







一.概述
数据库标准化是EF Codd在1970年代开发的,是许多数据库设计的标准要求。规范化是一种可以帮助您避免数据异常和管理数据的其他问题的技术。
目的:
- 消除数据冗余(因此使用更少的空间)
- 使更改数据变得更容易,并且在这样做时避免出现异常
- 使参照完整性约束更易于实施
- 产生易于理解的结构,该结构与数据所代表的情况非常相似,并可以进行扩展
二.数据依赖
一个关系模式中属性之间的相互约束、相互制约关系,称作数据依赖。是现实世界属性间相互联系的抽象,数据内在的性质,语义的体现。一般分为函数依赖、多值依赖(MVD)、连接依赖。
'不好’的关系模式存在的问题
当前存在一个关系模式:SCD(Sno,Sname,Ssex,Sdept,Sdean,Cno,Cname,Grade)
其中,SCD表示学生关系,对应的各属性依次为学号、姓名、性别、院系、系主任、课程号、课程名称和成绩。关系的主码为(Sno,Cno)。
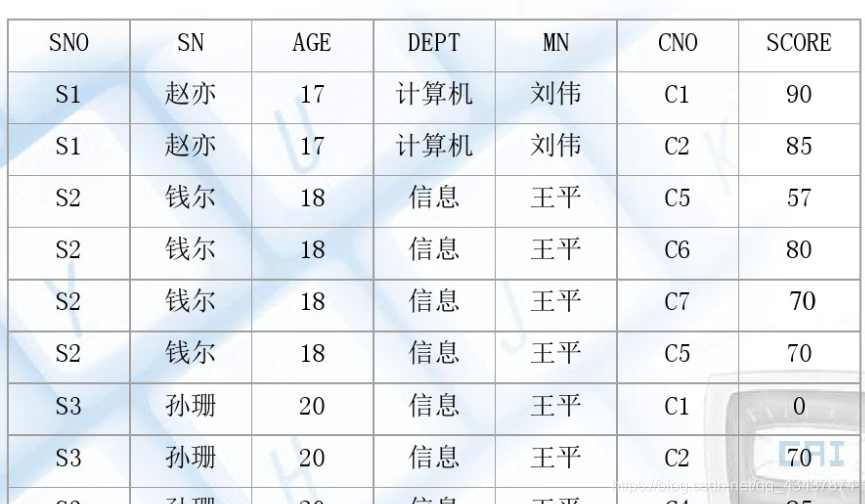
这个关系模式存在如下问题。
-
数据冗余
当一个学生选修多门课程就会出现数据冗余。假如某个学生(“s4”,“丁天波”,“男”,“管理学院”,“张胜”)共选了20门课程,则该学生的学号、姓名、性别、院系、系主任信息要重复存储20次,如果全校有一万名学生都要选修多门课程,则这样的冗余就会造成大量的空间上的浪费。同时,同一门课程如果有多名学生选修,课程名称要重复存储多次,这样进一步增加了存储空间的开销。 -
更新异常
由于存在大量的数据冗余,当更新数据库中的数据时,系统要付出很大的代价来维护数据库的完整性。否则会面临数据不一致性的危险。例如,某院系要换系主任,或某门课程要修改名字,必须要修改每一个相关的元组,如果一部分修改了,而另外一部分未修改,则造成了数据的不一致性。 -
插入异常
如果刚开出一门课程,但是这样的课程还没有学生选修,则无法把课程信息插入到该数据库中;如果一个学生刚刚入学,还没有选修任何课程,则这样的学生无法插入到该数据库中;如果一个院系刚刚成立,还没有招收任何学生,则这个院系信息也无法添加到数据库中。 -
删除异常
如果选修某门课程的学生都毕业了,在删除学生信息时,则相关的课程信息业会跟着被删除。
鉴于以上种种问题,可以得出结论:设计的该关系模式SCD并不是一个好的关系模式。一个好的关系模式应该不会发生插入异常、删除异常和更新异常,数据冗余也会降到最小。
一个关系模式之所以会产生上述问题,是由于关系模式中存在着不良的函数依赖关系引起的。
所以需要通过规范化理论来改造关系模式,消除不合适的数据依赖,解决以上问题。
函数依赖
函数依赖( Functional Dependency,简记为FD),是关系模式中属性之间的一种逻辑依赖关系。属性间的这种依赖关系类似于数学中的函数y=f(×),自变量x确定之后,相应的函数值y也就惟一地确定了。
分析数据依赖
现在我们建立一个描述学校教务的数据库,该数据库涉及的对象包括学生的:
