







使用库:
引用jieba库:jieba是优秀的中文分词第三方库,需要额外安装。
《大秦帝国(1-6)》:(.txt)
链接:https://pan.baidu.com/s/15WTtIrVXJsLH7I7dXzZDgA 提取码:maag
Python代码:
#分析排在前面的人物出场次数顺序 及七国的出场次序(共二十位)
import jieba
txt=open("F:\\WinterVacation\\大秦帝国1-6 孙皓晖.txt","r",\
encoding="gb18030").read()
excludes={"没有","一个","便是","已经","将军","如何","如此","天下",\ #去掉无用的词
"确是","立即","自己","一声","竟是","却是","秦王","丞相",\ #排第一位的“没有”为8079次
"秦军","不能","这个","大军","起来","之后","先生","一片",\
"咸阳","老夫","大臣","一阵","太子","皇帝","不是","一句",\
"还是","拱手","公子","只有","然则","不禁","今日","说话",\
"战国","只是","正在","高声","变法","突然","知道","顿时",\
"特使","大将","一般","骤然","以为"}
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
for word in excludes:
del counts[word]
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(19):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
print("{0:<10}{1:>5}".format("韩国",1185)) #因韩国出现的次数太靠后,这里直接打印
结果截图:
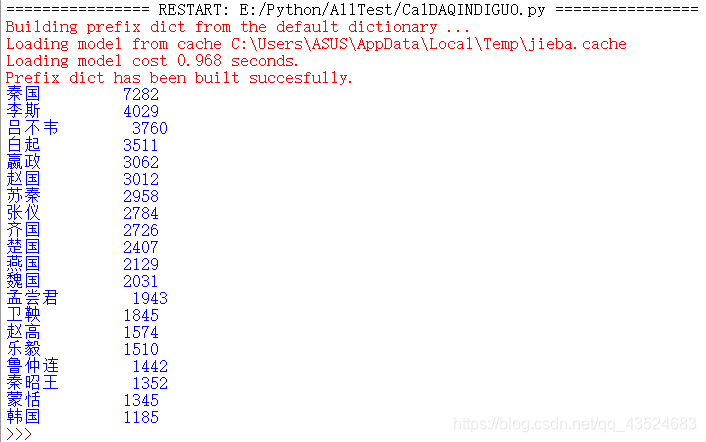
结果的小分析:
这里主要是分析词频出现在前面的人物,以及七大战国的出现次数。
从结果中也可以看出《大秦帝国》的主要内容是在写“秦国”,之后便是“赵国”,毕竟能与秦国在其极强盛的时期抗衡,史无前例的百万人的大战——“长平之战”也体现出两国的国立之强盛,秦灭六国时赵国也是最难啃的骨头。与之相对的韩国则从词频中亦看出其弱。
人物的出场在一开始的时候我本以为“商鞅”会出现很多次,却没想到不仅前面没有出现,而且取而代之的是“卫鞅”。
像李斯、吕不韦、赢政、赵高、蒙恬这样的人物排在前面,也体现出在《大秦帝国》泱泱五百万言中着重写的是大秦的形成前后这一段时期。
战国四大名将之首、武安君白起(杀敌皆以万记)排在前列也是毫无疑问的。
亦是,大秦总少不了纵横家两兄弟苏秦、张仪。
没想到的是,战国四大公子死的最早孟尝君出场竟然远超其他三位。
秦昭王即秦昭襄王 赢稷在位55年,是个人物。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









