






接下来写的内容是看过众多大神的文章后,自己总结的一些心得体会,主要是为了让大家快速理解HashMap,应付面试百分百足矣。
当然讲HashMap之前必须先讲一些必备知识(等你回答完面试官问题,再深入问下去的时候,这些知识可以防止露馅):
map的定义
首先你要知道什么是map,map就是用于存储键值对(<key,value>)的集合类,也可以说是一组键值对的映射(数学概念)。注意,我这里说的只是map的概念,是为了通俗易懂,面试时候方便记忆,但是你自己一定要明白,在java中map是一个接口,是和collection接口同一等级的集合根接口。
map的存储结构

上边这个图就是map的存储结构,没错,看起来就像是数据库中的关系表,有两个字段(或者说属性),keyset(键的集合)和values(值的集合),每一条记录都是一个entry(一个键值对)。
Map的特点
1.没有重复的 key(一方面,key用set保存,所以key必须是唯一,无序的;另一方面,map的取值基本上是通过key来获取value,如果有两个相同的key,计算机将不知道到底获取哪个对应值;这时候有可能会问,那为什么我编程时候可以用put()方法传入两个key值相同的键值对?那是因为源码中,传入key值相同的键值对,将作为覆盖处理)
2.每个 key 只能对应一个 value, 多个 key 可以对应一个 value(这就是映射的概念,最经典的例子就是射箭,一排射手,一排箭靶,一个射手只能射中一个箭靶,而每个箭靶可能被不同射手射中。这里每个射手只有一根箭,不存在三箭齐发还都中靶这种骚操作。将射手和射中的靶子连线,这根线加射手加靶子就是一个映射)
3.key,value 都可以是任何引用类型(包括 null)的数据(只能是引用类型)
4.Map 取代了古老的 Dictionary 抽象类(知道就行,可以忽略)
哈希全家桶
把任意长度的输入(输入叫做预映射,知道就行),通过一种函数(hashCode() 方法),变换成固定长度的输出,该输出就是哈希值(hashCode),这种函数就叫做哈希函数,而计算哈希值的过程就叫做哈希。哈希的主要应用是哈希表和分布式缓存。
这里有个问题,哈希算法和哈希函数不是一个东西,哈希函数是哈希算法的一种实现,以后面试就说哈希函数就行。
在将键值对存入数组之前,将key通过哈希算法计算出哈希值,把哈希值作为数组下标,把该下标对应的位置作为键值对的存储位置,通过该方法建立的数组就叫做哈希表,而这个存储位置就叫做桶(bucket)。数组是通过整数下标直接访问元素,哈希表是通过字符串key直接访问元素,也就说哈希表是一种特殊的数组(关联数组),哈希表广泛应用于实现数据的快速查找(在map的key集合中,一旦存储的key的数量特别多,那么在要查找某个key的时候就会变得很麻烦,数组中的key需要挨个比较,哈希的出现,使得这样的比较次数大大减少。)
哈希表选用哈希函数计算哈希值时,可能不同的 key 会得到相同的结果,一个地址怎么存放多个数据呢?这就是哈希冲突(碰撞)。解决哈希冲突有两种方法,拉链法(链接法)和开放定址法(这种没用过)。拉链法:将键值对对象封装为一个node结点,新增了next指向,这样就可以将碰撞的结点链接成一条单链表,保存在该地址(数组位置)中。
正文
HashMap的定义
先从HashMap的定义开始,HashMap是用哈希表(直接一点可以说数组加单链表)+红黑树实现的map类。

