代码和最终结果截图,排版工整美观
Driver.java
package cn.lingnan.edu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.lingnan.edu.MyDriver.class);
// TODO: specify a mapper
job.setMapperClass(cn.lingnan.edu.MyMapper.class);
job.setPartitionerClass(cn.lingnan.edu.MyPartitioner.class);
job.setSortComparatorClass(cn.lingnan.edu.MySort.class);
job.setCombinerClass(cn.lingnan.edu.MyReducer.class);
// TODO: specify a reducer
job.setReducerClass(cn.lingnan.edu.MyReducer.class);
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(MyWritable.class);
// TODO: specify output types
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(cn.lingnan.edu.MyWritable.class);
job.setNumReduceTasks(2);
// TODO: specify input and output DIRECTORIES (not files)
FileInputFormat.setInputPaths(job, new Path("hdfs://0.0.0.0:9000/input1"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://0.0.0.0:9000/output/top_out"));
if (!job.waitForCompletion(true))
return;
}
}
MyWritable.java
package cn.lingnan.edu;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class MyWritable implements Writable{
private int min;
private int max;
private int mouth;
private int year;
public int getMouth() {
return mouth;
}
public void setMouth(int mouth) {
this.mouth = mouth;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
@Override
public String toString() {
return max + " " + min ;
}
public int getMin() {
return min;
}
public void setMin(int min) {
this.min = min;
}
public int getMax() {
return max;
}
public void setMax(int max) {
this.max = max;
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
min = in.readInt();
max = in.readInt();
year = in.readInt();
mouth = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(min);
out.writeInt(max);
out.writeInt(year);
out.writeInt(mouth);
}
}
MyMapper.java
package cn.lingnan.edu;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, Text, MyWritable> {
private MyWritable my = new MyWritable();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String [] strs = value.toString().split(" ");
String date = strs[0];
if(date == null){
return;
}
String year=date.split("-")[0];
//System.out.println(year);
String mouth=date.split("-")[1];
//System.out.println(mouth);
my.setMax(Integer.parseInt(strs[1]));
my.setMin(Integer.parseInt(strs[2]));
my.setMouth(Integer.parseInt(mouth));
my.setYear(Integer.parseInt(year));
context.write(new Text(date), my);
}
}
MyPartitioner.java
package cn.lingnan.edu;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<Text,MyWritable> {
@Override
public int getPartition(Text key, MyWritable value, int numPartitions) {
// TODO Auto-generated method stub
// if(key.toString().split("-")[0].equals("2017")){
if(key.String().split(“-”)[0].equals(“2017”){
return 0;
}
else {
return 1;
}
}
}
MySort.java
package cn.lingnan.edu;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class MySort extends WritableComparator{
public MySort(){
super(Text.class,true);
}
public int Compare(WritableComparable a,WritableComparable b){
IntWritable v1 = new IntWritable(Integer.parseInt(a.toString().split(“-”)[1]);
IntWritable v2 = new IntWritable(Integer.parseInt(b.toString().split(“-”)[1]);
return v2.compareTo(v1);
}
}
MyReducer.java
package cn.lingnan.edu;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
public class MyReducer extends Reducer<Text, MyWritable, Text, MyWritable> {
private MyWritable my = new MyWritable();
public void reduce(Text key, Iterable<MyWritable> values, Context context)
throws IOException, InterruptedException {
my.setMax(0);
my.setMin(0);
// process values
for (MyWritable val : values) {
if(my.getMin()==0||val.getMin()<my.getMin()){
my.setMin(val.getMin());
}
if(my.getMax()==0||val.getMax()>my.getMax()){
my.setMax(val.getMax());
}
}
context.write(key,my);
}
}
运行结果:
一份2017输出
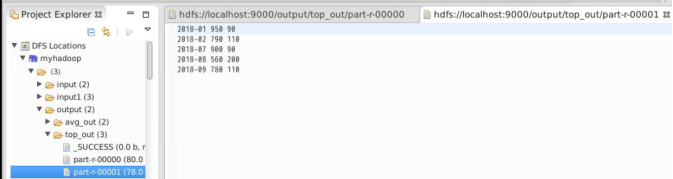
一个2018输出














 3492
3492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









