









虚拟化与云计算
2022年9月13日
13:51
VMM
X86系统是完全运行在裸机上的。X86提供四个特权等级,分别是ring 0-1,ring 0 的级别是最高的。
在Linux+X86中,操作系统需要直接访问内存和硬件所以需要运行在ring0上,而应用程序需要运行在ring3上,如果需要进行访问磁盘、读写文件的操作,需要执行系统调用函数,执行系统在调用的时候,CPU运行级别从ring3 到ring0 并跳转到系统调用对应的内核代码位置执行,完成后从ring0到ring3,这个过程叫做用户态和内核态的切换。
此时host os是在ring0工作的,而guest OS不能在ring0了。但是它依旧执行之前的命令,却没有执行权限。此时VMM会避免发生这个事情。VM通过VMM实现guest CPU访问硬件:全虚拟化、半虚拟化、硬件辅助虚拟化。inter引入inter-VT技术,这种CPU ,有VMX root operation 和VMX non-root operation模式,都支持ring0-ring3的运行级别,VMM可以运行在VMX rootoperation ,guest OS在VMX non-root operation.
从root mode到nonroot mode叫做VMX-ENTER 反之叫做XMV-EXIT。KVM虚机在需要执行GUEST OS指令时将CPU转换到VMX non-root mode ,vmx-enter。KVM用户机代码是受到VMM控制,QUEM只是通过KVM控制虚机来执行,本身不执行代码,CPU没有被真正的虚拟化
• 内存虚拟化
KVM内存虚拟化共享物理系统的内存,动态分配。KVM中,虚机的物理内存为qume-kvm进程所占用的空间。KVM使用CPU辅助内存虚拟化的方式。
影子页表:宿主机不能直接装载客户机的页表进行内存访问,guest OS 访问内存时需要进行多次的地址转换,首先是把客户机的虚拟地址转换成物理地址,再是根据客户机物理地址与宿主机虚拟地址之间的映射进行转换,再是将宿主机的虚拟地址转换成物理地址.但是通过影子页表可以实现客户机虚拟地址到宿主机物理地址的直接转换。
Intel的CPU提供了扩展页表EPT技术,直接在硬件上支持GVA-GPA-HPA,。KVM为了个GVA到GPA的转换。但是guest OS无法直接访问实际内存,所有需要VMM映射内存到实际机器内存(GPA-HPA)。
• I/O虚拟化
服务器组件的系统和可用I/O处理单元之间的硬件中间件,让多个guest可以复用有限的外设资源。
模拟设备的寄存器和内存,截获guest os对IO端口和寄存器的访问,通过软件的方式模拟设备的行为。
可使用的设备大致分为了三类:
• 模拟设备:完全由QEMU纯软件模拟的设备
• Virtio设备:实现virtio api的半虚拟化设备
• PCI设备直接分配
I/O虚拟化需要发现设备,控制各个虚拟机可以访问的设备。访问截获:通过I/O端口活MMIO对设备进行访问,通过DMA与内存进行数据交换。
Vritio
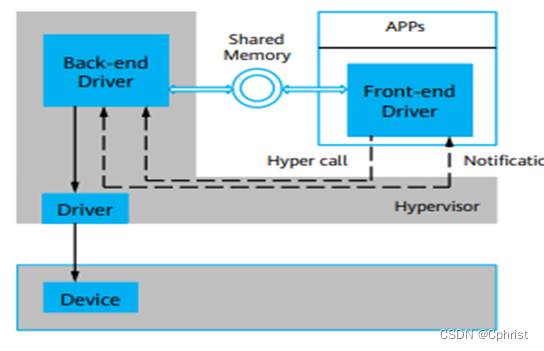
虚拟出特殊的设备-特殊的设备驱动,包括V中的front-end和back-end(前端驱动和后端驱动),两个驱动之间高效通信。
减少vm和主机的数据传输开销。
1.共享内存
2.batched I/O 批量IO
3.异步事件通知eventfd轻量级进程“等待/通知”
virtio半虚拟化设备实现了VIRTIO,减少了VM-Exit次数,提高了guest osI/O的执行效率。但是需要与virtio相关的驱动的支持,兼容性较差,并且I/O频繁时CPU的使用率较高。
主流的虚拟化技术
• XEN(对比ESX和HYPER-V,XEN支持更加广泛的CPU架构,前两个只支持CISC X86/X86-64 CPU架构,xen还支持RISC CPU架构)
xen的hypervisor是BIOS载入后的首个程序,是一个特殊的虚拟机称之为domain 0,对hypervisor进行控制和管理,其他虚拟机称之为domain U。Domain 0 是唯一可以直接访问物理硬件的虚拟机,通过本身加载的物理驱动,为其他虚拟机提供访问存储和网卡的桥梁。
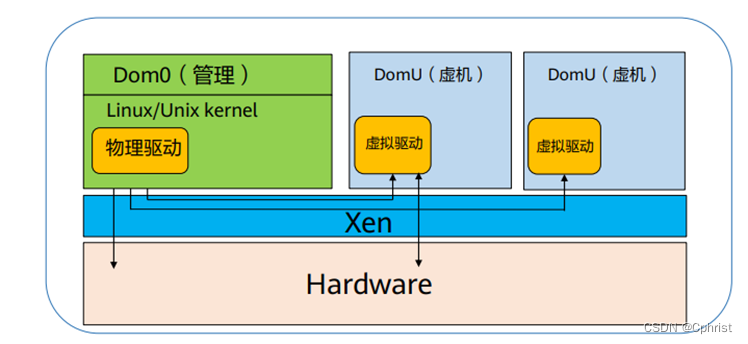
xen的半虚拟化不要求CPU具备硬件辅助虚拟化,全虚拟化要求CPU具有硬件辅助u虚拟化的功能。
与hyper-v类似的是hypervisor层非常的薄,不包含任何物理设备驱动,物理设备的驱动均在domain 0之中,可以重用现有的Linux设备驱动程序。
内存回收的三种技术

KVM
基于内核的虚拟机
本质是Linux内核中的虚拟化功能模块kvm.ko,利用Linux做大量的事情。
KVM中,虚拟机就是一个进程,由CPU进行调度。
KVM运行在内核空间,提供CPU、内存的虚拟化,本身并不执行任何的模拟,运行子用户空间的QEMU提供硬件虚拟化



XEN平台更侧重安全性(映射必须通过hypervisor授权)、KVM平台更侧重性能(无需授权,访问路径较短)














 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









