







注意:该作者博客已迁移至https://buxianshan.xyz
六行代码爬取微博热搜榜 然后为了好看又增加了几行?
然后为了好看又增加了几行?
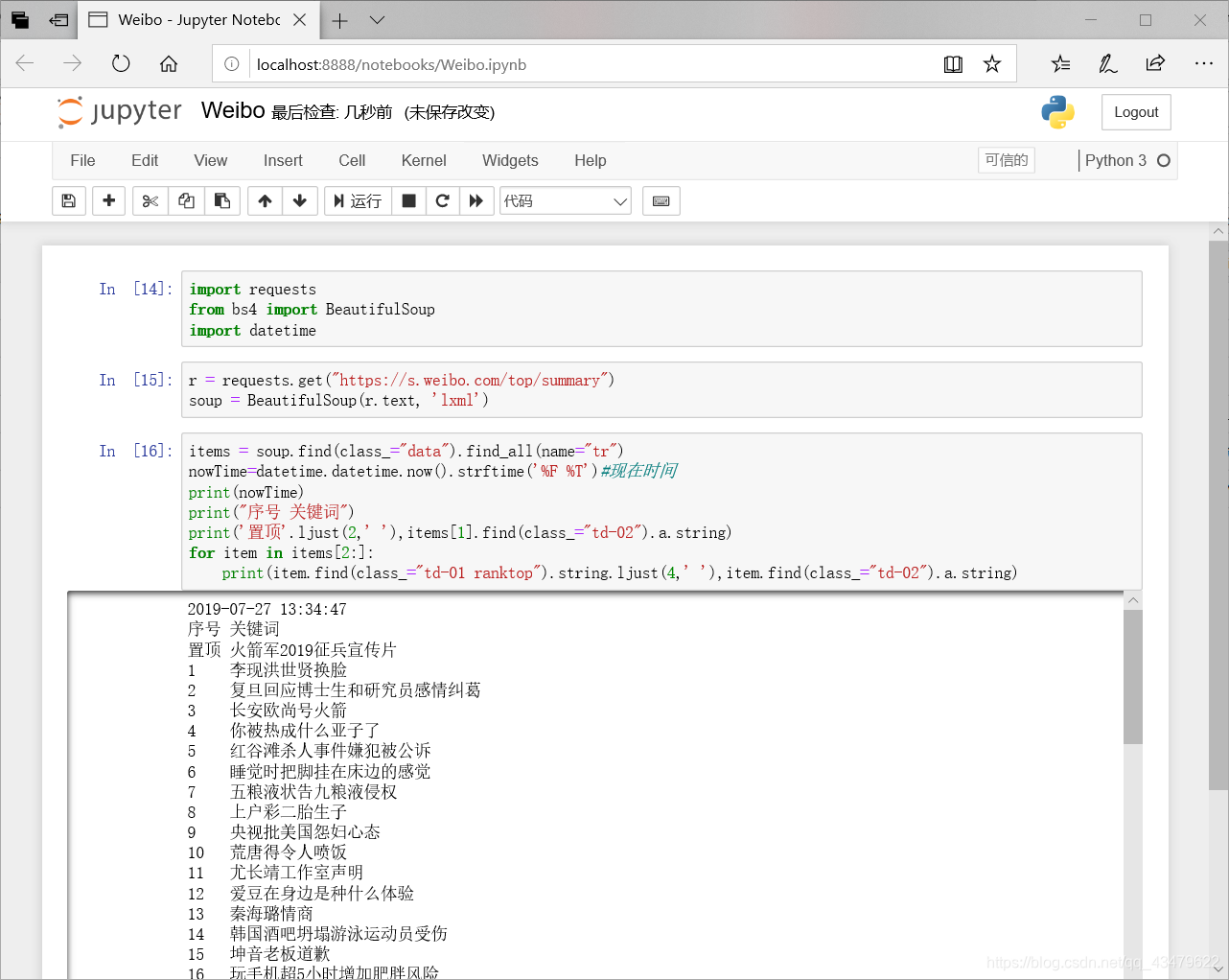
完整代码
import requests
from bs4 import BeautifulSoup
import datetime
r = requests.get("https://s.weibo.com/top/summary")
soup = BeautifulSoup(r.text, 'lxml')
items = soup.find(class_="data").find_all(name="tr")
