






文章目录
1. 需求背景(可跳过)
在标准的采购流程管理中有一处为“供应商配额管理”的模块,见名知意,就是控制时间段内供应商的配额比例(合计100%)。
例如:(数据样例)

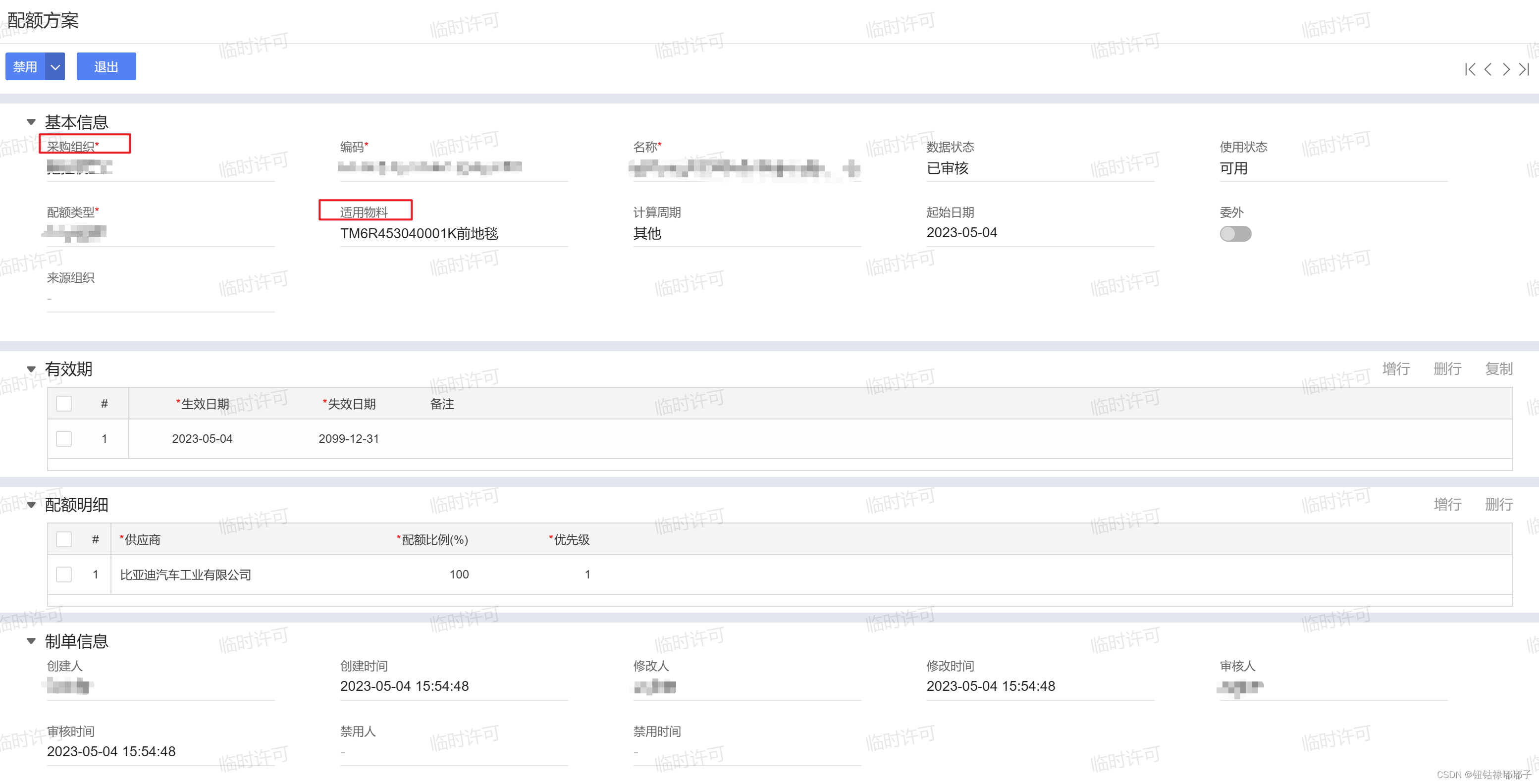
1.1 原方案数据库表设计:单据表头记录采购组织、物料等信息,表头关联表中记录时间段信息,时间段表的关联表记录供应商信息(这里只介绍核心业务数据结构)
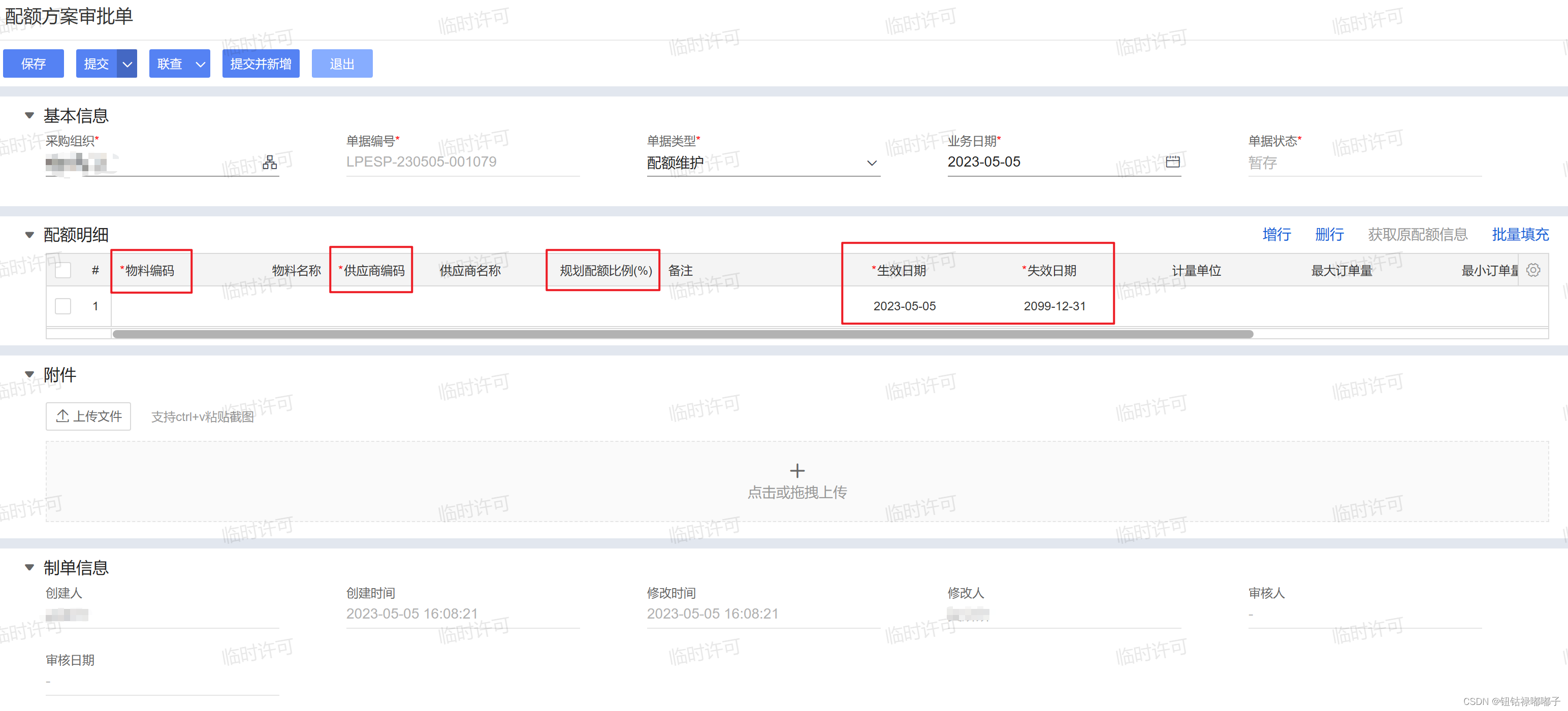
1.2 数据流向变更:在以物料为核心的原设计背景下,根据客户的实际需求需要增加一张前置单据。该单据需要支持 “多物料,多时间段,多供应商” 批量录入信息。
(由于后续业务与 “配额” 原单数据关联复杂,增加前置单据既可以满足需求,又可以保证最小化改动)
2. 思路整理(可跳过)
变化方向主要为以下两点(此次前置单据的增加不仅是数据流入和物料维度的变化,也是对原方案“校验逻辑” 和 “更新时间段” 逻辑的补充):
2.1 校验逻辑增加:数据流入的变化为“单物料,多时间段,多供应商” ——> “多物料,多时间段,多供应商”,且由三层表结构打平为一层
2.2 增加时间段重合的处理逻辑(后续有详细说明)
3. 方案介绍(重点)
`
首先,我们可以先列举时间段更新时间段的几种情景:
可以想到这样一种场景,两列列车相向行驶,一辆列车有7节车厢,另一辆则为8节,他们形驶而过的整个过程,共有多少种情况?
结果是5种