- 学号(Sno)
- 所在系(Sdept)
- 系主任姓名(Mname)
- 课程名(Cname)
- 成绩(Grade)
假设我们用一个单一的关系模式Student来表示,则该关系模式的属性集为: U ={ Sno,Sdept,Mname,Cname,Grade }
现实世界的已知事实(语义)告诉我们:
- 一个系有若干学生,但一个学生只属于一个系。
- 一个系只有一名主任。
- 一个学生可以选修多门课程,每门课程有若干学生选修。
- 每个学生所学的每门课程都有一个成绩。
从上述事实我们可以得到属性集U上的一组函数依赖F:F = { Sno→Sdept,Sdept→ Mname,(Sno,Cname)→Grade } 。即:学号决定所在系,所在系决定系主任名,学号和课程决定成绩。
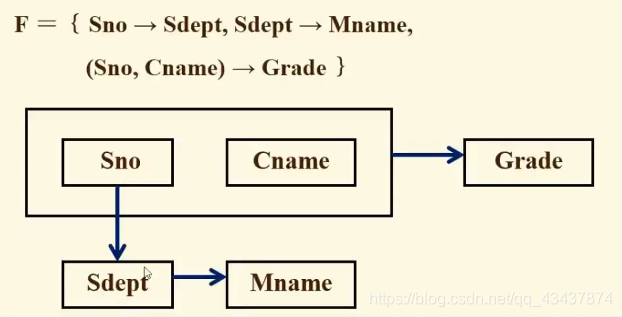
函数依赖的定义:
设关系模式R(U,F),U是属性全集,F是U上的函数依赖集,x和Y是U的子集,如果对于R(U)的任意一个可能的关系r,对于X的每一个具体值,Y都有唯一的具体值与之对应,则称x决定函数Y,或y函数依赖于×,记作X→Y。我们称×为决定因素,Y为依赖因素。当Y不函数依赖于x时,记作:x-/->Y。当→Y且Y→×时,则记作:X<–>Y。
1. 非平凡函数依赖与平凡函数依赖
在关系模式R(U)中,对于U的子集X和Y
如果X→Y,但Y不属于X,则称X→Y是非平凡的函数依赖
若X→Y,但Y 属于X,则称X→Y是平凡的函数依赖
举例:
在关系模式SC(Sno, Cno, Grade)中,(Sno, Cno)→ Grade,学号和课程决定成绩,但是成绩不属于学号或课程,则为非平凡的函数依赖。
(SnO,CNO)→CNO,学号和课程可以决定学号,学号也属于学号和课程,则为平凡的函数依赖,对于任一关系模式,平凡函数依赖都是必然成立的,它不反映新因此若不特别声明,我们总是讨论非平凡函数依赖。
2. 完全函数依赖与部分函数依赖
定义:
设关系模式R(U),U是属性全集,X和Y是U的子集,如果X→Y,并且对于X的任何一个真子集X’,都有X’-\ ->Y,则称Y对X完全函数依赖(Fu11 Functiona1 Dependency ) ,记作X-f>Y。
如果对X的某个真子集X’,有X’→Y,则称Y对X部分函数依赖(Partia1 Functiona1 Dependency ) ,记作X-p->Y。
由定义可知:
- 只有当决定因素是组合属性时,讨论部分函数依赖才有意义,
- 当决定因素是单属性时,只能是完全函数依赖。
3. 传递函数依赖和直接函数依赖
如果X->Y,Y->Z, 这时称Z对X传递函数依赖。
如果Y→X,则X<–>Y,这时称Z对X直接函数依赖,而不是传递函数依赖。
综上所述,函数依赖分为完全函数依赖、部分函数依赖和传递函数依赖三类,它们是规范化理论的依据和规范化程度的准则。
三、范式
概念