nowTime=datetime.datetime.now().strftime('%F %T')#现在时间
print(nowTime)
print("序号 关键词")
print('置顶'.ljust(2,' '),items[1].find(class_="td-02").a.string)
for item in items[2:]:
print(item.find(class_="td-01 ranktop").string.ljust(4,' '),item.find(class_="td-02").a.string)
使用了请求库requests和解析库beautifulsoup
这一行就已经获取了热搜榜网页的源码。
r = requests.get("https://s.weibo.com/top/summary")
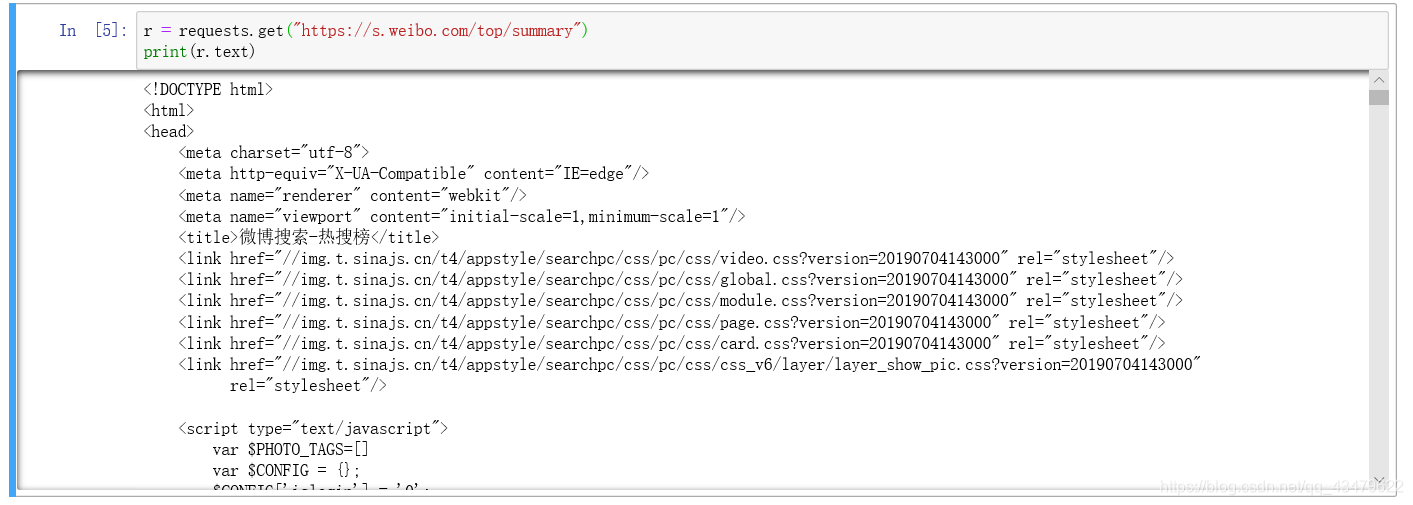
使用beautifulsoup来解析html文件
soup = BeautifulSoup(r.text, 'lxml')
看着好像没什么变化,其实已经从字符串变成可以识别html元素的对象了。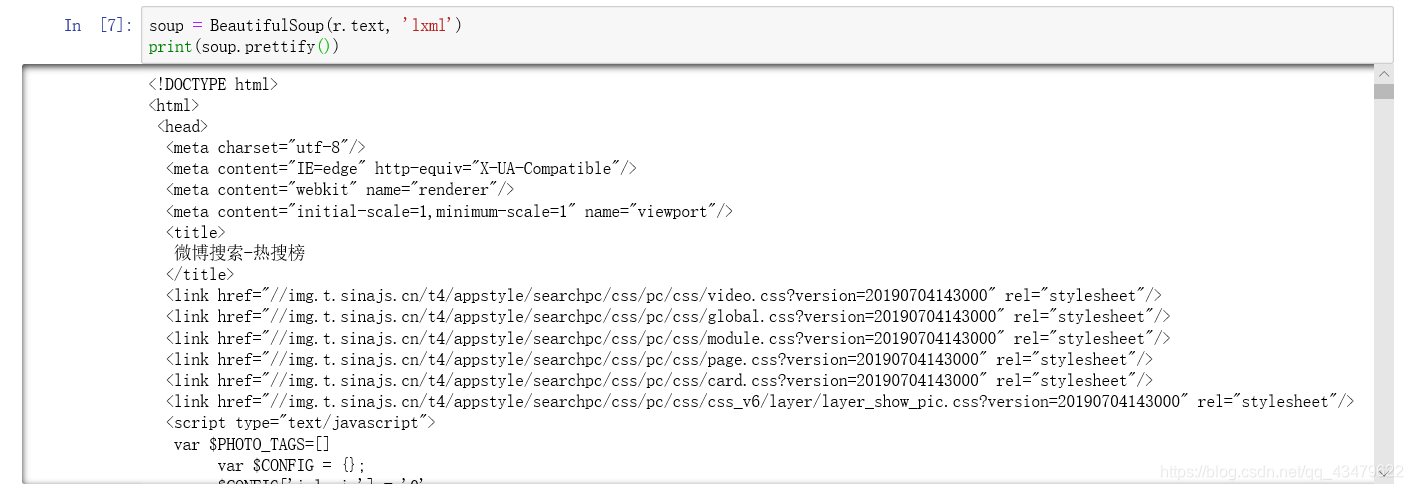
可以看到榜单的数据都在class=“data”的元素下的 tr 元素。
soup.find(class=“data”).find_all(name=“tr”),它返回的是一个列表,包含所有的tr元素,遍历来看看。
