







MapReduce入门
一、回顾
-
HDFS架构
- 分布式
- 普通主从架构
- 主:管理
- 从:执行
- 公平架构
- 每个节点都是公平节点
- Zookeeper
- 普通主从架构
- 本质:将多台机器的文件系统从逻辑上合并为一个整体
- 节点
- NameNode:主:管理
- 管理集群:DataNode
- 管理接客
- 管理元数据
- DataNode:从:存储
- 每个DataNode负责管理自己所在节点的文件系统
- 负责接收NameNode的读写任务分配:数据写入DataNode所在的Linux文件系统的
- dfs.datanode.data.dir:决定了DataNode将数据存储在Linux的什么位置
- 元数据:记录了数据文件被拆分的每个部分【数据块】的存储信息
- 产生:格式化fsiamge
- 存在
- 磁盘:fsiamge
- dfs.namenode.name.dir
- 内存:NameNode每次会加载到内存
- NameNode每次读写内存元数据,只有内存元数据在发生变化
- 问题:如果NameNode故障,内存元数据丢失,重新加载本地,但是不一致?
- NameNode会将所有内存元数据的变化写入edits文件
- dfs.namenode.edits.dir
- 解决:每次NameNode启动将edits与fsiamge文件进行合并加载到内存
- NameNode会将所有内存元数据的变化写入edits文件
- 问题:edits文件越来越大,有很多过期的元数据,导致每次NameNode启动会很慢?
- 解决:SecondaryNameNode
- 功能:定期或者定量将edits文件与fsiamge文件合并生成新的fsimage文件
- 目的:减小edits文件的数据量,提高NameNode的合并速度
- 磁盘:fsiamge
- NameNode:主:管理
- 分布式
-
JavaAPI
-
如何构建连接
//用于管理Hadoop程序所有配置信息 Configuration conf = new Configuration(); conf.set("fs.defaultFS","hdfs://node1:8020") FileSyste hdfs = FileSystem.get(conf); -
常用方法
- mkdir
- delete
- exsits
- create
- open
-
-
Hadoop HA
-
问题:主节点单点故障
-
解决:Hadoop提供了HA方案,启动两个主节点
-
问题1:两个NameNode,谁工作,谁不工作的?
- 选举:利用zookeeper的临时节点和监听机制来实现辅助选举
- 原理
- 两个NameNode都到Zookeeper创建同一个临时节点,谁创建成功,谁就是Active
- Standby的NameNode会对这个临时节点设置监听,如果临时节点消失,表示ActiveNameNode故障
- Standby会创建临时节点,成为Active状态
- 实现:ZKFC
- 功能一:负责监听NameNode以及实现切换
- 功能二:负责帮NameNode连接Zookeeper
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-REtf0bDW-1615044933716)(Day06_MapReduce入门.assets/image-20201030095511604.png)]
-
问题2:NameNode功能的问题
- 管理集群
