







口扫模型分割为多个子模型
由于需要对口扫模型的分类结果进行展示,一个比较好的展示形式是选择不同的分类,就对分类出来的那个部位进行高亮或者单独显示。
这一部分工作从项目开始第一周就已经提出,但是迟迟未能够完成,为此我开始着手这一部分的工作。
对一个完整的模型进行某一部分的高亮的和单独显示比较困难,这也是工作迟迟未完成的原因之一。为此采取折中方案,使用python程序将完整的整个模型进行划分,生成多个不同部位的模型子文件,再在前端选择显示不同的子文件,这样能够方便快速的完成模型部位的高亮和单独显示。
为此编写了以下的python代码,将完整的口扫模型文件读入,并且根据分类的label文件,将模型的点和面片以不同的label划分到不同的部位的模型子文件中。这里读入的口扫模型文件需要是off格式的,为此如果上传的是其他格式的模型文件,必须要转化为off格式再进行代码的调用。生成的子文件格式也为off格式
另外根据lbw同学那边的反馈,前端对于off文件的导入并展示由于缺少相应的支持很困难,为此生成的子文件还需要调用相应的库函数从off文件转换到stl格式文件
下面是模型分割的代码:
# 模型原off文件路径
sourceModlePath = "C:\\Users\\Lenovo\\Desktop\\作业\\暑期项目实训\\示例数据\\示例数据1\\caihaoyang13157\\13157_caihaoyang_2018-12-13\\UpperJaw.off"
# 模型经过分类之后的label文件位置
classLabelFilePath = "C:\\Users\\Lenovo\Desktop\\作业\\暑期项目实训\\示例数据\\示例数据1\\caihaoyang13157\\13157_caihaoyang_2018-12-13\\UpperJaw\\seg.final"
# 分割出来的不同部位的子模型文件的文件夹路径
childModelDirPath = "C:\\Users\\Lenovo\\Desktop\\作业\\暑期项目实训\\示例数据\\示例数据1\\caihaoyang13157\\13157_caihaoyang_2018-12-13\\UpperJaw\\childModel"
with open(sourceModlePath, "r") as f:
with open(classLabelFilePath, "r") as cf:
line = f.readline() # 整行读取数据
print(line)
pointNumStr = f.readline()
strs = pointNumStr.split()
pointNum = int(strs[0]) # off文件顶点数目
surfaceNum = int(strs[1]) # off文件面数
print(pointNum)
print(surfaceNum)
classFilePointNum = int(cf.readline())
print(classFilePointNum)
if pointNum != classFilePointNum:
print("ERRRRRRRRRRRRRRR!!!!!")
labelArray = []
diffClass = {}
pointsArray = []
# 读取顶点
for i in range(pointNum):
point = {}
pointPosStr = f.readline()
pointPosStrs = pointPosStr.split()
pointLabel = cf.readline()
label = int(pointLabel)
point["x"] = float(pointPosStrs[0])
point["y"] = float(pointPosStrs[1])
point["z"] = float(pointPosStrs[2])
point["label"] = label # 点的标签
if label not in labelArray:
labelArray.append(label)
diffClass[label] = {"points": [], "surfaces": []}
point["classId"] = len(diffClass[label]["points"]) # 点在该标签下点的ID
diffClass[label]["points"].append(point)
pointsArray.append(point)
# print(diffClass[0])
print(labelArray)
print(len(labelArray))
for i in range(surfaceNum):
surfacePointStr = f.readline()
surfacePointStrArray = surfacePointStr.split()
surfacePointNum = int(surfacePointStrArray[0])
surfacePointsId = [] # 转换后面的顶点编号数组
surfaceLabels = []
for j in range(1, surfacePointNum+1):
pointId = int(surfacePointStrArray[j]) # 面上顶点的ID
pointLabel = pointsArray[pointId]["label"] # 该顶点所属的类别
if pointLabel not in surfaceLabels:
surfaceLabels.append(pointLabel)
surfacePointsId.append(pointsArray[pointId]["classId"]) # 得到在新标签下的ID
if len(surfaceLabels) == 1:
diffClass[surfaceLabels[0]]["surfaces"].append(surfacePointsId)
for label in labelArray:
print(label)
# 写入对应的部分模型文件当中
txtName = "codingWord.txt"
file = open(childModelDirPath + '\\class_' + str(label) + '.off', 'w')
file.write('OFF\n')
file.write("" + str(len(diffClass[label]["points"])) + " " + str(len(diffClass[label]["surfaces"])) + " 0\n")
for i in range(len(diffClass[label]["points"])):
file.write(str(diffClass[label]["points"][i]["x"]) + " " + str(diffClass[label]["points"][i]["y"]) + " " + str(diffClass[label]["points"][i]["z"]) + "\n")
for i in range(len(diffClass[label]["surfaces"])):
surfacePointNum = len(diffClass[label]["surfaces"][i])
file.write(str(surfacePointNum))
for j in range(surfacePointNum):
file.write(" " + str(diffClass[label]["surfaces"][i][j]))
file.write("\n")
file.close()
部位高亮效果:
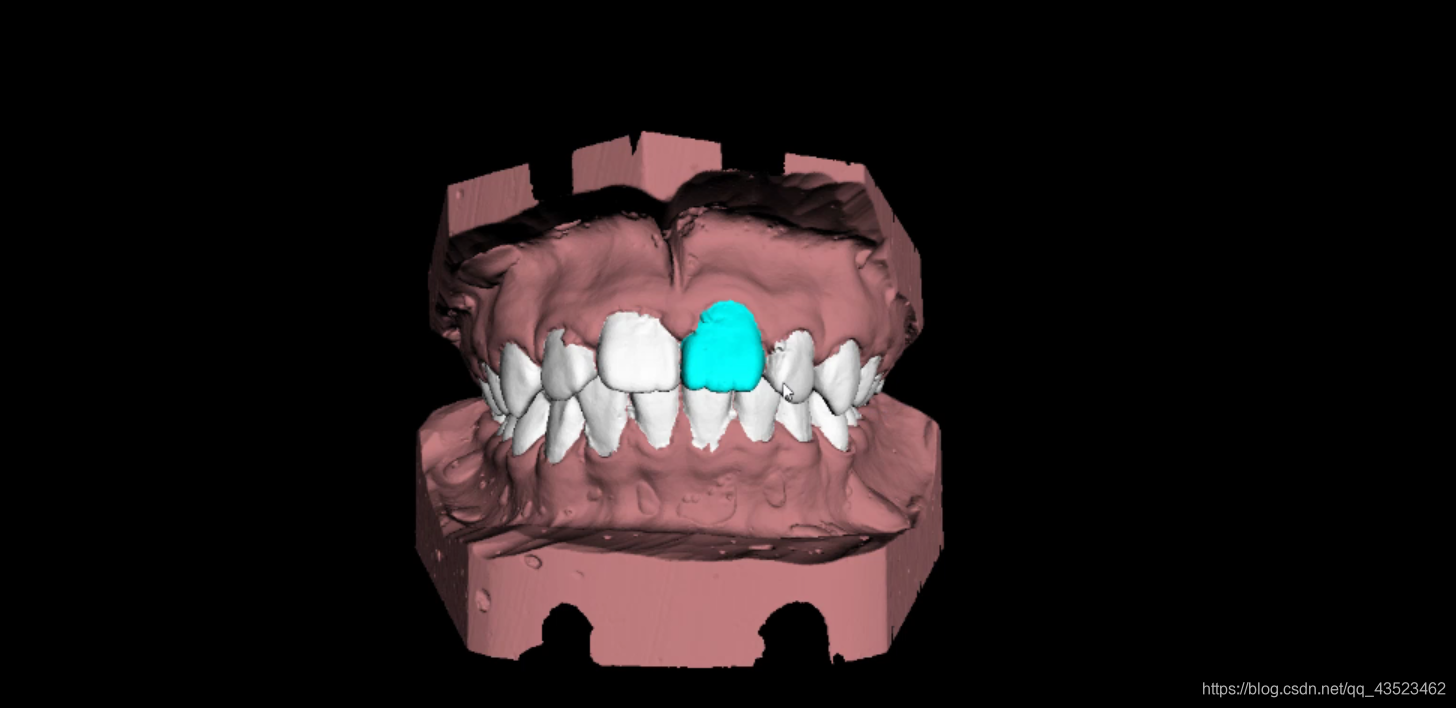
模型单独显示效果:

可以看到效果不错,工作完成的还可以。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