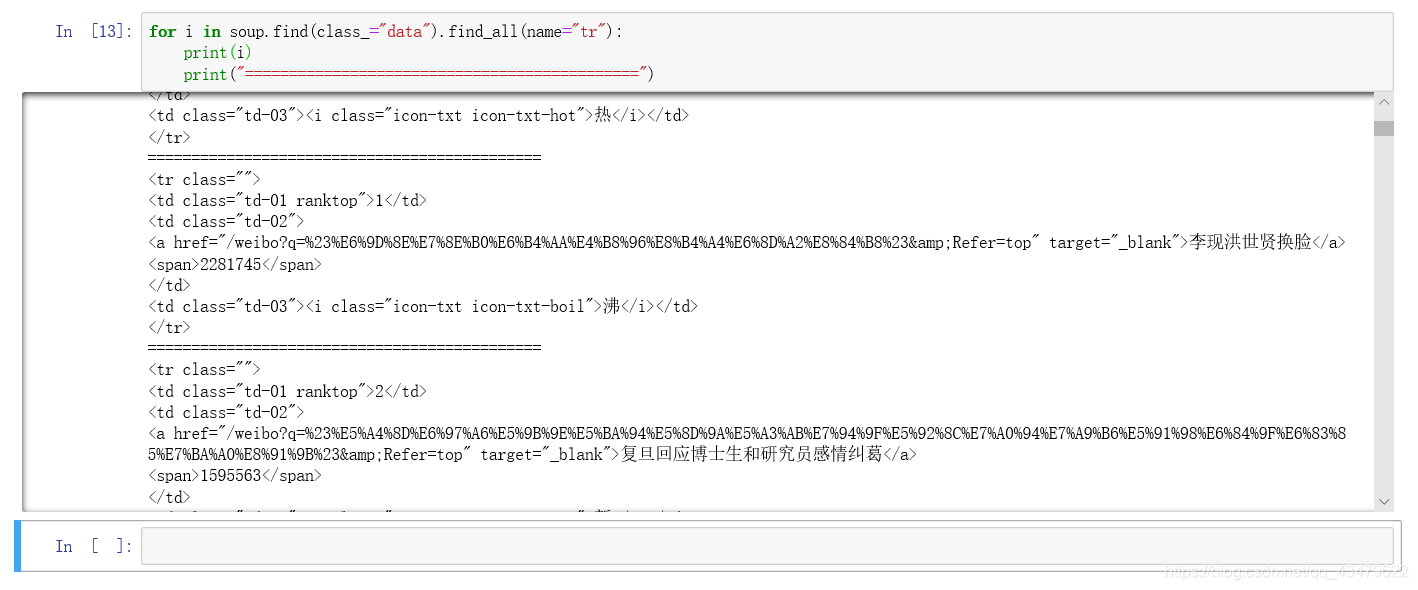
可以看到每一个热搜的内容都在tr元素里。class="td-01 ranktop"元素里是序号,class="td-02"元素里有热搜的关键词。
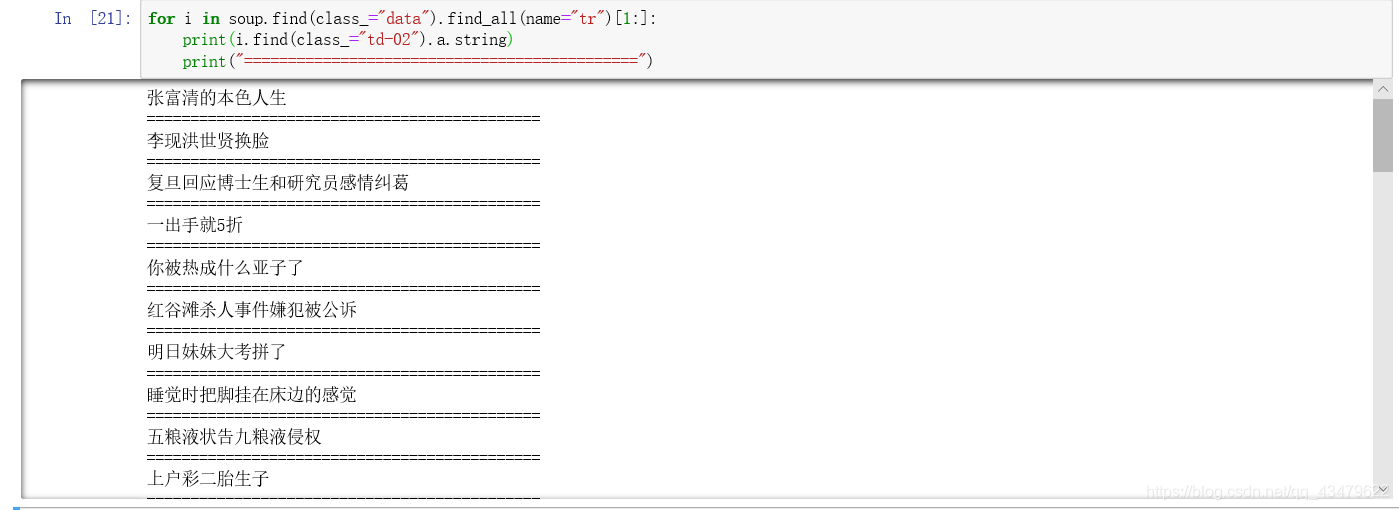
有时会报错 AttributeError: ‘NoneType’ object has no attribute ‘a’,是因为第一个tr元素里有些标签是空的,这样的单独处理就行了。其它的利用切片从第二项开始遍历。
获取其它数据方法类似,在此就不赘述了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