- 所有DataNode会向所有NameNode注册并且发送报告
- 接客
- 客户端挨个请求,最终请求提交给Active的NameNode
- 管理元数据:如何保证两个NameNode的元数据是一致的
- 解决:共享edits文件
- Active:元数据变化写入edits
- Standby:读edits对自己元数据修改即可
- Journalnode:非常类似于Zookeeper
- 功能:共享存储edits
- 区别:没有文件大小的存储限制
- 理解:这是一种特殊的Zookeeper的集群
- 解决:共享edits文件
- 管理集群
-
HA架构中没有SecondaryNameNode
- StandBy的NameNode接替了SecondaryNameNode的功能
- 将读取的edits与自己的fsiamge定期合并,生成新的fsiamge,将新的fsimage发给Active一份
-
-
问题
-
脑裂问题:同时出现了两个Active的NameNode
-
正常情况
- A和B
- 第一次:A的ZKFC1创建临时节点file1,创建成功,A就是Active
- B是Standby,B的ZKFC2要监听这个临时节点file1
- 第二次
- 如果A故障,ZKFC1发现A故障,主动删除file1,file1消失
- zkfc2收到监听的通知,知道file1被删除,zkfc2创建了file1
- B成了为Active状态
-
特殊情况
-
A和B
-
第一次:A的ZKFC1创建临时节点file1,创建成功,A就是Active
- B是Standby,B的ZKFC2要监听这个临时节点file1
-
第二次
- 如果zkfc1故障,连接断开,file1被自动删除
- 如果file1消失,zkfc2收到监听的通知,知道file1被删除,zkfc2创建了file1
- B成了为Active状态,A依旧是Active
- 出现了两个Active的状态
-
解决
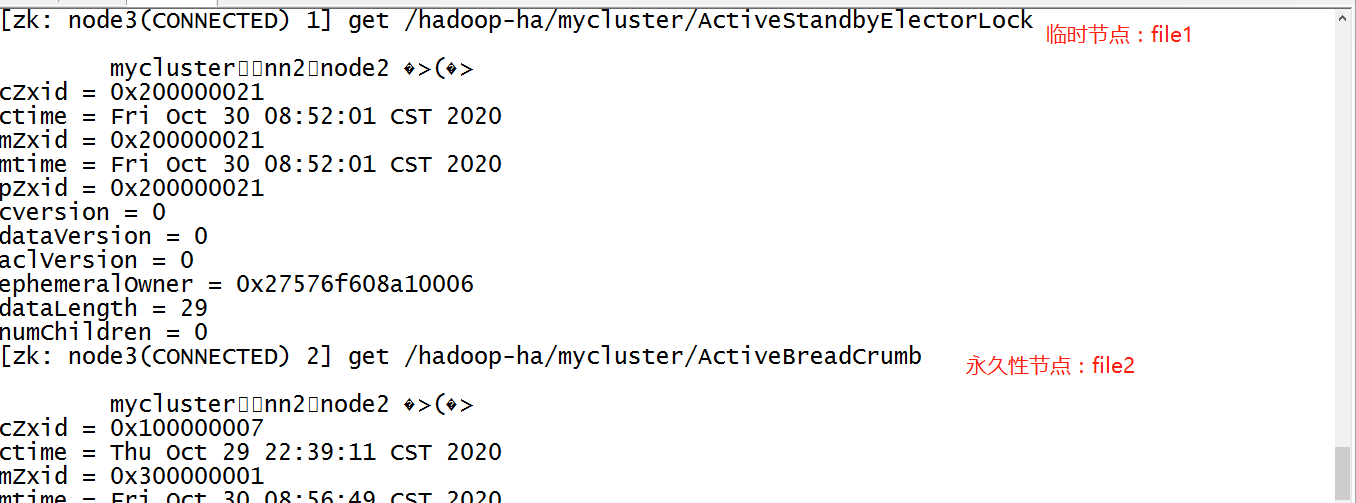
- A和B
- 第一次:A的ZKFC1创建临时节点file1,创建成功,A就是Active
- ZKFC1创建永久性节点file2
- B是Standby,B的ZKFC2要监听这个临时节点file1
- 第二次
- 如果zkfc1故障,连接断开,file1被自动删除
- 如果file1消失,zkfc2收到监听的通知,知道file1被删除,zkfc2创建了file1
- B成了为Active状态,A依旧是Active
- ZKFC2同时会发现file2已存在,说明是zkfc1故障了,说明A还是Active状态
- ZKFC2会通过隔离机制到A所在的节点上,强转切换为Standby,如果切换不成功,强制kill掉A
-
-
-
客户端配置
- HA模式下,如果自己写代码,代码中怎么配置服务端地址?
- 方式一:将core-site.xml和hdfs-site.xml放入resources目录中
- 方式二:将core-site.xml和hdfs-site.xml中所有的属性在conf中设置
- 以后只要是HA模式,任何一种客户端要访问HDFS,都必须获取这两个配置文件
-
反馈
- 建议下课期间问上课记录的问题
- ZK架构及存储的数据
- ZK会存储哪些数据?
- 由我们自己决定
- ZK架构:公平节点
- 主节点和从节点存储的数据是一致的
- 主节点和从节点都能接受客户端请求
- 从节点有资格被选举为主节点的
- 区别:只有主节点能实现写入操作
- ZK会存储哪些数据?