数据库设计的规范化的基本思想是消除关系模式中的数据冗余,消除数据依赖中的不合适的部分,解决数据插入、删除时发生异常现象。这就要求关系数据库设计出来的关系模式要满足一定的条件。我们把关系数据库的规范化过程中为不同程度的规范化要求设立的不同标准称为范式(Normal Form ) 。
历史
- 范式的概念最早由E.F.Codd提出。
- 从1971年起,Codd相继提出了关系的三级规范化形式,即第式(1NF)、第二范式(2NF)、第三范式( 3NF )。
- 1974年,Codd和Boyce以共同提出了一个新的范式的概念,良Boyce-Codd范式,简称BC范式。
- 1976年Fag in提出了第四范式,·后来又有人定义了第五范式。
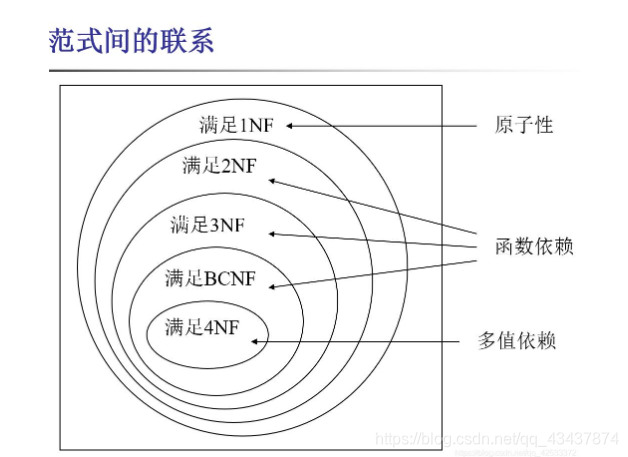
- 至此在关系数据库规范中建立了一个范式系列:1NF,2NF,3NF, BCNF,4NF,5NF,一级比一级有更严格的要求。
各个范式之间的联系可以表示为:5NF ∈4NF ∈BCNF ∈3NF ∈ 2NF ∈1NF
若某一关系模式R为第n范式,可简记为R∈nNF
第一范式(First Normal Form)
第一范式是最基本的规范形式,即关系中每个属性都是不可再分的简单项。但是满足第一范式的关系模式并不一定是一个好的关系模式。
如果关系模式R,其所有的属性均为简单属性,即每个属性都城是不可再分的,则称R属于第一范式,简称1NF,记作R ∈1NF。
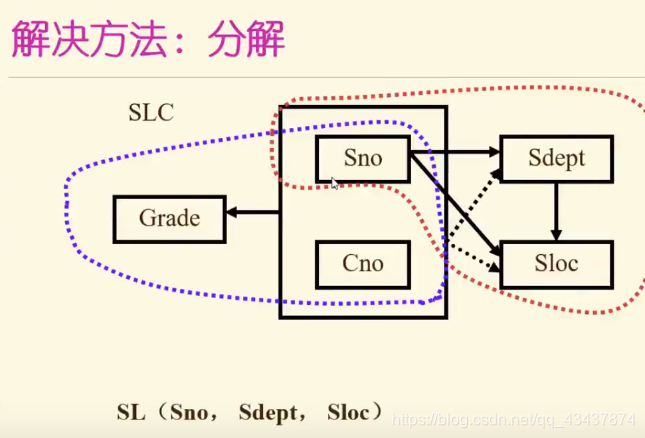
例:关系模式SLC(Sno, Sdept, Sloc, Cno, Grade),其中各属性分别为学号,所在系,宿舍楼,课程号和成绩。规定:一个学生就属于一个系,每个系的学生住在同一个宿舍楼,一个学生学的每一门课程都有唯一的成绩。
写出所有的函数依赖:
Sno → Sdept,Sdppt→ Sloc,(Sno, Cno)→ Grade
部分函数依赖:
(Sno, Cno) →Sno , (Sno, Cno)→Sdept
(Sno, Cno)→Sloc,(Sno, Cno)→Cno
(⑴)插入异常
(1)插入异常
假设Sno=95102,Sdept=IS,Sloc=N的学生还未选课,因课程号是主属性,I该学生的信息无法插入SLC
(2)删除异常
假定某个学生本来只选修了3号课程这一门课。现在因身体不适,他连3号课程t选修了。因课程号是主属性,此操作将导致该学生信息的整个元组都要删除(3)数据冗余度大
如果一个学生选修了10门课程,那么他的Sdept和Sloc值就要重复存储了10次(4)修改复杂
如学生转系,在修改此学生元组的Sdept值的同时,还可能需要修改住处(Sloc果这个学生选修了10门课,则必须无遗漏地修改10个元组中全部Sdept、Sloc信
第二范式(Second Normal Form)
如果关系模式R∈ 1NF,且每个非主属性都完全函数依赖于R的每个关系键,则称R属于第二范式 ,简称2NF,记作R∈ 2NF。
