







1.Redis介绍
1.1 什么是NoSql
为了解决高并发、高可扩展、高可用、大数据存储问题而产生的数据库解决方案,就是NoSql数据库。泛指非关系型的数据库,NoSQL即Not-Only SQL,它可以作为关系型数据库的良好补充。
1.2 Nosql数据库分类
- 键值(Key-Value)存储数据库
相关产品:Redis - 列存储数据库
相关产品:HBase - 文档型数据库
相关产品:MongoDB - 图形(Graph)数据库
相关产品:Neo4J
1.3 什么是Redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库。它通过提供多种键值数据类型来适应不同场景下的存储需求。
1.4 redis的应用场景
- 缓存(数据查询、短连接、新闻内容、商品内容等等)。(最多使用)
- 分布式集群架构中的session分离。
- 聊天室的在线好友列表。
- 任务队列。(秒杀、抢购、12306等等)
- 应用排行榜。
- 网站访问统计。
- 数据过期处理(可以精确到毫秒)
2. Redis在centos中安装的方法
步骤:
- 下载:wget http://download.redis.io/releases/redis-3.0.0.tar.gz
- Redis是C语言开发,安装C环境:yum install gcc-c++
- 解压缩Redis源码包: tar -zxf redis-3.0.0.tar.gz 【直接解压到当前文件夹,用户目录】
- 编译redis源码:
cd redis-3.0.0
make - 安装redis:make install PREFIX=/usr/local/redis(提前创建redis文件夹)
3. 两种启动redis的方式
3.1 前端启动(不推荐)
相关命令:
- 直接运行bin/redis-server将以前端模式启动。【bin目录是在/usr/local/redis/bin】
./redis-server - 前端启动的关闭:ctrl+c
3.2 后端启动
相关命令:
- 将redis源码包中的redis.conf配置文件复制到/usr/local/redis/bin/下:
cp redis.conf /usr/local/redis/bin/ - 修改redis.conf,将daemonize由no改为yes:
vi redis.conf - 执行命令: ./redis-server redis.conf
- 后端启动的2种关闭方式
a: ./redis-cli shutdown (推荐)
b: kill 5528
4. Redis的3种客户端模式
4.1 Redis自带的客户端
操作:
- ./redis-cli -h 127.0.0.1 -p 6379(跳到bin下,本地ip和端口可以省略)
- exit 【退出】
4.2 图形界面客户端redis-desktop-manager.exe(了解)
相关命令:
- 改防火墙端口的推荐方法,打开iptables增加对应的端口!!!
vim /etc/sysconfig/iptables - 修改后,重启防火墙就行
service iptables restart - 默认有16个数据库,切换数据库使用命令:select 数据库编号
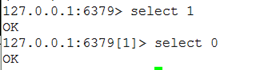
4.3 Java客户端Jedis
使用步骤:
- 在编译器里新建普通java项目,添加jar包
- 方式1:单实例连接
@Test
public void testJedis() {
jedis.select(1);//设置数据库
//创建一个Jedis的连接
Jedis jedis = new Jedis("127.0.0.1", 6379);
//执行redis命令
jedis.set("mytest", "hello world, this is jedis client!");
//从redis中取值
String result = jedis.get("mytest");
//打印结果
System.out.println(result);
//关闭连接
jedis.close();
}
- 方式2:连接池连接(推荐,性能更高)
@Test
public void testJedisPool() {
//创建一连接池对象
JedisPool jedisPool = new JedisPool("127.0.0.1", 6379);
//从连接池中获得连接
Jedis jedis = jedisPool.getResource();
String result = jedis.get("mytest");
System.out.println(result);
//关闭连接
jedis.close();
//关闭连接池
jedisPool.close();
}
- 方式3:Spring整合jedisPool(了解)
5. Redis的5种数据类型操作(重点)
注:在redis中的命令语句中,命令是忽略大小写的,而key是不忽略大小写的,以下命令是在Redis自带的客户端里操作的。
- 字符串
赋单值:SET key value
赋多值:MSET key1 value1 key2 value2 …
取单值:GET key
取多值: MGET key1 key2 …
取值并赋值(修改): GETSET key value
删除:DEL key
递增数值:INCR key
增加指定的整数:INCRBY key 数字
递减数值:DECR key
减少指定的整数 :DECRBY key decrement
应用场景:自增主键
eg:商品编号、订单号采用string的递增数字特性生成
INCR items:id
- Hash类型(解决上述字符串类型在传输、处理时造成的资源浪费)
赋单值:HSET key field value