- 配置
- xxx-env.sh:修改环境变量的
- hadoop-env
- mapred-env
- yarn-env
- ||
- JDK路径
- xxx-site.xml:配置属性
- core-site.xml:用于自定义Hadoop全局配置
- core-default.xml
- fs.defaultFS
- hadoop.tmp.dir
- hdfs-site.xml:用于自定义HDFS属性配置
- hdfs-default.xml
- mapred-site.xml:用于自定义MapReduce属性配置
- mapred-default. xml
- yarn-site.xml:自定义YARN属性的配置
- yarn-default.xml
- core-site.xml:用于自定义Hadoop全局配置
- slaves:用于配置从节点的地址的
- DataNode
- NodeManager
- NameNode地址:core-site
- ResourceManager:yarn-site:yarn.resourcemanager.hostname
- 问题:为什么一台机器既是DataNode也是NodeManager?
- 优先本地计算
- Hadoop中如何管理配置?
- Congratulation:用于管理Hadoop所有属性配置
- step1:加载default文件,所有默认配置
- step2:加载site文件,用用户自定义配置覆盖默认配置
- xxx-env.sh:修改环境变量的
- 熟练度
- 理论:猜别人是怎么想的,思考为什么这么设计
- 问,背
- 操作:死的
- 通过操作来验证理论
- 命令、API
- 多练习
- 当天自己能写出来就可以,休息那天,多敲几遍
- 理论:猜别人是怎么想的,思考为什么这么设计
-
二、课程目标
- MapReduce的功能以及应用场景
- 基本理论【重要】
- MapReduce如何实现数据分布式处理:五大阶段【核心】
- MapReduce编程规则
- 开发案例【掌握基本开发】
- WordCount
- 二手房的统计分析
三、MapReudce编程模型
1、功能
- 分布式计算
- step1:先开发一个分布式【多进程】程序
- step2:需要一个分布式资源环境
- 只有分布式程序放在分布式的资源环境中运行:分布式计算
- MapReduce:就是一套分布式编程的API
- 只要基于MapReduce的API进行编程,就可以直接开发出一个分布式程序
- MapReduce底层会自动将任务逻辑进行拆分成多个小的任务
- 需求:1 + ……+9
- 拆分:逻辑上拆分了进程
- Task1:1+2+3
- Task2:4+5+6
- Task3:7+8+9
- Task4:6+15+24 = 45
- YARN:提供分布式资源环境,分布式资源管理和任务调度平台
- node1:Task1
- node2:Task2
- node3:Task3 Task4
2、思想和应用场景
-
设计:分布式编程模型
- 分而治之
- step1:将一个大的计算任务拆分成多个小的计算任务
- step2:将每个小的计算任务交给不同的机器来并行执行
- step3:将每个小任务的结果进行合并
-
应用
-
设计:让分布式计算应用于廉价的机器上:配置比较低的机器
- 使用了大量的磁盘机制
-
离线分布式大数据计算
-
不适合处理小数据
-
3、阶段:基本原理
-
正常一个计算处理数据的程序的步骤
- step1:读取输入数据
- step2:处理输出数据
- step3:输出处理结果
-
MapReduce的阶段划分
- Map阶段
- Reduce阶段
-
MapReduce的五大阶段
-
Input:负责整个程序的输入
-
功能:根据代码中定义的输入,读取对应的数据内容
-
功能一:将读取到的数据根据分的规则,划分为多个分片:Split
- 类似于:1到9有9个数字
- 将1到9的9个数字划分为3个部分
- 类似于:1到9有9个数字
-
功能二:将每个Split中的每一条数据变成一个KV对
- K1
- V1
a 1 a 2 a 3 a 4 a 5 a 6 a 7 a 8 a 9
-
-
-
Map:负责任务的划分的
-
功能:根据Input阶段划分的Split来划分MapTask任务进程
-
一个Split = 一个MapTask进程
-
任务的划分
-
MapTask1
a 1 a 2 a 3 -
MapTask2
a 4 a 5 a 6 -
MapTask3
a 7 a 8 a 9
-
-
-
处理:每个MapTask会调用Map类的map方法来对自己负责的每一条数据处理一次
-
map方法处理的逻辑:由用户自定义
public void map (K1,V1){ 由用户自己决定 }
-
-
输出:
- K2
- V2
-
-
Shuffle:分组和排序
- 分组:按照K2进行分组
- 相同K2的V2会放入同一个迭代器中
- 分组:按照K2进行分组
-
排序:按照K2进行排序
- 目的:加快分组
-
输出
- K2 Iter<K2对应的所有V2>
-
Reduce:将Map输出的所有数据在分组排序以后进行聚合,默认只会启动一个ReduceTask
-
聚合逻辑:ReduceTask会调用reduce方法进行聚合
public void reduce(K2,iter){ 由用户自定义 }
-
-
输出
- K3
- V3
- K3
-
Output:负责整个程序的输出,将结果进行保存
- 将K3,V3根据输出的方法进行保存
-
4、词频统计的分析
-
Input
-
输入
hadoop hive hbase hadoop hive spark hbase hadoop -
功能
- 将数据切分
- 将每一条数据转换为一个KV
- 由输入的类决定:TextInputFormat,默认的输入类
- K1:行的偏移量:这个东西没用
- V1:行的内容
-
输出
K1 V1 0 hadoop hive hbase 23 hadoop hive 32 spark hbase hadoop
-
-
Map
-
处理:每一个K1V1调用一次map方法
-
map方法
public void map(K1,V1){ String[] words = v1.split(" "); for(String word : words){ K2:word V2:1 } } -
输出
- K2:单词
- V2:1
K2 V2 hadoop 1 hive 1 hbase 1 hadoop 1 hive 1 spark 1 hbase 1 hadoop 1
-
-
Shuffle
-
排序:按照K2排序
-
分组:按照K2分组,相同K2对应的V2放入同一个迭代器
-
输出
hadoop <1,1,1> hbase <1,1> hive <1,1> spark <1>
