







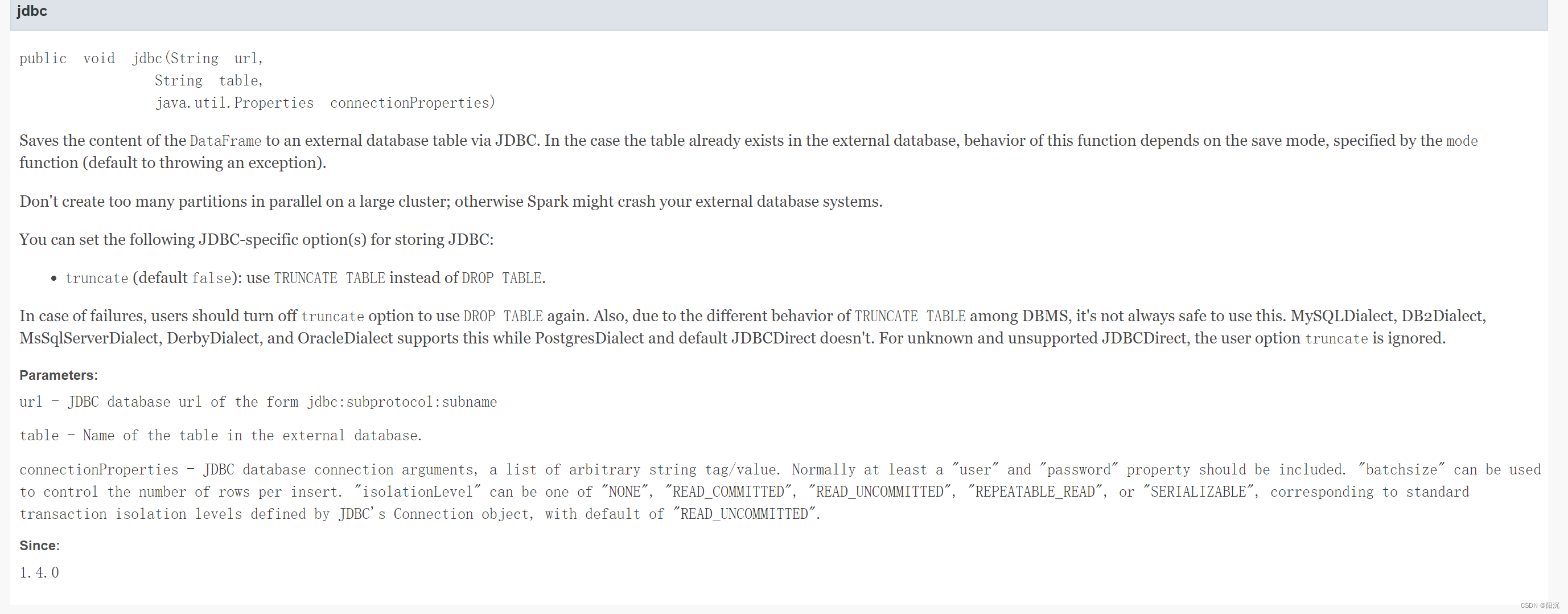
Spark jdbc mode=overwrite保留table原结构
使用mode为overwrite,设置truncate=True,可以将overwrite的drop table操作改为truncate table操作,保留表结构。
参考文档
官方文档:https://spark.apache.org/docs/2.4.5/api/java/org/apache/spark/sql/DataFrameWriter.html#jdbc-java.lang.String-java.lang.String-java.util.Properties-
示例
注:示例为python代码
result_df.write.mode(saveMode="overwrite") \
.format("jdbc") \
.option("truncate",True) \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "url" ) \
.option("useSSL", "false") \
.option("user", "df") \
.option("password", "sdfgsd") \
.option("batchsize", 5000) \
.option("dbtable", table) \
.option("isolationLevel", "NONE") \
.save()















 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









