







1 背景
Flink流任务开发完成,然后提交运行就万事大吉了吗?流任务通常是对于数据源源不断的拉取,持续不断的计算,不断更新或者产出结果,任务一旦启动,会长时间运行。所以,任务正常的运行且按照用户想要的逻辑正确的、长时间的稳定运行是流任务保障的核心诉求。
对于当前平台针对任务的运行状态变化提供了监控告警,此方式在任务停止后通知用户任务存在问题,但是任务为何停止,目前只能人工干预通过看日志、重跑任务、分析代码等方式定位,效率较低,可回溯内容较少,对于Flink机制认识不深或者不熟悉的人来说,体验较差。
是否可以在任务运行中监控数据反压情况、io使用情况、数据处理逻辑等,做到提前感知风险,提供实时告警;也可存储监控指标,协助定位问题,提供任务可检测、可维护性,答案是无疑可以的。Flink针对job,task、operate多层次提供了指标监控,可帮助我们针对任务进行全链路监控,提升任务可维护性。
当前业界也有成熟的界面方案: Prometheus(自研或其它时序数据库) + grafana(自研或者其它图表展示组件)。(查看附录链接和示意图)
平台当前任务数较少,考虑投入产出比,当前以针对用户常遇到的问题为出发点,构建监控告警项,帮助用户管理维护Flink作业。
2 Flink metric介绍
主要系统metric截图如下:

3 核心监控项
3.1 系统指标
除了以下列举的,针对自定义connector或者datastream程序可以添加业务指标,提升作业可维护性。
| 序号 | 指标类型 | 关键metric | 描述 |
| 1 | 可用性 | 如 numRestarts | The total number of restarts since this job was submitted, including full restarts and fine-grained restarts. |
| 2 | 内存 | 如 Heap.Used Heap.Max | The amount of heap memory currently used (in bytes). he maximum amount of heap memory that can be used for memory management (in bytes). |
| 3 | checkpointing | 如lastCheckpointDuration | The time it took to complete the last checkpoint (in milliseconds). |
| 4 | GC | <GarbageCollector>.Count <GarbageCollector>.Time | The total number of collections that have occurred. The total time spent performing garbage collection. |
| 5 | 流量 | 如 numBytesOutPerSecond | The number of bytes this task emits per second. |
| 6 | CPU | Status.JVM.CPU Load Status.JVM.CPU Time | The recent CPU usage of the JVM. The CPU time used by the JVM. |
| 7 | 网络 | 如numBuffersInLocalPerSecond | The number of network buffers this task reads from a local source per second. (Metrics related to data exchange between task executors using netty network communication.) |
| 8 | Connector | loopFrequencyHz | The number of calls to getRecords in one secon |
| ... | |||
| 9 | 自定义指标 | 处理逻辑耗时打点 业务出错告警 处理失败的数据占比 过滤数据统计、占比 超时丢弃数据量 等 |
3.2 监控维度
| 作业状态相关 | 作业性能相关 | 业务逻辑相关 |
| 作业故障 | 处理延迟 | 上游数据问题 |
| 运行不稳定 | 数据倾斜 | 数据丢失 |
| 影响可用性的风险因素 (cpu,内存,网络,io等) | 性能瓶颈 | 数据处理出错率高 |
3.3 监控应用场景
1、监控告警、异常上报
2、问题定位、回溯-> 智能诊断
3、智能运维(自动运维、资源优化)
4 单个作业全链路监控
平台当前任务数较少,考虑投入产出比,当前以针对用户常遇到的问题为出发点,构建监控告警项,帮助用户管理维护Flink作业。

1、第一步 核心指标监控体系
根据核心指标,构建监控项,进行监控告警配置,提升作业可维护性
如作业运行状态,数据倾斜、反压,source/sink连通性等
指标采集: metricReport & Flink rest api方式获取
示例:参考阿里dataphin

| 报警原因 | 报警规则 |
| 业务延时过高 | 当任务运行过程中的延时超过设定时间后,即可触发报警。 |
| TPS超过范围 | 当任务运行过程中的TPS(Transaction Per Second)超过设定的范围后,即可触发报警。 |
| 失败频率超过配置 | 当任务运行过程中的失败频率超过设定的频率后,即可触发报警。 |
| 数据滞留超过配置 | 当任务运行过程中的数据滞留超过设定的时间后,即可触发报警。 |
| checkpoint失败配置 | 当任务运行过程中的checkpoint连续失败超过设定的次数后,即可触发报警。 |
2、第二步 作业评估标准构建
针对作业健康值,作业风险等级的评估指标,提示用户风险,帮助用户优化作业逻辑、作业资源配置,检查运行环境稳定性。
可参考阿里“实时计算FLink”能力
示例:

3、第三步 智能诊断
可以针对收集的指标信息,对于失败的任务进行智能诊断,判断任务运行失败原因,提升问题排查速度,提升运维效率
参考“ 基于 Monitoring REST PI 的 Flink轻量级诊断”中作业诊断章节
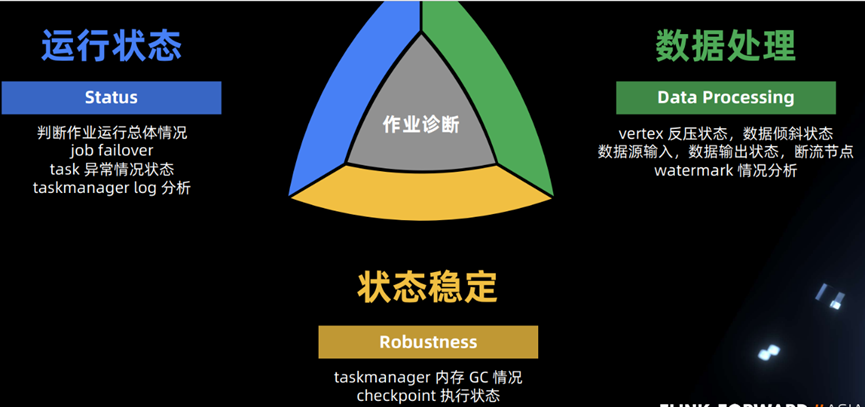
4、第四步 智能运维
针对资源,任务分配等场景,智能运维,提升作业运行效率和资源利用率等场景
此项要结合任务调度、资源调度(容器化)才可实现
附录
1、Grafana
Grafana allows you to query, visualize, alert on and understand your metrics no matter where they are stored. Create, explore, and share beautiful dashboards with your team and foster a data driven culture。
Grafana允许您查询、可视化、告警和了解您的指标,无论它们存储在何处。创建、探索并与您的团队共享漂亮的仪表板,培养数据驱动的文化。
Grafana: The open observability platform | Grafana Labs
2、Prometheus
Prometheus官网上的自述是:“From metrics to insight.Power your metrics and alerting with a leading open-source monitoring solution.”翻译过来就是:从指标到洞察力,Prometheus通过领先的开源监控解决方案为用户的指标和告警提供强大的支持。
https://prometheus.io/docs/introduction/overview/















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









