




缓存
存在内存中的临时数据
为什么使用缓存
减少和数据库的交互次数,提高执行效率
哪些数据适合使用缓存
经常查询但不怎么改变,数据的正确与否对最终的结果影响不大
mybatis中的缓存
- 一级缓存
指的是mybatis中SQLSession对象的缓存,当我们执行查询操作之后,查询的结果会同时存入到SQLSession提供的一块区域,该区域的结构是一个Map集合,当我们在此查询相同的数据时,Mybatis会先从这块区域中查询是否有相对应的查询结果
@Test
public void testFirstLevelCache(){
User user = userDao.findById(41);
User user2 = userDao.findById(41);
System.out.println(user==user2);
}
 虽然执行了两次查询,但查询的条件都相同第二次就直接从缓存中获取并没有重新从数据库中查询
虽然执行了两次查询,但查询的条件都相同第二次就直接从缓存中获取并没有重新从数据库中查询
- 一级缓存失效的情况
SQLSession关闭:当SQLSession不同时,即使查询相同的语句但由于之前的SQLSession已经关闭缓存就随之消失当下次创建并查询时已经不可能通过之前的SQLSession获取缓存
@Test
public void testFirstLevelCache(){
User user = userDao.findById(41);
session.close();
session = factory.openSession();
userDao = session.getMapper(IUserDao.class);
User user2 = userDao.findById(41);
System.out.println(user==user2);
}
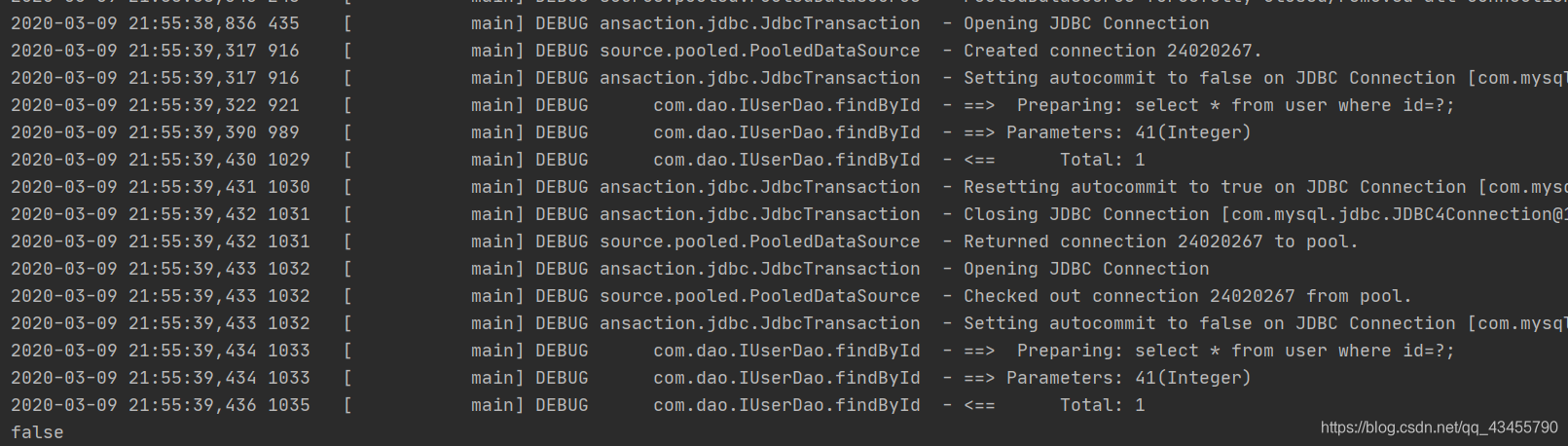
当调用SQLSession进行修改,删除,添加操作时,相应之前的查询的数据可能会被修改所以缓存也随之消失,commit(),close()方法时缓存也会消失,
-
二级缓存(全局缓存):基于namespace级别的缓存,一个namespace对应一个二级缓存
工作机制:
1.一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中
2.如果会话关闭,一级缓存中的数据会被保存到二级缓存中,新的会话查询信息,就可以参照二级缓存
3.UserDao->User DepartmentDao->Department不同的namespace查出的数据会放在自己对应的缓存当中
使用:
1.开启全局二级缓存配置<setting name="cacheEnabled" value="true"/>2.在对应的Mapper中添加
<cache></cache>
cache中的标签
eviction(回收策略):
LRU – 最近最少使用的:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
默认的是 LRU。
flushInterval(刷新间隔):
可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不清空,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目):
可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读):
属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化) 。这会慢一些,但是安全,因此默认是 false。
3.POJO需要实现序列化接口
@Test
public void testSecondLevelCache(){
SqlSessionFactory factory = builder.build(is);
SqlSession session = factory.openSession();
SqlSession session2 = factory.openSession();
IUserDao mapper1 = session.getMapper(IUserDao.class);
IUserDao mapper2 = session2.getMapper(IUserDao.class);
User u1 = mapper1.findById(41);
System.out.println(u1);
session.close();
User u2 = mapper2.findById(41);
System.out.println(u2);
System.out.println(u1==u2);
session2.close();
}
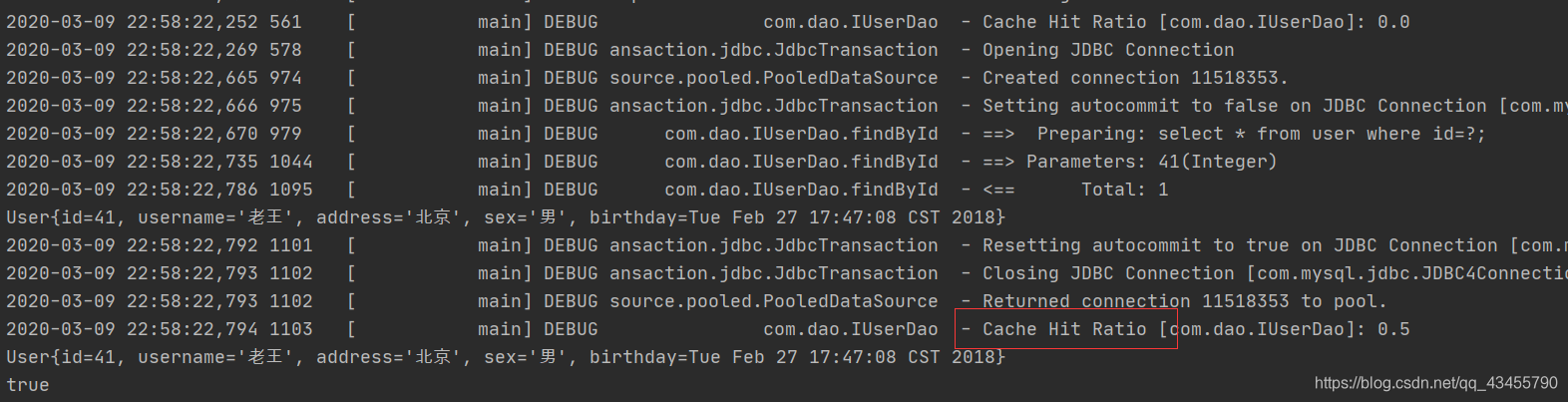
第二次查询是从二级缓存中拿到数据,并没有发送新的sql,注意:查出的数据会先默认放到一级缓存当中,只有当会话提交或者关闭时一级缓存中的数据才会转移到二级缓存当中

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