赋多值:HMSET key field1 value1 field2 value2 …
取单值: HGET key field
取多值: HMGET key1 field1 field2 …
获取所有字段值: HGETALL key
删除一个或多个字段:HDEL key field1 field2 …
增加数字:HINCRBY key field 数字
应用场景:存储商品信息
eg:商品字段【商品id、商品名称、商品描述、商品库存、商品好评】
定义商品信息的key,商品1001的信息在 Redis中的key为:[items:1001]
HMSET items:1001 id 3 name apple price 999.9
- List
可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。列表类型内部是使用双向链表(double linked list)实现的。即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。
向列表左边增加元素:LPUSH key value1 value2 value3
向列表右边增加元素:RPUSH key value1 value2 value3
查看列表: LRANGE key start stop(索引从0开始。stop=-1表示最后一个)
从列表两端弹出(删除)元素:LPOP key RPOP key
获取列表中元素的个数:LLEN key
应用场景:商品评论列表
在Redis中创建商品评论列表
用户发布商品评论,将评论信息转成json存储到list中。
用户在页面查询评论列表,从redis中取出json数据展示到页面。
eg:定义商品评论列表key:
商品编号为1001的商品评论key【items: comment:1001】
LPUSH items:comment:1001 ‘{“id”:1,“name”:“商品不错,很好!!”,“date”:1430295077289}’
- Set
与列表不同在:集合中的数据是不重复且没有顺序
增加元素: sadd set1 a b c
删除元素:srem set1 b c
获得所有元素 : smembers set1
判断元素是否在集合中: sismember set1 a (在就返回1,不在返回0)
差集运算 A-B:sdiff setA setB(与顺序有关系,此处表示A-B)
交集运算 A ∩ B: sinter setA setB
并集运算 A ∪ B: sunion setA setB
- SortedSet(zset)
在集合类型的基础上,有序集合类型为集合中的每个元素都关联一个分数,这使得我们不仅可以完成插入、删除和判断元素是否存在在集合中,还能够获得分数最高或最低的前N个元素、获取指定分数范围内的元素等与分数有关的操作。有序集合类型使用散列表实现,所有即使读取位于中间部分的数据也很快,不过有序集合要比列表类型更耗内存。
增加元素: zadd scoreboard 80 zhangsan 89 lisi 94 wangwu
获取元素的分数: zscore scoreboard wangwu
删除一个或多个元素: zrem scoreboard lisi
获得排名在某个范围的元素列表: zrange scoreboard 0 2(默认从小到大)zrevrange scoreboard 0 2(从大到小)
获得元素的分数:可以在命令尾部加上WITHSCORES参数
应用场景:商品销售排行榜
eg:需求:根据商品销售量对商品进行排行显示
思路:定义商品销售排行榜(sorted set集合),Key为items:sellsort,分数为商品销售量。
写入商品销售量:
商品编号1001的销量是9,商品编号1002的销量是10
ZADD items:sellsort 9 1001 10 1002
商品编号1001的销量加1
192.168.101.3:7001> ZINCRBY items:sellsort 1 1001
商品销量前10名:
192.168.101.3:7001> ZRANGE items:sellsort 0 9 withscores
6. Keys命令(了解)
Redis在实际使用过程中更多的用作缓存,然而缓存的数据一般都是需要设置生存时间的,即:到期后数据销毁。
命令:
EXPIRE key seconds 设置key的生存时间(单位:秒)key在多少秒后会自动删除
TTL key 查看key生于的生存时间
PERSIST key 清除生存时间
PEXPIRE key milliseconds 生存时间设置单位为:毫秒
7. Redis的两种持久化方案
7.1 RDB持久化(默认方式)
通过快照(snapshotting)完成的,当符合一定条件时Redis会自动将内存中的数据进行快照并持久化到硬盘。
“save 900 1”表示15分钟(900秒钟)内至少1个键被更改则进行快照。
缺陷:一旦Redis异常退出,就会丢失最后一次快照以后更改的所有数据。如果数据很重要以至于无法承受任何损失,则可以考虑使用AOF方式进行持久化。
7.2 AOF持久化(操作一次就写一次数据)
- 通过修改redis.conf配置文件中的appendonly参数开启:
appendonly yes - 重启服务,再添加数据,然后会有一个aof文件:
./redis-cli shutdown
./redis-server redis.conf
./redis-cli
8. Redis的主从复制(掌握)
8.1 主从复制的介绍
持久化保证了即使redis服务重启也不会丢失数据,因为redis服务重启后会将硬盘上持久化的数据恢复到内存中,但是当redis服务器的硬盘损坏了可能会导致数据丢失,如果通过redis的主从复制机制就可以避免这种单点故障,解决上述RDB持久化的缺陷。