-
-
Reduce
-
处理:每一组数据【每一种K2】调用一次reduce方法
-
reduce方法
public void reduce(K2,iter:values){ for(value:values){ sum += value } K3:K2 V3:sum } -
输出
- K3
- V3
-
-
Output
hadoop 3 hbase 2 hive 2 spark 1
四、MapReduce编程规则
1、Driver类
- 用于运行程序的类,包含main方法,作为程序运行的入口
- 官方推荐:继承 Configured 实现 Tool
- 实现run方法
- main:作为程序的入口,负责调用run方法
- run:构建、配置、提交运行MapReduce的Job
- 这个类要自己写
2、Input类
- 负责整个程序的输入,由输入类决定:InputFormat
- 了解基本的三个子类:不同的子类用于读取不同的数据
- TextInputFormat:用于读取文件的类,MapReduce中默认的输入类
- DBInputFormat:用于读取MySQL数据库的数据
- Sqoop:将MySQL数据与HDFS之间实现导入导出
- TableInputFormat:用于读取Hbase的数据
- TextInputFormat:默认会读取fs.defaultFS对应的文件系统中的文件
- 将文件拆分为分片
- 将文件中的每一行变成一个KV
- K1:行的偏移量
- V1:行的内容
- 这个类不用自己写
3、Mapper类
- 在Map阶段,每一个MapTask会构建一个Mapper类的实例
- Mapper类会包含map方法,MapTask会对每一条K1V1调用一次map方法
- map方法的处理逻辑:由用户自定义
- 规则:继承Mapper,重写map方法
4、Reducer类
- 在Reduce阶段,每一个ReduceTask会构建一个Reducer类实例,调用reduce方法
- Reduce类包含reduce方法
- reduce方法的处理逻辑:由用户自定义
- 规则:继承Reducer类,重写reduce方法
5、Output类
- 负责整个程序的输出,由输出类:OutputFormat
- 了解常见的输出类
- TextOutputFormat:默认将结果保存到文件中,MapReduce默认的输出类
- DBOutputFormat:用于将结果保存到MySQL数据库中
- TableOutputFormat:将结果保存到Hbase中
- TextOutputFormat:将Reduce的结果K3,V3保存到文件系统中
- K3与V3之间使用制表符分隔
- 这个不用自己写
6、数据结构
- 整个MapReduce在处理数据的时候,所有的数据都是以KV形式存在的
7、数据类型
- 所有的分布式中:Hadoop中必须使用支持序列化的数据类型
- Java中常用类型:String,int,long,double
- 不支持序列化
- MapReduce中提供了对应的支持序列化类型
- Text(字符串类型)
- IntWritable
- LongWritable
- DoubleWritable
- BooleanWritable
- NullWritable
五、MapReduce编程模板
1、Driver
package bigdata.itcast.cn.hadoop.mapreduce.mode;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @ClassName MapReduceDriver
* @Description TODO Mapreduce模板的Driver
* 规则:继承Configured 实现 Tool
* 方法:
* main:作为程序运行的入口,调用run方法
* run:构建、配置、提交运行一个Mapreduce的Job
* @Date 2020/10/30 15:34
* @Create By Frank
*/
public class MapReduceDriver extends Configured implements Tool {
/**
* 构建job
* 配置Job:读哪个文件,将结果保存到什么地方去呀;
* 提交Job
* @param args
* @return
* @throws Exception
*/
public int run(String[] args) throws Exception {
/**
* todo:1-构建一个Mapreduce的Job
*/
Job job = Job.getInstance(this.getConf(),"mode");//加载配置,以及定义job的名称
job.setJarByClass(MapReduceDriver.class);//指定当前类可以通过jar包运行
/**
* todo:2-配置Mapreduce的五大阶段
*/
//Input
// job.setInputFormatClass(TextInputFormat.class);//指定输入类,默认类就是TextInputFormat,如果需要更改,需要写
//添加读取的文件路径
Path inputPath = new Path(args[0]);//用整个程序的第一个参数来作为输入
TextInputFormat.setInputPaths(job,inputPath);//设置输入要读取的文件路径
//Map
job.setMapperClass(null);//指定Mapper类
job.setMapOutputKeyClass(null);//指定Map阶段输出的Key的类型,K2的类型
job.setMapOutputValueClass(null);//指定Map阶段输出的Value的类型,V2的类型
//Shuffle
// job.setGroupingComparatorClass(null);
// job.setSortComparatorClass(null);
// job.setPartitionerClass(null);
// job.setCombinerClass(null);
//Reduce
job.setReducerClass(null);//设置Reduce类
job.setOutputKeyClass(null);//设置Reduce输出的Key的类型,就是K3
job.setOutputValueClass(null);//设置Reduce输出的Value的类型,就是V3
// job.setNumReduceTasks(1);//设置reduceTask的个数,默认为1
//Output
// job.setOutputFormatClass(TextOutputFormat.class);//指定输出类,默认类就是TextOutputFormat