在关系模式SCD中,SNO,CNO为主属性,AGE,DEPT,MN,MN,SCORE均为非主属性,经上述分析,存在非主属性对关系键的部分函数依赖,所以SCD不属于2NF。

第三范式(3rd Normal Form)
在以下情况下,表为第三范式:
它是第二范式
它不包含传递依赖项(非键属性通过另一个非键属性依赖于主键)
现在,所有这些表均处于第三范式。对于大多数表,第三范式通常就足够了,因为它避免了最常见的一种数据异常。建议您在实现之前将使用的大多数表转换为第三范式,因为在大多数情况下,这将实现数据库归一化概述中列出的归一化目标。
BC范式 (Boyce-Codd Normal Form)
·如果一个关系数据库中所有关系模式都属于3NF,则已在很大程度上消除了插入异常和删除异常,但由于可能存在主属性对候选键的部分依赖和传递依赖,因此关系模式的分离仍不够彻底。
·如果一个关系数据库中所有关系模式都属于BCNF,那么在函数依赖的范畴内,已经实现了模式的彻底分解,消除了产生插入异常和删除异常的根源,而且数据冗余也减少到极小程度。
第四范式(4th Normal Form)
因此,如果满足以下条件,则表格的格式为第4种形式:
它是Boyce-Codd的标准格式
它不包含一个以上的多值依赖项
第五范式(5th Normal Form)
四、 关系模式的规范化
到目前为止,规范化理论已经提出了六类范式(有关4NF和5NF的内容不再详细介绍)。
各范式级别是在分析函数依赖条件下对关系模式分离程度的一种测度,范式级别可以逐级升高。
一个低一级范式的关系模式,通过模式分解转化为若干个高一级范式的关系模式的集合,这种分解过程叫作关系模式的规范化( Normalization)。
关系模式规范化的目的和原则
一个关系只要其分量都是不可分的数据项,就可称作规范化的关系,但这只是最基本的规范化。这样的关系模式是合法的。但人们发现有些关系模式存在插入、删除、修改异常、数据冗余等弊病。规范化的目的就是使结构合理,消除存储异常,使数据冗余尽量小,便于插入、删除和更新。
关系模式规范化的原则
规范化的基本原则就是遵从概念单一化“一事一地”的原则,即一个关系只描述一个实体或者实体间的联系。若多于一个实体,就把它“分离”出来。因此,所谓规范化,实质上是概念的单一化,即一个关系表示一个实体。
关系模式规范化的步骤
规范化就是对原关系进行投影,消除决定属性不是候选键的任何函数依赖。具体可以分为以下几步:
1.对1NF关系进行投影,消除原关系中非主属性对键的部分函数依赖,将1NF关系转换成若干个2NF关系。
2.对2NF关系进行投影,消除原关系中非主属性对键的传递函数依赖,将2NF关系转换成若干个3NF关系。
3.对3NF关系进行投影,消除原关系中主属性对键的部分函数依赖和传递函数依赖,也就是说使决定因素都包含一个候选键。得到一组BCNf关系


















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