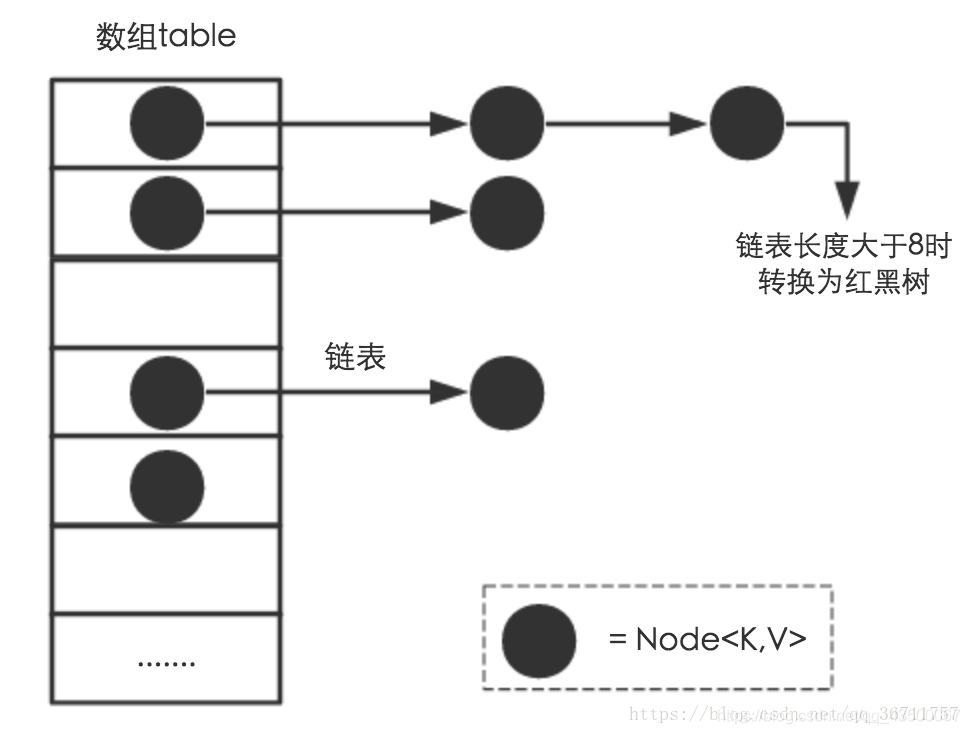
HashMap的存储结构
上图便是HashMap的存储结构,HashMap的这种特殊存储结构在获取指定元素前需要把key经过哈希运算,得到目标元素在哈希表中的位置,然后再进行少量比较即可得到元素,这使得 HashMap 的查找效率极高。(说白了HashMap就是用了拉链法的哈希表,也有叫桶数组的)
烧脑部分
哈希函数计算结果越分散均匀,哈希碰撞的概率就越小,map的存取效率(时间复杂度)就会越高。
哈希表长度越长,空间成本越大,哈希函数计算结果越分散均匀。
扩容机制(实际上就是负载因子)和哈希函数越合理,空间成本越小,哈希函数计算结果越分散均匀。
从HashMap的默认构造函数源码可知,构造函数就是对下面几个字段进行初始化。
负载因子越大(长度一定),最大结点容量越大,resize次数越少,空间成本越小,map的存取效率就会越高。
桶数组初始容量(长度)越大(加载因子一定),最大结点容量越大,resize次数越少,空间成本越大,map的存取效率就会越高。
int threshold; // 最大node结点(键值对)容量,threshold = CAPACITY * LoadFactor,超过这个数目就重新resize(扩容),扩容后的threshold是之前的两倍。
final float loadFactor; // 加载因子(HashMap默认值是0.75,建议不要修改)
int modCount; // 记录HashMap内部结构发生变化的次数,强调一点,内部结构发生变化指的是结构发生变化,例如put新键值对,但是某个key对应的value值被覆盖不属于结构变化。
int size,CAPACITY; // CAPACITY是桶数组的容量(桶的多少)(默认值是16),扩容后也是之前的两倍,size是HashMap中实际存在的键值对数量
这里存在一个问题,即使负载因子和哈希函数设计的再合理,也免不了会出现拉链过长(桶内结点过多)的情况,一旦出现拉链过长,则会严重影响HashMap的性能。于是,在JDK1.8版本中,对数据结构做了进一步的优化,引入了红黑树。而当链表长度太长(默认超过8)时,链表就转换为红黑树,利用红黑树快速增删改查的特点提高HashMap的性能
HashMap的特点
底层实现是 链表数组,JDK 8 后又加了 红黑树
实现了 Map 全部的方法
key 用 Set 存放,所以想做到 key 不允许重复,key 对应的类(一般是String)需要重写 hashCode 和 equals 方法
允许空键和空值(但空键只有一个,且放在第一位,知道就行)
元素是无序的,而且顺序会不定时改变(每次扩容后,都会重新哈希,也就是key通过哈希函数计算后会得出与之前不同的哈希值,这就导致哈希表里的元素是没有顺序,会随时变化的,这是因为哈希函数与桶数组容量有关,每次结点到了临界值后,就会自动扩容,扩容后桶数组容量都会乘二,而key不变,那么哈希值一定会变)
插入、获取的时间复杂度基本是 O(1)(前提是有适当的哈希函数,让元素分布在均匀的位置)
遍历整个 Map 需要的时间与数组的长度成正比(因此初始化时 HashMap 的容量不宜太大)
两个关键因子:初始容量、加载因子
HashMap不是同步,HashTable是同步的,但HashTable已经弃用,如果需要线程安全,可以用synchronizedMap,例如 Map m = Collections.synchronizedMap(new HashMap(…));
方法
遍历方法
1.可以采用keySet()+for循环的方法来遍历,keySet()返回的是一个Key值的集合

2.采用EntrySet()+Iterator进行遍历,EntrySet()返回的是一个Map.Entry的一个集合,它提供getKey(),getValue()方法来获取键值对。

3.直接采用EntrySet+for增强进行遍历

4.取出所有value的值,但是不能取出KEY值

HashMap 的 4 个构造方法
//创建一个空的哈希表,初始容量为 16,加载因子为 0.75
public HashMap()
//创建一个空的哈希表,指定容量,使用默认的加载因子
public HashMap(int initialCapacity)
//创建一个空的哈希表,指定容量和加载因子
public HashMap(int initialCapacity, float loadFactor)
//创建一个内容为参数 m 的内容的哈希表
public HashMap(Map<? extends K, ? extends V> m)
添加方法
//添加指定的键值对到 Map 中,如果已经存在,就替换
public V put(K key, V value)
逻辑如下
先调用 hash() 方法计算哈希值
然后调用 putVal() 方法中根据哈希值进行相关操作
如果当前 哈希表内容为空,新建一个哈希表
如果要插入的桶中没有元素,新建个节点并放进去
否则从桶中第一个元素开始查找哈希值对应位置
如果桶中第一个元素的哈希值和要添加的一样,替换,结束查找
如果第一个元素不一样,而且当前采用的还是 JDK 8 以后的树形节点,调用 putTreeVal() 进行插入
否则还是从传统的链表数组中查找、替换,结束查找
当这个桶内链表个数大于等于 8,就要调用 treeifyBin() 方法进行树形化
最后检查是否需要扩容
注
hash():计算对应的位置
resize():扩容
putTreeVal():树形节点的插入
treeifyBin():树形化容器
获取方法
public V get(Object key)
如果 HashMap 中包含一个键值对 k-v 满足:
(key == null ? k == null : key.equals(k))
1
2
就返回值 v,否则返回 null;
逻辑如下
先计算哈希值;
然后再用 (n - 1) & hash 计算出桶的位置;
在桶里的链表进行遍历查找。
主要方法(map接口)

转自以下博客:















 196
196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}