









前言: 当前排序案例基于下面这个全排序案例的输出数据。
全排序案例:https://blog.csdn.net/qq_43437122/article/details/106290300
1.需求
要求每个省份手机号输出的文件中按照总流量内部排序。
2.需求分析
基于前一个需求,增加自定义分区类,分区按照省份手机号设置

3. 案例实操:
(1)增加自定义分区类
package com.mapreduce.fcwritablecomparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class FCPartitioner extends Partitioner<FCBeanWritableComparable, Text>{
@Override
public int getPartition(FCBeanWritableComparable k, Text v, int numReducers) {
// 1. 定义一个变量来表示分区号
int partition = 4;
// 2. 获取手机号
String phone = v.toString();
// 3. 设置分区
if(phone.substring(0, 3).equals("136")) {
partition = 0;
} else if(phone.substring(0, 3).equals("137")) {
partition = 1;
} else if(phone.substring(0, 3).equals("139")) {
partition = 2;
} else if(phone.substring(0, 3).equals("135")) {
partition = 3;
}
return partition;
}
}
(2)在驱动类中添加分区类
// 8. 设置分区方式
job.setPartitionerClass(FCPartitioner.class);
// 9. 设置Reduce Task的个数
job.setNumReduceTasks(5);
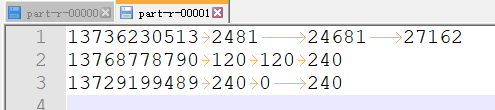
4. 运行结果(只展示两个,有五个文件)
















 1029
1029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