8.2 主从配置步骤
- 安装redis,原文件作为主机,复制多份主机作为从机
cp bin/ bin2 –r
- 修改从机的redis.conf,配置slaveof 为主机的ip地址和端口号

- 在redis.conf中修改从机的port地址为6380

- 清除从机中的持久化文件
rm -rf appendonly.aof dump.rdb
- :启动从机【一定要使用配置文件启动,否则还是使用默认的端口】
./redis-server redis.conf (查看两个端口启动情况:ps -ef|grep redis) - 启动6380的客户端
./redis-cli -p 6380
注意:主机一旦发生增删改操作,那么主机会将数据同步到从机中从机不能执行写操作
9. Redis集群
9.1 redis-cluster【集群】架构图
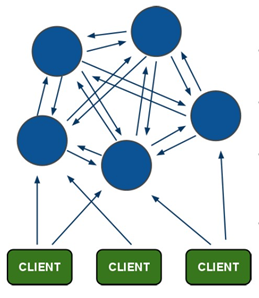
解释:所有的redis节点彼此互联,不需要中间proxy层(即之前学的Nginx代理),客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
9.2 搭建Ruby环境(集群管理工具)
安装步骤:
- 安装ruby:
yum install ruby
yum install rubygems
- 使用filezilla工具上传redis-3.0.0.gem至/usr/local下
- 安装ruby和redis的接口程序:
gem install /usr/local/redis-3.0.0.gem
- 将Redis集群搭建脚本文件复制到/usr/local/redis/redis-cluster目录下:
cp redis-trib.rb /usr/local/redis/rediscluster/ -r (ll *.rb【查看rb文件)
9.3 集群的搭建过程
说明:搭建集群最少也得需要3台主机,如果每台主机再配置一台从机的话,则最少需要6台机器。
以下例子按端口设计如下:7001-7006
- 复制出一个7001机器,创建7001,7002,…7006文件夹
cp bin ./redis-cluster/7001 –r
- 如果存在持久化文件,则删除:rm -rf appendonly.aof dump.rdb
- 设置集群参数

- 修改端口
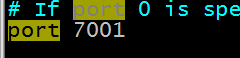
- 复制出7002-7006机器
cp 7001/ 7002 -r
cp 7001/ 7003 -r
cp 7001/ 7004 -r
cp 7001/ 7005 -r
cp 7001/ 7006 –r
- 修改7002-7006机器的端口
- 使用脚本批量启动7001-7006这六台机器
创建脚本文件startall.sh,vim 打开,粘贴单个启动的命令,然后保存退出,给文件增加执行权限
即:[root@A001redis-cluster]#vi startall.sh chmod u+x startall.sh ./startall.sh
- 创建集群
./redis-trib.rb create --replicas 1 192.168.237.131:7001 192.168.237.131:7002 192.168.237.131:7003 192.168.237.131:7004 192.168.237.131:7005 192.168.237.131:7006 - 连接集群
./redis-cli –h 127.0.0.1 –p 7001 -c【c表示集群方式连接】
- 查看集群状态:cluster info
- 查看集群中的节点:cluster nodes
10. Jedis连接集群
步骤:
- 防火墙配置:
service iptables stop
vim /etc/sysconfig/iptables 添加7001到7006的端口
service iptables restart
- 代码实现:
创建JedisCluster类连接redis集群
@Test
public void testJedisCluster() throws Exception {
//创建一连接,JedisCluster对象,在系统中是单例存在
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("127.0.0.1", 7001));
nodes.add(new HostAndPort("127.0.0.1", 7002));
nodes.add(new HostAndPort("127.0.0.1", 7003));
nodes.add(new HostAndPort("127.0.0.1", 7004));
nodes.add(new HostAndPort("127.0.0.1", 7005));
nodes.add(new HostAndPort("127.0.0.1", 7006));
JedisCluster cluster = new JedisCluster(nodes);
//执行JedisCluster对象中的方法,方法和redis一一对应。
cluster.set("cluster-test", "my jedis cluster test");
String result = cluster.get("cluster-test");
System.out.println(result);
//程序结束时需要关闭JedisCluster对象
cluster.close();
}
补:也可以使用spring,这里自己查
总结
Redis是学习的第一个NoSql数据库,主要用于做缓存,基于键值对的特性存值,方便查询数据,可以用于电商平台,会使用它的5种基本数据类型,包括字符串,hash,list,set.SortedSet;他们都有自己的特性,比如列表和有序集合是有序的,集合set是唯一,无序的。另外还掌握了两种持久化方案,但都有确定,性能和安全不能兼得;因此,主从复制可以很好的解决这个问题,主要熟悉主从机的概念以及搭建的步骤,最后学习了Redis集群的搭建,极大的提升了系统的性能和安全。总之,Redis比之前学习的ehcache效率更好,至于其他的NoSql数据库,例如基于文档型数据库MongoDB,可以在需要的时候看一下,Redis与之相比各有优缺点。本教程是从初学者的角度出发,写的很细,希望对你有帮助,坚持记录知识,传递知识,共同提高!















 2219
2219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