如果两辆列车长度交换,则会新增一种情况

如果两辆列车长度相等,则又会多出一种情况

根据上述列举,我们可以结论:时间段更新时间段共有7种场景
可以看到,不同场景可以根据两段时间段的头尾比较来确定
- 倘若在界面一行行新增数据,我们可以通过获取前台用户输入的值变更来校验数据,即:
判断当前 “新增行的生效日期” 是否小于等于 “其他行的失效日期”" 且 “新增行的失效日期” 是否大于等于 “其他行的生效日期”
如果满足,则不允许新增,抛出异常 - 倘若用户通过excel导入数据,我们则需要处理这7种时间段的数据。
我们假设下面的列车是要更新的数据,上面的列车是待更新数据。
如果是左不相交,则不需要做处理
如果是左相交,则更新上时间段的失效日期为:下时间段的生效日期-1
如果是下包含,则删除原时间段及关联数据,新增下时间段
如果是右相交,则更新上时间段的生效日期为:下时间段的失效日期+1
如果是右不相交,则不需要做处理
如果是上包含,则需要将时间段裁成三段,
第一段为更新上时间段的失效日期为:下时间段的生效日期-1
新增下时间段
新增数据:生效日期为下时间段的失效日期+1,失效日期为上时间段的失效日期
如果是完全重合,删除上时间段,新增下时间段
这是单条时间段更新单条时间段的逻辑,如果是多条更新多条呢?
其实也是相同的逻辑。
我们将原时间段数据从数据库取出,到内存中计算,遍历待新增的时间段和原时间段逐一匹对处理后,内存会生成新的多时间段数据行。for循环中下一行待新增的时间段,将会是和这一新的多时间段数据行逐一匹对。
于是,“多条更新多条” 的逻辑就为:遍历新时间段 + 内循环原时间段 + “单条时间段更新单条时间段”逻辑(复杂度N^2)
本质相同
4. 多维度校验处理
对于录入数据的校验,原始需求为:物料在相同时间段内的供应商比例之和必须为100
对于接收到的需求,我们一般会如何进行代码的编写?
利用hashmap存储数据,key为物料编码+开始时间+结束时间 value为供应商比例之和
最终校验是否所有value都为100
但我们再回顾一遍需求背景,录入的数据是否会存在如下情况:
数据:
物料A 2023.1.1-2023.12.30 供应商A 配额比例100%
物料A 2023.6.1-2024.12.30 供应商B 配额比例100%
对于这样的数据,6.1-12.30时间段内,供应商比例>100,但仍旧可以顺利的通过校验
于是我们需要重新调整需求描述,设计新的解决问题方案。
新方案如下:
方案一:
先校验时间重合性,再校验供应商比例之和
2023.1.1-2023.12.30和2023.6.1-2023.12.30明显存在时间重合,不会通过校验
方案二:
将时间段拆分到“天”的颗粒度,再分别计算每天的供应商比例之和
2023.1.1-2023.12.30会被拆分成365条数据, 2023.6.1-2024.12.30会被拆分成183条数据,再分别计算每天之和
2023.1.1-2023.12.30和2023.6.1-2023.12.30明显存在时间重合,不会通过校验
两方案优劣对比:
方案一优势:
- 可以复用时间段重合代码,编写难度低
- 校验方案清晰,便于修改
方案一劣势:
- 对于如下数据,方案一不会通过校验
物料A 2023.1.1-2023.12.30 供应商A 配额比例50%
物料A 2023.1.1-2023.05.31 供应商B 配额比例50%
物料A 2023.6.1-2024.12.30 供应商B 配额比例50%
由于存在时间段重合,方案一对该数据组不会通过校验
方案二优势:
- 可以解决方案二劣势中例举的数据组合
- 方案逻辑清晰,代码方案清晰
方案二的代码方案设计如下:
将一行数据拆分为“天”颗粒度,同时将拆分后的数据存储至数据库中,并将数据按物料+时间进行排序。在提交校验时,group by物料+时间,计算供应商比例之和是否为100
方案二劣势:
- 从方案设计、代码设计中都可以看出,如果客户录入的数据量非常庞大时,我们需要多出至少100、200倍的数据行存储至数据库中。这无疑会指数级得增加表中数据量,且增大内存计算的压力。
并且该方案也存在一个隐藏的逻辑问题:上午客户录入数据至系统中后,发现录入的数据存在错误,需要重新录入。
如:
原数据:物料A 2023.1.1-2023.12.30 供应商A 配额比例100%
修改后:物料A 2023.1.1-2023.06.30 供应商A 配额比例100%
那么此时,数据库中会同时存在由2023.1.1-2023.06.30拆分后的183*2条数据,且该期间内比例之和为200%
可能会有人提出,可以将拆分后的数据存储至另一数据库表中,并在执行成功后及时清理数据。
那么方案二的两个劣势问题都可以解决。
但在实际情况中,存在一个每晚11:55的定时任务,去根据录入的信息去更新其他数据。逻辑大体相同
且倘若客户批量录入的单张表单数据量达到万条,数据量成百倍增长带来的内存计算压力仍旧难以缓解
比较两个方案后,我们认为:
技术是为业务服务的
但适当的业务需求让步,可以避免技术上的过分设计。
选择方案一
总结:多维度校验的逻辑,通常都可以根据具体业务,采用逐个验证的方案解决
5. 补充
问题一:在原方案中用户通过excel导入数据,就不需要处理这7种时间段的数据了么?
回答:需要。在后续中,将项目上的经验进行总结后也修改了平台功能。这就是ToB需要进项目的原因之一吧。
问题二:既然原方案也需要这一逻辑,为什么不在文章分享中,只介绍更新后的原方案逻辑?
回答:因为贪心,想顺带讲一嘴多维度校验处理。















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