Path outputPath = new Path(args[1]);//用整个程序的第二个参数来作为输出
TextOutputFormat.setOutputPath(job,outputPath);//设置输出保存结果的路径
/**
* todo:3-提交Mapreduce的Job,运行
*/
//提交运行,返回boolean值,如果为true,表示运行成功了,返回false,表示运行失败了
return job.waitForCompletion(true) ? 0 : -1;
}
/**
* 作为程序入口,调用run方法
* @param args
*/
public static void main(String[] args) throws Exception {
//构建一个Configuration对象;管理当前hadoop程序的配置
Configuration conf = new Configuration();
//通过Hadoop的工具类来调用当前类的run方法;第二个参数:非静态方法需要用对象去调用
//如果结果返回的是0则表示运行成功
int status = ToolRunner.run(conf, new MapReduceDriver(), args);
//根据运行的状态退出程序
System.exit(status);
}
}
运行的时候可以通过args传递参数

2、Mapper
package bigdata.itcast.cn.hadoop.mapreduce.mode;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @ClassName MapReduceMapper
* @Description TODO Mapreduce模板的Mapper类
* r<KEYIN, VALUEIN, :Map输入的KV类型,K1,V1的类型
* 由Input决定
* KEYOUT, VALUEOUT>:Map输出的KV类型,K2,V2的类型
* 由map方法决定
* @Date 2020/10/30 16:09
* @Create By Frank
*/
public class MapReduceMapper extends Mapper<LongWritable, Text,Text,Text> {
/**
* 每一条K1V1调用一次
* @param key:就是K1
* @param value:就是V1
* @param context:上下文对象,用于实现上下文数据的传递的
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**
* 处理逻辑由用户自己决定
*/
}
}
3、Reducer
package bigdata.itcast.cn.hadoop.mapreduce.mode;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @ClassName MapReduceReducer
* @Description TODO Mapreduce编程模板的Reducer类
* r<KEYIN, VALUEIN, :Reduce输入的KV类型,K2,V2的类型
* 由map方法决定
* KEYOUT, VALUEOUT>:Reduce从输出的KV类型,K3,V3的类型
* 由reduce方法决定
* @Date 2020/10/30 16:13
* @Create By Frank
*/
public class MapReduceReducer extends Reducer<Text, Text,Text,Text> {
/**
* 每一组数据调用一次reduce方法
* @param key:K2
* @param values:相同K2对应的V2的迭代器
* @param context:上下文对象
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
/**
* 处理逻辑由用户自己决定
*/
}
}
4、一个文件中定义
package bigdata.itcast.cn.hadoop.mapreduce.mode;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* @ClassName MapReduceDriver
* @Description TODO Mapreduce模板,三个类在一个文件中,Map类和Reduce类必须为static修饰
* 规则:继承Configured 实现 Tool
* 方法:
* main:作为程序运行的入口,调用run方法
* run:构建、配置、提交运行一个Mapreduce的Job
* @Date 2020/10/30 15:34
* @Create By Frank
*/
public class MapReduceMode extends Configured implements Tool {
/**
* 构建job
* 配置Job
* 提交Job
* @param args
* @return
* @throws Exception
*/
public int run(String[] args) throws Exception {
/**
* todo:1-构建一个Mapreduce的Job
*/
Job job = Job.getInstance(this.getConf(),"mode");//加载配置,以及定义job的名称
job.setJarByClass(MapReduceMode.class);//指定当前类可以通过jar包运行
/**
* todo:2-配置Mapreduce的五大阶段
*/
//Input
// job.setInputFormatClass(TextInputFormat.class);//指定输入类,默认类就是TextInputFormat,如果需要更改,需要写
//添加读取的文件路径
Path inputPath = new Path(args[0]);//用整个程序的第一个参数来作为输入
TextInputFormat.setInputPaths(job,inputPath);//设置输入要读取的文件路径
//Map
job.setMapperClass(MrMapper.class);//指定Mapper类
job.setMapOutputKeyClass(Text.class);//指定Map阶段输出的Key的类型,K2的类型
job.setMapOutputValueClass(Text.class);//指定Map阶段输出的Value的类型,V2的类型
//Shuffle
// job.setGroupingComparatorClass(null);
// job.setSortComparatorClass(null);
// job.setPartitionerClass(null);
// job.setCombinerClass(null);
//Reduce
job.setReducerClass(MrReduce.class);//设置Reduce类
job.setOutputKeyClass(Text.class);//设置Reduce输出的Key的类型,就是K3
job.setOutputValueClass(Text.class);//设置Reduce输出的Value的类型,就是V3
// job.setNumReduceTasks(1);//设置reduceTask的个数,默认为1
//Output
// job.setOutputFormatClass(TextOutputFormat.class);//指定输出类,默认类就是TextOutputFormat
Path outputPath = new Path(args[1]);//用整个程序的第二个参数来作为输出
TextOutputFormat.setOutputPath(job,outputPath);//设置输出保存结果的路径
/**
* todo:3-提交Mapreduce的Job,运行
*/
//提交运行,返回boolean值,如果为true,表示运行成功了,返回false,表示运行失败了
return job.waitForCompletion(true) ? 0 : -1;
}
/**
* 作为程序入口,调用run方法
* @param args
*/
public static void main(String[] args) throws Exception {
//构建一个Configuration对象
Configuration conf = new Configuration();
//通过Hadoop的工具类来调用当前类的run方法
int status = ToolRunner.run(conf, new MapReduceMode(), args);
//根据运行的状态退出程序
System.exit(status);
}
//Mapper类
public static class MrMapper extends Mapper<LongWritable, Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
}
}
//Reducer
public static class MrReduce extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
}
}
}
六、MapReduce实现WordCount
1、需求
- 通过自己开发wordcount程序实现词频统计
2、分析
- 参考三.4
3、实现
package bigdata.itcast.cn.hadoop.mapreduce.wordcount;
import org.apache.curator.framework.recipes.locks.InterProcessReadWriteLock;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* @ClassName WordCountMr
* @Description TODO 自定义开发实现wordcount程序
* @Date 2020/10/30 16:36
* @Create By Frank
*/
public class WordCountMr extends Configured implements Tool {
//构建,配置,提交
public int run(String[] args) throws Exception {
//todo:1-构建
Job job = Job.getInstance(this.getConf(),"userwc");
job.setJarByClass(WordCountMr.class);
//todo:2-配置
//input
Path inputPath = new Path(args[0]);
TextInputFormat.setInputPaths(job,inputPath);
//map
job.setMapperClass(WcMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reduce
job.setReducerClass(WcReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//output
Path outputPath = new Path(args[1]);
TextOutputFormat.setOutputPath(job,outputPath);
//todo:3-提交
return job.waitForCompletion(true) ? 0:-1;
}
//作为程序入口,负责调用run方法
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WordCountMr(), args);
System.exit(status);
}
public static class WcMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
//定义输出的Key:单词
Text outputKey = new Text();
//定义输出的Value:恒为1
IntWritable outputValue = new IntWritable(1);
/**
* 每一条数据会调用一次map方法
* @param key:K1,行的偏移量
* @param value:V1:行的内容
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将每一行的内容进行分割,得到每个单词
String[] words = value.toString().split(" ");
//遍历取出每个单词
for (String word : words) {
//将单词作为Key
this.outputKey.set(word);
//输出:write方法用于将新的KV输出到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
public static class WcReducer extends Reducer<Text, IntWritable,Text, IntWritable>{
//定义输出的Value
IntWritable outputValue = new IntWritable();
/**
* 每一组调用一次reduce方法
* @param key:单词
* @param values:同一个单词对应的所有value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
//将单词出现的次数赋值给value
this.outputValue.set(sum);
//输出
context.write(key,this.outputValue);
}
}
}
4、集群运行:生产
- 打成jar包,上传到Linux上
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iK4Ndp4v-1615044933721)(Day06_MapReduce入门.assets/image-20201030170025570.png)]
-
通过yarn运行
yarn jar /export/data/wordcount.jar bigdata.itcast.cn.hadoop.mapreduce.wordcount.WordCountMr /wordcount/input/wordcount.txt /wordcount/output3
5、本地运行
- Mapreduce直接在本地启动一个JVM来运行代码,没有YARN
- 一般用于测试开发
- 直接在本地运行
package bigdata.itcast.cn.hadoop.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* @ClassName WordCountMr
* @Description TODO 自定义开发实现wordcount程序
* @Date 2020/10/30 16:36
* @Create By Frank
*/
public class WordCountLocal extends Configured implements Tool {
//构建,配置,提交
public int run(String[] args) throws Exception {
//todo:1-构建
Job job = Job.getInstance(this.getConf(),"userwc");
job.setJarByClass(WordCountLocal.class);
//todo:2-配置
//input
Path inputPath = new Path("D:\\IDEAProject\\SHBigdata\\datas\\wordcount\\wordcount.txt");
TextInputFormat.setInputPaths(job,inputPath);
//map
job.setMapperClass(WcMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reduce
job.setReducerClass(WcReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//output
Path outputPath = new Path("datas/output/wc/output1");
TextOutputFormat.setOutputPath(job,outputPath);
//todo:3-提交
return job.waitForCompletion(true) ? 0:-1;
}
//作为程序入口,负责调用run方法
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new WordCountLocal(), args);
System.exit(status);
}
public static class WcMapper extends Mapper<LongWritable, Text,Text, IntWritable>{
//定义输出的Key:单词
Text outputKey = new Text();
//定义输出的Value:恒为1
IntWritable outputValue = new IntWritable(1);
/**
* 每一条数据会调用一次map方法
* @param key:K1,行的偏移量
* @param value:V1:行的内容
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将每一行的内容进行分割,得到每个单词
String[] words = value.toString().split(" ");
//遍历取出每个单词
for (String word : words) {
//将单词作为Key
this.outputKey.set(word);
//输出:write方法用于将新的KV输出到下一步
context.write(this.outputKey,this.outputValue);
}
}
}
public static class WcReducer extends Reducer<Text, IntWritable,Text, IntWritable>{
//定义输出的Value
IntWritable outputValue = new IntWritable();
/**
* 每一组调用一次reduce方法
* @param key:单词
* @param values:同一个单词对应的所有value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
//将单词出现的次数赋值给value
this.outputValue.set(sum);
//输出
context.write(key,this.outputValue);
}
}
}
七、MapReduce实现二手房统计
1、需求
- 统计每个地区二手房的个数
2、分析
梅园六街坊,2室0厅,47.72,浦东,低区/6层,朝南,500,104777,1992年建
-
结果
地区 个数 浦东 100 虹口 200 闵行 徐汇 …… -
有没有分组?
- 按照地区分组
- K2:地区
- V2:1
3、实现
4、练习
- 基于二手房数据统计每个地区二手房的平均单价
附录一:MapReduce编程依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
</dependencies>















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











